MAVEN-ERE一个新的事件关系检测数据集
MAVEN-ERE: A Unified Large-scale Dataset for Event Coreference,Temporal, Causal, and Subevent Relation Extraction

code:THU-KEG/MAVEN-ERE: Source code and dataset for EMNLP 2022 paper “MAVEN-ERE: A Unified Large-scale Dataset for Event Coreference, Temporal, Causal, and Subevent Relation Extraction”. (github.com)
paper:[2211.07342] MAVEN-ERE: A Unified Large-scale Dataset for Event Coreference, Temporal, Causal, and Subevent Relation Extraction (arxiv.org)
期刊/会议:EMNLP 2022
摘要
真实世界事件之间的各种关系,包括共指、时间、因果和子事件关系,是理解自然语言的基础。然而,现有数据集的两个缺点限制了事件关系抽取(ERE)任务:(1)规模小。由于标注的复杂性,现有数据集的数据规模有限,无法很好地训练和评估数据饥饿模型。(2) 缺少统一标注。不同类型的事件关系自然地彼此交互,但现有数据集一次只覆盖有限的关系类型,这使得模型无法充分利用关系交互。为了解决这些问题,我们使用改进的标注方案构建了一个统一的大规模人类标注ERE数据集MAVEN-ERE。它包含103193个事件共指链、1216217个时间关系、57992个因果关系和15841个子事件关系,比所有ERE任务的现有数据集至少大一个数量级。实验表明,MAVEN-ERE上的ERE非常具有挑战性,考虑关系交互和联合学习可以提高性能。
1、简介
交流事件是人类语言的核心功能,理解事件之间的复杂关系对于理解事件至关重要。因此时间关系抽取任务包含了抽取事件共指、时间、因果和子事件关系,是自然语言处理(NLP)的基本挑战,也支持各种应用。
由于广泛认知的重要性,许多人致力于开发先进的ERE方法。最近,数据驱动的神经模型已成为ERE方法的主流。然而,这些数据驱动方法受到现有事件关系数据集的两个缺点的严重限制:(1)数据规模小。由于固有的高标注复杂性,现有人类标注数据集的数据规模有限。从表1所示的统计数据中,我们可以看到现有的流行数据集仅包含数百个文档和有限数量的关系,无法充分涵盖各种事件语义和不足以训练复杂的神经模型。此外,这些数据集中的事件关系往往不全面。例如,TB-Dense和MATRES仅标注相邻句子中事件对的事件时间关系。(2)缺乏统一的标注。自然,各种类型的事件关系之间有着丰富的交互作用。例如,原因事件必须在时间上先于效果事件开始,而超级事件必须在在时间上包含子事件。共指关系是基础,所有其他关系在共指事件提及之间共享。然而,如表1所示,现有数据集通常一次只覆盖有限的关系类型。RED是开发全面统一标注指南的一个显著例外,但由于其规模较小,只能用作测试集。这导致紧密相连的ERE任务传统上被独立处理,并限制了联合ERE方法的发展。
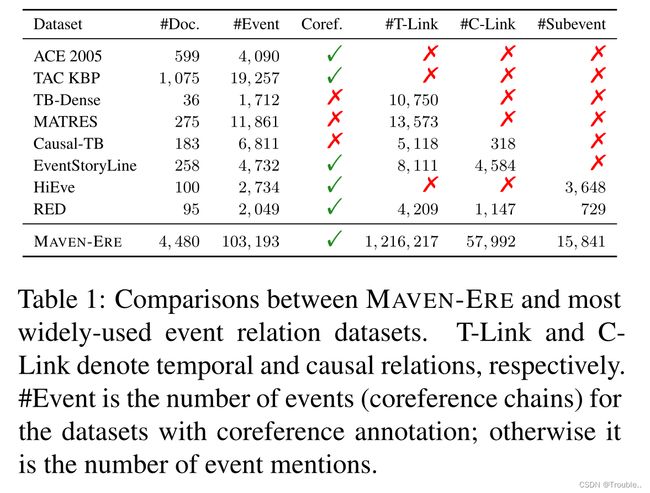
在本文中,我们基于先前的MAVEN数据集构建了MAVEN-ERE,这是第一个统一的大规模事件关系数据集,该数据集是一个大规模的通用领域事件检测数据集,涵盖4800个英语维基百科文档和168个细粒度事件类型。如图1所示,MAVEN-ERE通过在同一文档中标注4种事件关系来弥补统一标注的缺失。MAVEN-ERE有103193个事件共指链、1216217个时间关系、57992个因果关系和15841个子事件关系。据我们所知,MAVEN-ERE实现了第一个百万规模的人类标注ERE数据集。如表1所示,在每个ERE任务中,MAVEN-ERE比现有数据集至少大一个数量级,这将减轻数据规模的限制,并有助于开发ERE方法。

如图1所示,事件关系密集而复杂。因此,构建MAVEN-ERE需要彻底而费力的标注。为了确保可承受的时间和资源成本,我们进一步基于O’Gorman等人开发了一种新的标注方法,这是支持所有关系类型的唯一现有标注方案。具体来说,我们将整个标注任务分解为多个顺序阶段,这减少了标注者的能力要求。后续阶段的开销也可以通过前面阶段的结果来减少。首先,我们标注共引用关系,以便后期标注只需要考虑所有共引用事件中的一个。对于时间关系标注,我们开发了一种新的时间线标注方案,它避免了像以前的作品一样费力地识别每个事件对的时间关系。这个新方案带来了更加密集的标注结果。对于每100个单词,MAVEN-ERE的时间关系数量是之前使用最广泛的数据集MATRES的6倍多。对于因果关系和子事件关系标注,我们使用时间关系和关系传递性设置标注约束,以减少标注范围。
我们基于广泛使用的复杂预训练语言模型,为MAVEN-ERE开发了强大的基线。实验表明:(1)ERE任务具有相当大的挑战性,所取得的成绩远没有达到预期;(2) 我们的大规模数据充分训练了模型,并带来了性能优势;(3)考虑到直接联合训练的关系交互会提高效果,这鼓励更多的探索。我们还提供了一些实证分析,以启发未来的工作。
2、数据构建
基于MAVEN中的事件触发器,我们标注了四个ERE任务的数据:提取事件共指、时间、因果和子事件关系。对于每项任务,我们介绍了MAVEN-ERE的定义、标注过程和基本统计数据,并与现有的典型数据集进行了比较。有关总体统计比较,请参阅附录A。
2.1 共指关系
任务描述:事件共引用解析需要识别引用同一事件的事件引用。事件提及是表达事件发生的关键文本。例如,在图1中,“Battle of Sulatnabad”和后来的“battle”是指同一个真实世界事件的两个事件,因此它们具有共指关系。与实体共指解析一样,事件共指解析对各种应用都很重要,并且被广泛认为更具挑战性。
标注:我们遵循O’Gorman等人的标注指南,邀请29位标注人标注事件共指关系。标注者都经过了培训,并在标注前通过了资格测试。给定文档和突出显示的事件提及,标注器需要将共同引用的提及分组在一起。输出是事件共引用链,每个链接一组不同的事件提及。每个文件都由3名独立的标注者进行标注,最终结果通过多数投票获得。为了提高原始MAVEN之上的数据质量并避免标注模糊,如果提供的提及不表示事件,我们允许标注者报告,并且我们将删除所有标注者报告的提及。每对标注结果之间的B-Cubed F1平均为91%,这表明标注一致性令人满意。
统计:在标注之后,我们总共获得了103193个事件共引用链。在表2中,我们将MAVEN-ERE的大小与现有广泛使用的数据集(包括ACE 2005,ECB+,TAC KBP)进行了比较。我们可以看到,MAVEN-ERE有更多标注的事件共引用链,这将有利于事件共指消解方法。

2.2 时序关系
任务描述:时间关系提取旨在提取事件和时间表达式(TIMEX)之间的时间关系。TIMEX是文本中对时间的明确引用。在时间关系提取中考虑它们有助于将相对时间顺序锚定到具体的时间戳。因此,我们需要在标注时间关系之前标注TIMEX。
根据ISO TimeML标准,我们标注了四种类型的TIMEX:DATE、TIME、DURATION和PREPOSTEEXP,但我们忽略了QUANTIFIER和SET,因为它们对众包工作人员来说比较困难,对将事件与真实世界时间戳联系起来也没有太大帮助。对于时间关系,我们遵循O’Gorman等人,并全面设置了6种类型的时间关系:BEFORE、CONTAINS、OVERLAP、BEGINS-ON、ENDS-ON、SIMULTANIUS。除了SIMULTANIUS和BEGINS-ON之外,关系类型是单向的,即在关系实例中,头事件必须在尾事件之前开始。
标注:在TIMEX标注中,我们邀请了112名训练有素的合格标注员。每个文件都由3名标注者进行标注,最终结果通过多数投票获得。标注者之间的平均一致性为78.4%。
先前的工作表明,标注时间关系非常具有挑战性,因为密集标注每个事件对的关系非常耗时,并且时间关系的表达通常很模糊。因此,我们根据Ning等人的多轴方案和Reimers等人的时间锚定方案设计了一个复杂的标注方案。如图1(c)所示,我们要求标注器在时间线上对事件和TIMEX的开始和结束进行排序,而不是为每个事件对标识关系。因此,标注者只需要考虑如何安排时间上接近的事件和TIMEX的边界点,并且可以从它们的相对位置自动推断出时间轴上事件与TIMEX之间的关系。然而,由于叙事的模糊性,一些事件之间的时间关系无法从上下文中明确确定,例如图1中的“机动”和“攻击”,这通常发生在表达意见、意图和假设时。在这些情况下,我们允许标注者创建子时间线,我们将不同时间线上的事件视为没有时间关系。一个事件可以放置在多个时间线上,如图1中的“丢失”。
使用此标注方案,我们可以以可承受的成本获得所有对的高质量时间关系,而无需像以前的作品那样减少标注范围,这些作品只标注相邻句子中的事件。为了控制数据质量和资源成本,每个文档将首先由训练有素的标注者进行标注。然后,专家将检查并修改标注结果。我们邀请了49位标注者和17位时间关系标注专家。为了衡量数据质量,我们随机抽取了100个文档,并在上面的管道中对它们进行了两次标注。平均一致性为67.8%。
统计:我们获得了25843次TIMEX,包括20654次DATE、4378次DURATION、793次TIME和18次PREPOSEXP。基于事件和TIMEX,我们总共标注了1216217个时间关系,包括1042709个BEFORE、152702个CONTAINS、937个SIMULTANIUS、9850个OVERLAP、639个BEGINS-ON和380个END-ON。我们可以看到类型之间的数据不平衡是严重的。为了确保创建的数据集很好地反映真实世界的数据分布,我们不干预标签分布,并保持MAVEN-ERE中的不平衡分布。这对未来的时间关系提取模型提出了挑战。
MAVEN-ERE比现有数据集大几个数量级,是我们所知的第一个百万规模的时间关系提取数据集。我们的时间轴标注方案也带来了更密集的标注结果。对于每100个单词,MAVEN-ERE有95.3个时间关系,而MATRES有14.3个。我们认为,数据大小的飞跃可以显著促进时间关系提取研究,并促进广泛的时间推理应用。

2.3 因果关系
任务描述:理解因果关系是人工智能的长期目标。因果关系提取是对事件之间的因果关系进行评价的一项重要任务。为了实现crowd-sourcing annotation,我们没有采用复杂的因果关系定义,而是在之前的讨论之后标注了两种类型的直接和明确的因果关系类型:原因和前提。CAUSE被定义为“鉴于头部事件,尾部事件是不可避免的”,PRECONDITION被定义为:“如果头部事件没有发生,尾部事件就不会发生”。注意,我们允许标注负面事件的因果关系,这些事件实际上没有发生。通过这种方式,我们还涵盖了先前文献中讨论的负面因果关系。
标注:考虑到因果关系的时间性质,我们将标注范围限制为时间标注中标记有BEFORE和OVERLAP关系的事件对。进一步减少标注开销,我们要求标注者考虑因果关系的传递性,并做出最少的标注。也就是说,如果“A原因/前提B”和“B原因/前提C”已被标注,则A和C之间的因果关系可以被丢弃。此外,我们在同一阶段标注因果关系和子事件关系,以便我们可以在传递性规则中涉及子事件关系。这意味着,如果您有(1)“A原因/前提条件B和C子事件B”或(2)“A子事件B和B前提条件C”,则可以放弃A和C之间的因果关系。然后在人工标注之后自动完成丢弃的关系。我们邀请了58名训练有素的合格标注员,每个文档都由3名独立的标注员进行标注。最终结果通过多数投票获得。因果关系的平均标注者一致性为69.5%(Cohen’s kappa)。
统计:我们获得了57992个因果关系,包括10617个CUASE和47375个前提条件。表4显示了MAVEN-ERE和现有广泛使用的数据集的大小,包括BECauSE 2.0、CaTeRS、RED、Causal-TB和EventStoryLine。MAVEN-ERE仍然比所有现有数据集大得多。

2.4 子事件关系
任务描述:子事件关系提取需要识别事件A是否是事件B的子事件。“A Subevent B”表示A是B的组成部分,在时空上由B包含。子事件关系将未连接的事件组织成层次结构,支持事件理解应用程序。
标注:考虑到CONTAINS关系,我们将标注范围限制为事件对子事件定义中固有的时间包含属性。这显著减少了标注开销。子事件关系标注是与因果关系一起进行的,我们邀请了相同的58位标注者。每个文件都由3名标注人进行标注,最终结果由多数投票获得。标注者之间的平均一致性为75.1%(Cohen’s kappa)。
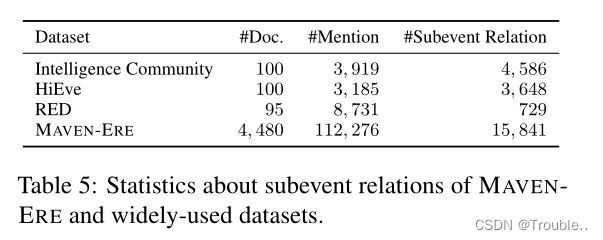
统计:我们在标注后得到了15841个子事件关系。表5显示了MAVEN-ERE和现有数据集的大小比较,包括情报社区、HiEve和RED。我们可以看到,MAVEN-ERE也显著大于现有数据集。
3、数据分析
3.1 相关事件之间的距离
理解长距离事件对之间的关系有助于理解话语层面的文档,建模长距离依赖性是NLP模型的长期挑战。因此,我们分析了MAVEN-ERE中标注事件关系的距离分布,并将其与表6中现有最广泛使用的数据集进行比较。
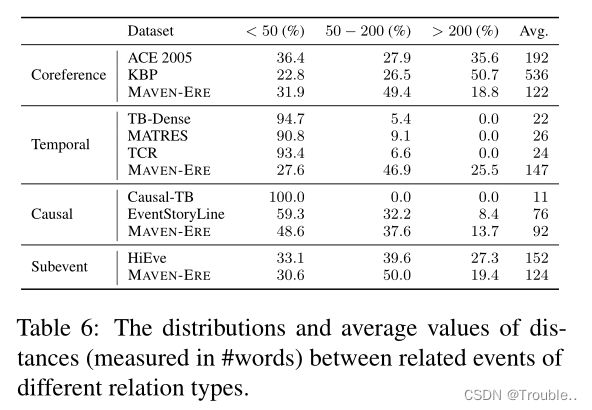
对于时间关系,由于主流标注方案要求识别每个事件对的关系,因此现有使用最广泛且高质量的数据集,如TB Dense和MA-TRES将标注范围限制为相同或相邻句子中的事件,并忽略长距离时间关系,这也是信息性的丢失。这也限制了基于它们的因果关系数据集,如因果TB。如表6所示,借助于我们的时间线标注方案,MAVEN-ERE与现有数据集相比具有更多的长距离时间和因果关系,这可以更好地支持真实世界的应用,并对ERE模型提出了新的挑战。
对于共参考关系,MAVEN-ERE具有更短的平均距离和更高的短距离率。这是因为MA VEN涵盖了更多的通用事件,并标注了更密集的事件提及。相比之下,MAVEN-ERE每100个单词中有8.8个事件被提及,而ACE 2005和TAC KBP的这一数字分别为1.8和4.2。对于子事件关系,HiEve和MAVEN-ERE的分布是相似的,我们认为HiEve的平均距离更长,因为它的平均文档长度更长(333字对284字)。
3.2 关系传递性
时间和因果关系遵循一定的及物性规则,例如,如果存在“A先于B”和“B先于C”,“A先于C”也成立。先前的ERE方法通常在后处理和训练中使用这些自然传递性规则作为约束。在这里,我们通过计算可以从具有传递性规则的其他关系中推断出多少关系,来估计在处理MAVEN-ERE时考虑传递性的重要性。我们考虑的详细及物性规则见附录B。
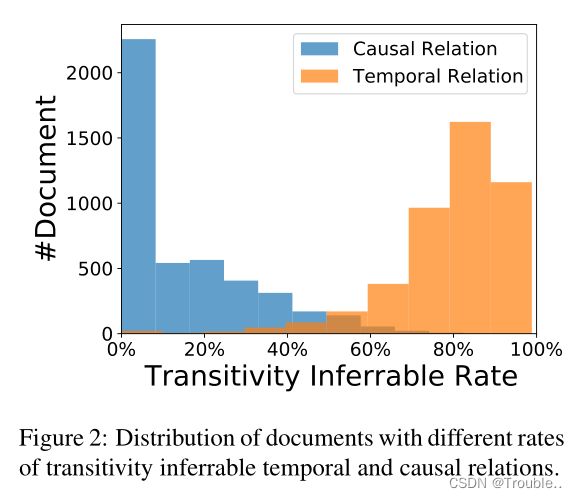
总体而言,88.8%的时间关系和23.9%的因果关系可以通过及物性规则推断。我们在图2中进一步绘制了包含不同传递率可推断关系的文档的分布。我们可以看到,对于大多数文档,60%以上的时间关系可以通过传递性规则来推断。传递性可推断的因果关系虽然明显较少,但也占了很大的比例。这些结果表明,考虑关系及物性有助于处理MAVEN-ERE,我们鼓励未来的工作对此进行探索。
4、实验和分析
为了证明MAVEN-ERE的挑战并分析ERE的潜在未来方向,我们进行了一系列实验。
4.1 实验设置
模型:考虑到预训练语言模型(PLM)已经主导了广泛的NLP任务,我们采用了广泛使用的PLM RoBERTa-BASE作为主干网络,并在此基础上构建分类模型,这为4个ERE任务提供了简单但强大的基线。为了提取文档中的事件关系,我们使用RoBERTa-BASE对整个文档进行编码,并设置一个额外的分类头,将不同事件对对应事件触发器位置的上下文化表示作为输入。然后我们对模型进行微调以对关系标签进行分类。除了独立训练4个任务外,我们还结合4个任务的损失设置了一个简单的联合训练模型,这是为了证明我们统一标注的好处。实施细节见附录C。
基准:ACE 2005, TAC KBP , TB-Dense,MATRES, TCR,Causal-TB, EventStoryLine, and HiEve.
评估指标:micro precision、recall、F-1。
4.2 实验结果
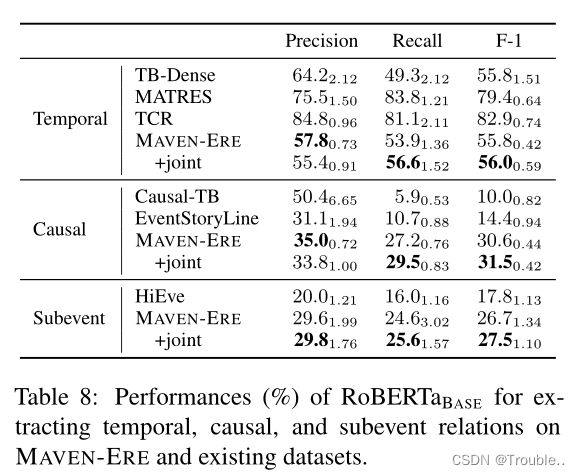
表7显示了共参考关系的实验结果,表8显示了其他3个ERE任务的实验结果。我们可以观察到:(1)对于提取共指事件、因果和子事件关系,模型在MAVENERE上的性能远远高于之前的数据集,这表明了我们更大数据规模的优势。(2) 对于时间关系,MATRES和TCR的性能显著高于MAVEN-ERE。这是因为他们仅包含4种关系类型和标注相邻句子中的局部事件对,这导致更容易的数据和膨胀的模型性能。使用时间线标注方案,MAVEN-ERE标注文档中的6类型全局时间关系,较低的性能更好地反映了时间理解的固有挑战。TB Dense的性能要低得多,但我们认为这是由于TB Dense数据规模小(36个文档),无法很好地训练模型。(3) 除了事件共指之外,其他3个ERE任务的性能远远不能实际使用。这表明,理解多样化和复杂的事件关系对于NLP模型来说是一个巨大的挑战,需要更多的研究工作。(4) 在4项任务上直接联合训练可以带来一定的改进,尤其是在数据较少的任务上,即因果和子事件ERE。这表明,考虑事件关系之间的丰富交互对于处理复杂的ERE任务是有希望的。

4.3 分析数据范围
与现有数据集相比,MAVEN-ERE显著增加了所有ERE任务的数据规模。为了评估更大数据规模带来的益处,并评估MAVEN-ERE是否提供了足够的训练数据,我们进行了消融研究在训练数据集上的范围。
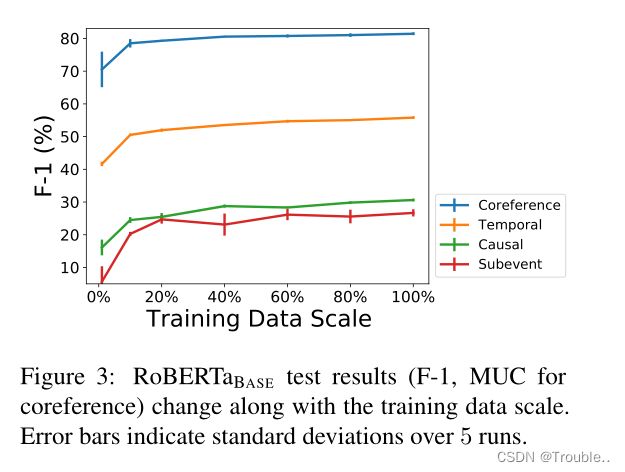
图3显示了RoBERTa-BASE的测试性能如何随着训练中使用的数据比例的不同而变化。我们可以看到,不断增加的训练数据规模带来了更高和更稳定的性能,这表明了MAVEN-ERE大规模的优势。在MAVEN-ERE的规模上,性能改进相当微不足道。这表明MAVEN-ERE通常足以训练ERE模型。
4.4 事件之间的距离分析
与3.1类似,我们分析了相关事件之间的距离如何影响模型性能。我们对一个联合训练的模型进行了抽样,并在表9中看到了它在不同距离的数据上的表现。由于事件共指分辨率的评估是基于聚类的,不能用距离来划分,因此我们只研究其他3个任务。

对于因果关系和子事件关系,在距离较长的数据上的性能较低,这直观地表明,建模长期依赖性对ERE仍然很重要,尽管PLM是有效的。然而,对于时间关系,距离较长的数据更容易。我们认为这是因为叙事距离较长的事件对通常也具有较长的时间距离,这使得它们的关系更容易分类。
4.5 错误分析
我们进一步分析了联合训练模型预测中的误差,为进一步改进提供了见解。考虑到事件共指消解任务已经达到了较高的性能,并且其基于聚类的评估不同,我们只分析了其他3个任务。结果如表10所示。我们可以看到,识别错误(假阳性和假阴性)占所有错误的大部分。这表明,ERE面临的最重要挑战仍然是确定是否存在关系。此外,像3.2一样,我们分析了通过将传递性规则应用于其他预测可以纠正多少错误。这些可修复传递性的错误只占很小的比例,这表明复杂的模型从大量数据中学习到了传递性规则,但并不完美。

5、相关工作
由于理解事件关系在NLP中的基本作用,已经构建了各种ERE数据集。事件共指关系通常包含在事件提取数据集中,如MUC、ACE和TAC KBP。此外,一些数据集专注于无限制的共指消解,忽略了事件语义类型,如OntoNotes和ECB数据集。根据TimeML规范,已经构建了TimeBank和TempEval等已建立的时间关系数据集。然而,这些作品表现出低标注协议和效率问题。Ning等人基于Chambers等人的密集方案开发多轴标注标注方案,以缓解这些问题,Reimers等人建议将事件开始和结束点固定在特定时间。我们的时间线标注方案受到了它们的启发。基于时间理解,开发了因果关系数据集。为了将事件组织成层次结构,收集了子事件关系数据集。
然而,这些数据集的规模有限,不同类型的关系很少集成到一个数据集中。一些数据集标注了两种或三种关系。O’Gorman等人和Hong等人文档内和跨文档事件关系提供了统一的标注方案,但他们构建的数据集也很小。我们参考O’Gorman等人的指南构建MAVEN-ERE。
6、总结和未来工作
我们提出了MAVEN-ERE,这是一个用于事件共指、时间、因果和子事件关系的统一大规模数据集,它显著缓解了以前数据集的小规模和缺乏统一标注问题。实验表明,真实世界的事件关系提取非常具有挑战性,可以通过联合考虑多种关系类型和更好地建模长期依赖性来改进。未来,我们将把数据集扩展到更多场景,比如涵盖更多与事件相关的信息和语言。