Python数据分析之numpy的应用
numpy (Numerical Python) 是 Python
语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。numpy 通常与 SciPy(Scientific
Python)和 Matplotlib(绘图库)一起使用.
numpy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
-
-
1.numpy的数组对象
1.数组属性:ndarray(数组)是存储单一数据类型的多维数组。使用array函数创建数组时,数组的数据类型默认是浮点型。自定义数组数据,则需预先指定数据类型。

2.创建数组:numpy.array(object, dtype=None, copy=True, order=‘K’,subok=False,
ndmin=0)
3.numpy中数组的应用:
代码如下;
import numpy as np # 导入类库 numpy
'''数组对象array实例化'''
array = np.array(([1, 3, 5, 7], [2, 4, 6, 8], [1, 1, 1, 1])) # 创建三维数组
# 创建一维数组
array0 = np.array(([1, 2, 3, 4]))
# 创建二维数组
array1 = np.array(([1, 2, 3, 4], [1, 2, 3, 4]))
# 创建三维数组
array2 = np.array(([1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]))
# linspace 函数创建数组
array3 = np.linspace(0, 10, 2)
# logspace 函数创建等比数列
array4 = np.logspace(0, 1, 2)
# zeros函数创建数组
array5 = np.zeros((2, 4))
# eye函数创建数组
array6 = np.eye(3)
# diag函数创建数组
array7 = np.diag([1, 3, 5, 7])
# ones函数创建数组
array8 = np.ones((3, 3))
a = np.ndim(array) # 获取数组的维数
b = np.shape(array) # 获取数组的尺寸 eg:(x, y) 解释: x 行 y 列
c = np.size(array) # 获取数组的元素个数
print('当前数组' '\n' + str(array) + '的维数(维度)为:', a)
print('当前数组' '\n' + str(array) + '的尺寸为:', b)
print('当前数组' '\n' + str(array) + '的元素总数为:', c)
d = array1.shape = 4, 2
print('经过' + str(d) + '的变形后数组为:''\n', array1)
'''数组数据类型转换'''
# 整型和浮点型的相互转换
print('转换结果为:', np.float64(24))
print('转换结果为:', np.int8(24.0))
# 整型转换为布尔型
print('转换结果为:', np.bool(24))
print('转换结果为:', np.bool(0))
# 布尔型和浮点型的相互转换
print('转换结果为:', np.float(True))
print('转换结果为:', np.float(False))
'''numpy中的随机数函数random'''
# 生成随机数组(无约束条件)
array9 = np.random.random(5)
# 生成随机数组(服从均匀分布)
array10 = np.random.rand(2)
# 生成随机数组(服从正态分布)
array11 = np.random.randn(3, 3)
# 生成随机数组(给定上下范围)
array12 = np.random.randint(1, 6, size=[2, 2]) # min=1 max=6 2行X2列e
'''通过索引访问数组'''
array2[:1, :1] = 100 # 修改(1 ,1)元素为100
'''变换数组的形态'''
e = array2.reshape(1, 12) # 修改数组的形状
f = array2.ravel() # 用ravel函数展平数组
g = array2.flatten() # 用flatten函数展平数组 默认为横向展平
h = array2.flatten('F') # 用flatten函数展平数组 纵向展平
2. numpy中的矩阵及通用函数
1.矩阵的创建与组合:
import numpy as np # 导入类库 numpy
'''矩阵创建'''
array = np.array(([1, 3, 5, 7], [2, 4, 6, 8], [1, 1, 1, 1])) # 创建三维数组
arr1 = np.mat("1 2 3;4 5 6;7 8 9") # 使用mat函数创建矩阵
arr2 = np.matrix([[123], [456], [789]]) # 使用matrix函数创建矩阵
a = np.bmat("arr1 arr2; arr1 arr2") # 使用bmat函数合成矩阵
print(a)
2.矩阵的运算:
矩阵与数相乘:matr1 _3
矩阵相加减:matr1±matr2
矩阵相乘:matr1 _ matr2
矩阵对应元素相乘:np.multiply(matr1,matr2)
矩阵特有属性:

- 通用函数 (universal function),是一种能够对数组中所有元素进行操作的函数。
四则运算:加(+)、减(-)、乘(*)、除(/)、幂(**)。数组间的四则运算表示对每个数组中的元素分别进行四则运算,所以形状必须相同。
比较运算:>、<、==、>=、<=、!=。比较运算返回的结果是一个布尔数组,每个元素为每个数组对应元素的比较结果。
逻辑运算:np.any函数表示逻辑“or”,np.all函数表示逻辑“and”。运算结果返回布尔值。
通用函数的广播机制
广播 (broadcasting)是指 不同形状的数组之间执行算术运算的方式 。需要遵循4个原则。
让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐。
输出数组的shape是输入数组shape的各个轴上的最大值。
如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则出错。
当输入数组的某个轴的长度为1时,沿着此轴运算时都用此轴上的第一组值。
一维数组的广播机制:
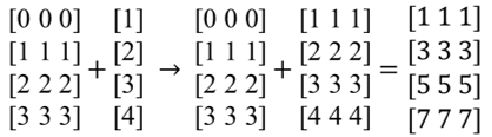
二维数组的广播机制:
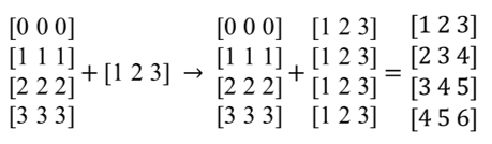
3. 利用numpy 进行统计分析
- 文件读写方式
numpy文件读写主要有 二进制的文件读写 和 文件列表形式的数据读写 两种形式。
备注:存储时可以省略扩展名,但读取时不能省略扩展名。
import numpy as np
np.save("../systemcode/save_array",array) # save函数是以二进制的格式保存数据
np.load("../systemcode/save_array.npy") # load函数是从二进制的文件中读取数据
np.savez('../systemcode/savez_array',array1,array2) # savez函数可以将多个数组保存到一个文件中
np.savetxt("../code/array.txt", array, fmt="%d", delimiter=",") # savetxt函数是将数组写到某种分隔符隔开的文本文件中
np.loadtxt("../code/array.txt", delimiter=",") # loadtxt函数执行的是把文件加载到一个二维数组中
np.genfromtxt("../code/array.txt", delimiter=",") # genfromtxt函数面向的是结构化数组和缺失数据
- 排序 :
- 直接排序
最常用的排序方法–sort函数
sort函数也可以指定一个axis参数,使得sort函数可以沿着指定轴对数据集进行排序。axis=1为沿横轴排序; axis=0为沿纵轴排序。 - 间接排序
- argsort函数返回值为重新排序值的下标。 arr.argsort()
- lexsort函数返回值是按照最后一个传入数据排序的。 np.lexsort((a,b,c))
CODE:
import numpy as np # 导入类库 numpy
b =np.array([[0.86705753, 0.47270344, 0.46960053], [0.24891569, 0.52897057, 0.98737962],
[0.51857887, 0.58543909, 0.61704753]])
b.sort(axis=1)
print(b)
a = np.array([6, 2, 3])
c = np.array([9, 1, 3])
c.sort() # 直接排序
print('直接排序:', c)
d = c.argsort() # argsort函数返回值为重新排序值的下标
print('argsort函数排序:', d)
f = np.lexsort((c, a)) # lexsort函数返回值是按照最后一个传入数据排序的
print('lexsort函数排序:', f)
- 去除重复数据(去重)
unique函数 :可以找出数组中的唯一值并返回已排序的结果。
tile函数 :主要有两个参数,参数“A”指定重复的数组,参数“reps”指定重复的次数。
np.tile(A,reps)
repeat函数
:主要有三个参数,参数“a”是需要重复的数组元素,参数“repeats”是重复次数,参数“axis”指定沿着哪个轴进行重复,axis = 0表示 按行
进行元素重复;axis = 1表示 按列 进行元素重复。
numpy.repeat(a, repeats, axis=None)
两个函数的 主要区别 :tile函数是对 数组 进行重复操作,repeat函数是对 数组中的每个元素 进行重复操作。
CODE:
import numpy as np # 导入类库 numpy
a = np.array([11, 22, 54, 3, 6, 9, 8, 15])
b = np.repeat(a, 3) # repeat函数:重复数组中元素3次
print('repeat()函数:', b)
c = np.tile(a, 3) # tile函数:重复数组3次
print('tile()函数:', c)
d = np.unique(c) # 去重函数
print('unique()函数:', c)
'''运行结果'''
# D:\Anaconda3\python.exe E:/Python数据分析/code/test.py
# repeat()函数: [11 11 11 22 22 22 54 54 54 3 3 3 6 6 6 9 9 9 8 8 8 15 15 15]
# tile()函数: [11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15]
# unique()函数: [11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15]
- 常用统计函数
当axis=0时,表示沿着纵轴(行)计算。当axis=1时,表示沿着横轴(列)计算。 默认时计算一个总值 。
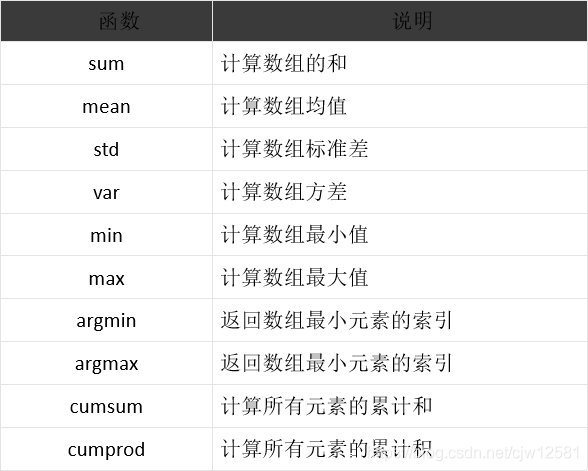
4. 案列:
读取iris数据集中的花萼长度数据(已保存为csv格式),并对其进行排序、去重,并求出和、累积和、均值、标准差、方差、最小值、最大值。

'''案列:读取iris数据集中的花萼长度数据(已保存为csv格式),并对其进行排序、去重,并求出和、累积和、均值、标准差、方差、最小值、最大值。'''
import numpy as np # 导入类库 numpy
data = np.loadtxt('../data/iris_sepal_length.csv') # 读取数据文件
data.sort() # 简单排序
print('简单排序后:', data)
data = np.unique(data) # 去除重复数据
print('数据去重后:', data)
print('数据求和:', np.sum(data)) # 数组求和
print('元素求和', np.cumsum(data)) # 元素求和
print('数据的均值:', np.mean(data)) # 均值
print('数据的标准差:', np.std(data)) # 标准差
print('数据的方差:', np.var(data)) # 方差
print('数据的最小值:', np.min(data)) # 最小值
print('数据的最大值:', np.max(data)) # 最大值
'''运行结果'''
# D:\Anaconda3\python.exe E:/Python数据分析/code/test.py
# 简单排序后: [4.3 4.4 4.4 4.4 4.5 4.6 4.6 4.6 4.6 4.7 4.7 4.8 4.8 4.8 4.8 4.8 4.9 4.9
# 4.9 4.9 4.9 4.9 5. 5. 5. 5. 5. 5. 5. 5. 5. 5. 5.1 5.1 5.1 5.1
# 5.1 5.1 5.1 5.1 5.1 5.2 5.2 5.2 5.2 5.3 5.4 5.4 5.4 5.4 5.4 5.4 5.5 5.5
# 5.5 5.5 5.5 5.5 5.5 5.6 5.6 5.6 5.6 5.6 5.6 5.7 5.7 5.7 5.7 5.7 5.7 5.7
# 5.7 5.8 5.8 5.8 5.8 5.8 5.8 5.8 5.9 5.9 5.9 6. 6. 6. 6. 6. 6. 6.1
# 6.1 6.1 6.1 6.1 6.1 6.2 6.2 6.2 6.2 6.3 6.3 6.3 6.3 6.3 6.3 6.3 6.3 6.3
# 6.4 6.4 6.4 6.4 6.4 6.4 6.4 6.5 6.5 6.5 6.5 6.5 6.6 6.6 6.7 6.7 6.7 6.7
# 6.7 6.7 6.7 6.7 6.8 6.8 6.8 6.9 6.9 6.9 6.9 7. 7.1 7.2 7.2 7.2 7.3 7.4
# 7.6 7.7 7.7 7.7 7.7 7.9]
# 数据去重后: [4.3 4.4 4.5 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6.
# 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.6 7.7 7.9]
# 数据求和: 210.39999999999998
# 元素求和 [ 4.3 8.7 13.2 17.8 22.5 27.3 32.2 37.2 42.3 47.5 52.8 58.2
# 63.7 69.3 75. 80.8 86.7 92.7 98.8 105. 111.3 117.7 124.2 130.8
# 137.5 144.3 151.2 158.2 165.3 172.5 179.8 187.2 194.8 202.5 210.4]
# 数据的均值: 6.011428571428571
# 数据的标准差: 1.0289443768310533
# 数据的方差: 1.0587265306122449
# 数据的最小值: 4.3
# 数据的最大值: 7.9
#
# Process finished with exit code 0
_END _