【个人笔记 | Pytorch课程 | 整理中ing】
【小土堆】
小土堆课程视频
笔记others:
入门与Dataset数据加载
【入门/数据/预处理】
pycharm 安装:https://www.jetbrains.com/pycharm/、指南、
可以在右上写代码,可以在左下控制台写程序(一般用于调试)
conda-Pytorch
深度学习框架的自动微分技术根据实现原理的不同,分为以Google的TensorFlow为代表的图方法,以facebook的Pytorch为代表的↓

安装过程太慢:下载安装包,复制到Anaconda3=>pkgs
conda install --use-local 包名
torch.cuda.is_available()
1、安装: 指南1★、PyTorch、自己写的环境配置Blog√
看电脑python版本 、conda info -e
pip list:可以查看Python中安装了哪些第三方库
查看GPU是否支持cuda-link:设备管理器-显示适配器 or 任务管理器-性能-GPU、方法
虽然Pytorch完全可以在CPU模式下运行,但大多数情况都是使用GPU支持的Pytorch,需要GPU的支持,所以要下载CUDA.(以后要用再说,可新环境下装)
镜像安装、★Anaconda配置Pytorch、
conda activate pytorch
jupyter notebook
2、两大法宝函数
dir()函数:打开、看见,可以当作一个文件夹 (能让我们知道工具箱以及工具箱中的分隔区有什么东西)
help()函数:说明书,在jupyter notebook中使用 排版清晰(能让我们知道每个工具是如何使用的)

3、加载数据(P6)
笔记others:Dateset、


from torch.utils.data import Dataset(从torch的大工具箱里的常用工具区utils里关于数据的data)
查看官方文件×3:①help(Dataset)②Dataset??③按住Ctrl+鼠标点击
class MyData(继承Dataset):
init初始化类去创建实例:一般为整个class提供全局变量,在这里就是为后面的getitem方法和len提供需要的变量(可以放在后面再来写)
一个函数中的变量不能传递个另一个函数中的变量,而self可以把self中指定的内容给后面的函数使用,就相当于指定了一个类中的全局变量。
def __init__(self,root_dir,label_dir): self.root_dir = root_dir //文件夹目录"dataset/train" self.label_dir = label_dir //标签目录"ants" //↓拼在一起,获得每一个标签文件的地址 "dataset/train/ants" self.path = os.path.join(self.root_dir,self.label_dir) //组成列表,就是每一个具体jpg所组成的列表 self.img_path = os.listdir(self.path)

getitem(idx作为索引):通过idx索引获取图片地址
获取文件夹中所有图片:import os
首先设置dir_path=r"/" 然后将该文件夹下所有内容转换成列表img_path_list = os.listdir(dir_path) (可以使用img_path_list[0]来查看第一个文件)
获取其中的每一个图片,就是从img_path汇总读取对应位置,因为要引用上面init定义的变量所以要加self。现在找到名称了,还需要找到它在该目录下的相对路径。
def __getitem__(self,idx): img_name = self.img_path[idx] img_item_path = os.path.join(self.root_door,self.label_dir,img_name) //读取图片 img = Image.open(img_item_path) //label label = self.label_dir return img,labellen长度返回,就是返回img路径列表长度
def __len__(self): return len(self.img_path)
然后可以写一个了
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
弹幕提示:报错的把ants_dataset[0]换成ants_dataset.__getitem__(0)
还有一种方式就是将二者数据集拼接:train_dataset = ants_dateset+bees_dateset
复制相对路径:Ctrl+Shift+C 全局路径:Ctrl+Alt+Shift+C
#Python Console逐步显示
from PIL import Image
img_path= ....jpg" #具体图片路径,记得\\进行语义转换
img = Image.open(img_path)
img.show()4、TensorBoard使用
PyTorch下的Tensorboard 使用:用于数据可视化的工具(对transform后的图像进行展示)原本是tensorflow的可视化工具,pytorch从1.2.0开始支持tensorboard。之前的版本也可以使用tensorboardX代替。直接pip之后有可能打开的tensorboard网页是全白的,如果有这种问题,解决方法是卸载之后安装更低版本的tensorboard(直接pip install就可以了)
通过loss可以看我们需要选择什么样的模型(when符合预期)
add_scalar与add_image☆(弹幕:PLT也能达到同样的效果)
tensorboard ValueError: Duplicate plugins for name projector ★有效!
add_scalar(tag, scalar_value, global_step=None, ):将我们所需要的数据保存在文件里面供可视化使用
tag(字符串):保存图的名称
scalar_value(浮点型或字符串):y轴数据(步数)
global_step(int):x轴数据// logdir=事件文件所在文件夹名
// 在项目文件夹Terminal下:默认端口6006
tensorboard --logdir=logs
// 如果修改端口为6007
tensorboard --logdir=logs --port=6007writer.add_scalar("目标函数",global_step,scalar_value)
#global_step 对应x轴;scalar_value对应y轴writer.add_scalar("y=x",i,i) # y = x 下图1
writer.add_scalar("y=2x",2*i,i) # y = 2x 下图2
writer.add_scalar("y=2x",3*i,i) # y = 3x 下图3

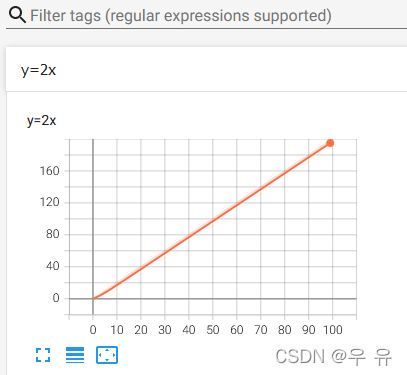

看到图3有个过渡拟合过程。解决办法:①logs下文件全部删除②run③在Terminal下新开local并再次输入命令(tensorboard --logdir=logs) 就得到想要的图像了(出问题就设置绝对路径)


Tensorboard: SummaryWriter类(pytorch版) :大意是将条目直接写入 log_dir 中的事件文件以供 TensorBoard 使用(`SummaryWriter` 类提供了一个高级 API,用于在给定目录中创建事件文件,并向其中添加摘要和事件)。tensorboard --logdir=XXXX(XXXX就是你要求tensorboard writer把文件写入的那个地方在上图中就是logs),为了防止端口冲突,可以设置一个特别的端口,就是在上面的命令后再加一个 --port=端口

add_image(self, tag, img_tensor, global_step=none, walltime=none, dataformats=‘CHW’)
add_image(self, tag, img_tensor, global_step=none, walltime=none, dataformats=‘CHW’)
绘制图片,可用于检查模型的输入,监测 feature map 的变化,或是观察 weight。
tag:就是保存图的名称
img_tensor:图片的类型要是torch.Tensor, numpy.array, or 这三种OpenCV读取的数据格式就是Numpy型,可以print(type(img))看一下类型,常用pil
global_step:第几张图片
dataformats=‘CHW’,默认CHW,tensor是CHW,numpy是HWC这里可能会报错,可以debug或者print(xxx.shape)查看一下,if维度问题就在这改
完整代码:某张图片的路径给img_path; 打开这张图片到img_PIL; 因为add_image要求图片类型为tensor/numpy/string,而pil查看type(img_path为pil),所以先转成numpy;[可以print一下type和shape(opencv读取的数据格式是Numpy)]; 然后就可以设置add_image里的参数了,up遇到的一个问题就是dataformats注意一下shape
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/6240329_72c01e663e.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("train", img_array, 1, dataformats='HWC')
# y = 2x
for i in range(100):
writer.add_scalar("y=2x", 3*i, i)
writer.close()
5、torchvision中的transforms
①使用的时候注意input和output的类型;
②多看官方文档,关注方法需要什么参数(在使用的时候就去看它官方文档中的init文件,对功能和参数都有很清晰的解释);
③不知道返回值or数据是什么类型or有TypeError报错的haul,就print、print(type())、debug
④借助一下tensorboard工具查看得到的图片
Alt+Enter 导入库 Ctrl+P 看要加什么参数

视频笔记:
from torchvision import transforms ->进入transform 定义了很多class的工具箱
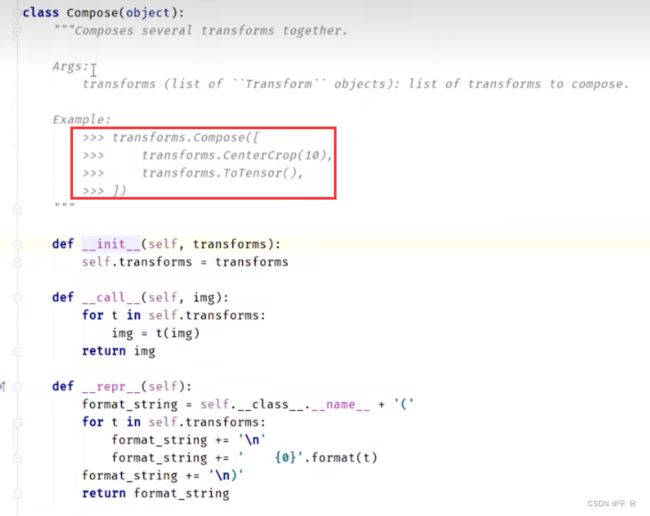
torchvision.transforms中的compose,常用的是(PIL/numpy)ToTensor√、Normalize、Resize
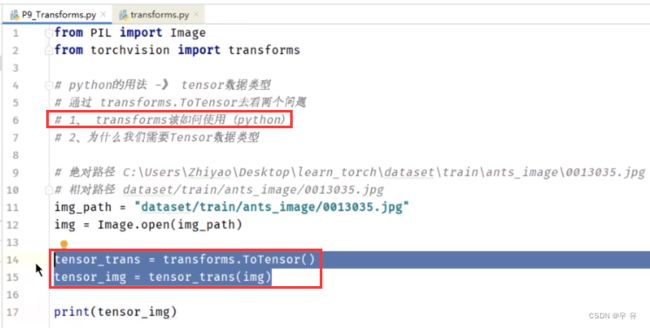
关于__call__的使用(双下划线就是内置参数)
class Person:
def __call__(self,name):
print("__call__"+" Hello"+name)
person = Person()
person("zahngsan")//可以ctrl+P看有没有参数输入提示
//输出:__call__ Hello zhangsan
class Person:
def hello(self,name)
print("hello"+name)
person = Person()
person.hello("zhangsan")
//输出:zhangsan关于ToTensor的使用

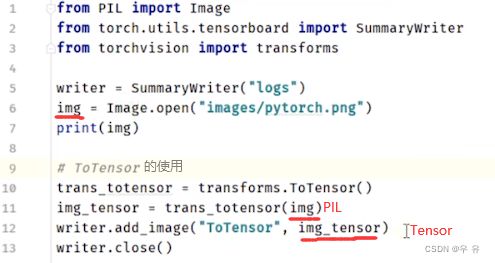
关于Normalize的使用(传入RGB三个通道的均值和标准差)(输入PIL图片)


关于resize的使用(输入是PIL)

 (下面2实际代码参数换位置会报TypeError类型错误)
(下面2实际代码参数换位置会报TypeError类型错误)

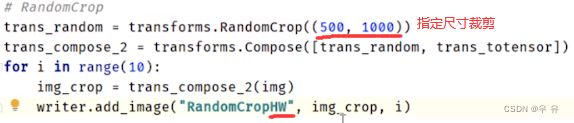
关于随机裁剪RandomCrop的使用

6、torchvision中数据集的使用:Dataset和Dataloader
官网torchvision中数据集(datasets、)(迅雷工具)



import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()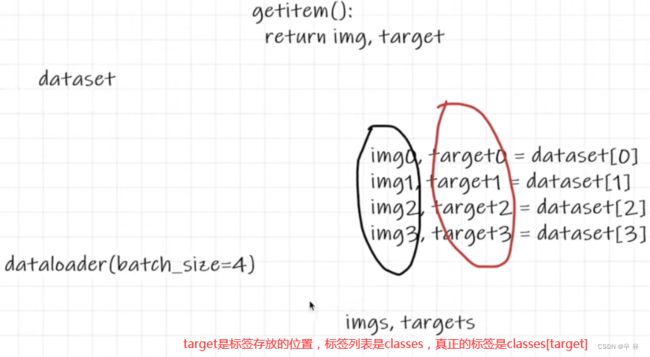
shuffle取数据的时候batchsize里图片顺序是被打乱的
【神经网络】
1、Pytorch中的torch.nn
torch.nn
Containers
| Module |
Base class for all neural network modules.(模板,你们拿去用吧/修改吧在init和forward) |
| Sequential |
A sequential container. |
| ModuleList |
Holds submodules in a list. |
| ModuleDict |
Holds submodules in a dictionary. |
| ParameterList |
Holds parameters in a list. |
| ParameterDict |
Holds parameters in a dictionary. |
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
以nn.Module为例,好用工具之"代码 -> 生成 -> 重写 ->挑你要的方法"



卷积conv2d(主要是5参数,再主要是前两参数in_channel,out_channel,kernel,stride,padding)
 (1channel)
(1channel)
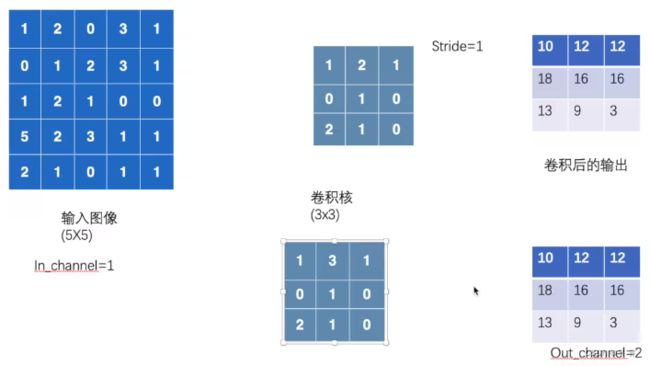 output_c=2c
output_c=2c
首先传入Input和Kernel发现都是只有HW(左图),而conv要求通道minibatch、channel、H、W,所以要利用Torch.reshape进行改变。(例子nn.conv2d,output2是步长2,output3是paddding=1)



| nn.Conv1d |
Applies a 1D convolution over an input signal composed of several input planes. |
| nn.Conv2d |
Applies a 2D convolution over an input signal composed of several input planes.(主要用2d |
| nn.Conv3d |
Applies a 3D convolution over an input signal composed of several input planes. |

在跟着up写conv2d时遇到的一些问题:
报错1:urllib.error.URLError:
原因及解决办法(方法2):是由于python版本之间差异导致的,Python 3中urllib2用urllib.request替代;所以把所有位置都换成带有.request,继续报错,关闭ssl本地认证(加进代码),然后写入main主函数里(不放在里面也可以跑通)。
报错2:自己去写第一步输出卷积的时候,加载的是之前已经下载好的数据集;然后有下面一个报错,是因为conv2d这里写错了,改成Conv2d并且红色灯泡Import就可以解决了 。


报错3:SyntaxError: Non-UTF-8 code starting with '\xba' in file

解决方法:在代码最开头加上这句(我小写也不行)
# coding=UTF-8接着就是借助tensorboard工具可视化过程一下
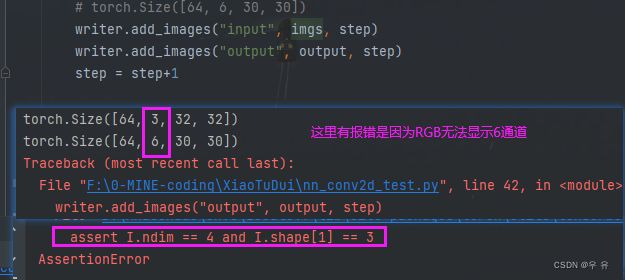
报错4:设置的output_c是6,而RGB三通道无法显示,所以up提供了reshape方法,但不严谨
然后取terminal终端去输入↓命令,就打开了。
tensorboard --logdir=logs最终版:
# coding=UTF-8
import torchvision.datasets
import torch
import torchvision
from torch import nn, conv2d
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
class SUNDAY(nn.Module):
def __init__(self):
super(SUNDAY, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1)
# self.conv1 = conv2d(in_channel=3,output_channel=6,kernel_size=3,stride=1)
def forward(self,x):
x=self.conv1(x)
return x
if __name__ == '__main__':
dataset = torchvision.datasets.CIFAR10(r'./data', train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
sunday = SUNDAY()
# print(sunday)
writer =SummaryWriter("../logs")
# 然后想看data里每一张图片,所以
step =0 #global_step
for data in dataloader:
imgs, targets = data # 现在已经使tensor格式所以可以直接送入到网络当中
output = sunday(imgs) # 就是data中的图片数据imgs送入神经网络SUNDAY中经过forward卷积操作得到的结果
print(imgs.shape) # 看一下conv1是否实现
# torch.Size([64, 3, 32, 32])
print(output.shape)
# torch.Size([64, 6, 30, 30])
writer.add_images("input", imgs, step)
output = torch.reshape(output, (-1,3,30,30)) # 不知道第一个数是多少的时候就写-1,会自动根据后面
writer.add_images("output", output, step)
step = step+1【唐宇迪】
学一个算法、读一篇论文、啃一个源码
积累二三十个,面向复制粘贴编程,创新点就来了;
CV: ctrl+C、ctr+V
在理解完源码和论文之后,从源码中去积累
论文读再多不如debug一遍收获的多;
大同小异 看不懂论文、看不懂网络、看不懂代码 => 积累的不够呀
Day1: 深度学习CNN卷积神经网络算法精讲
1. 神经网络模型知识点分析
2. 神经网络模型架构解读
3. 卷积神经网络整体架构及参数设计
Day2:AI领域最火模块transformer实例解读
1. 深度学习CNN卷积神经网络算法精讲
2. 当下最火模块注意力机制解读
3. 视觉领域transformer应用实例
4. 视觉当下最新研究方向与进展 两天的内容一样重要
【预习视频Day1】
transform:数据增强
.ToTensor():无论图像是用啥工具读取进来的都要转换成tensor格式[张量-矩阵] [Numpy-array]
.Normalize()标准化
batch:一次做八题,一次送几张
Dataloader:
dataset.ImageFolder
resnet:至少不比原来差
VGG:大量3x3卷积堆叠(16/19层):随着网络结构加深,56layer比20效果变差
model_name=’resnet’ 迁移学习/预训练模型(都用现成的)
遍地都是预训练模型(做好搬运工 抄作业记得不要把名字也抄上了啊喂 | 自己的输出修改 )
迁移学习:
data少:
冻住前几层-提取特征:用别人的预训练模型权重不做改动
越往右面越接近输出层,做自己的分类任务
data多:少冻几层
优化器设置:
学习率lr:权重参数更新幅度
变化幅度:一开始幅度大一点没事,后面接近答案不可以一步子跨过终点,所以后面lr要小一点
学习率衰减策略:lr经过多少step衰减成原来的几分之几
训练模块:
1000个样本,batch=100样本,1epoch表示把整个数据集都遍历一遍
∴1epoch=10batch,即1epoch迭代10次,每次迭代10batch
#训练(更新参数)和验证(期末考试)if train if val
前向传播要计算loss、_preds=torch.max(outpts,1)要得到当前预测各类别的最大概率
backwards反向传播(框架已实现)w更新
#计算损失与打印操作
指标:accuracy、val_loss
加载训练好的模型:
保存好训练好的模型、制定好路径
需要保证所有输入数据的大小规格保持一致,训练的时候多大 测试的时候也要多大
制作好数据源:input-transform=224x224
所以在测试时候,要先处理数据:
def process_image(image_path):
# 读取测试数据
img = Image.open(image_path)
# Resize,thumbnail方法只能进行缩小,所以进行了判断
if img.size[0] > img.size[1]:
img.thumbnail((10000, 256))
else:
img.thumbnail((256, 10000))
# Crop操作
left_margin = (img.width-224)/2
bottom_margin = (img.height-224)/2
right_margin = left_margin + 224
top_margin = bottom_margin + 224
img = img.crop((left_margin, bottom_margin, right_margin,
top_margin))
# 相同的预处理方法
img = np.array(img)/255
mean = np.array([0.485, 0.456, 0.406]) #provided mean
std = np.array([0.229, 0.224, 0.225]) #provided std
img = (img - mean)/std
# 注意颜色通道应该放在第一个位置
img = img.transpose((2, 0, 1))
return img【transformer Day2】
文本的例子->图像的例子
之前的算法谁离我近我就考虑谁,比如这里x2考虑x1最多,但是并不一定是最接近的就是最重要的/关系紧密的,是要考虑上下文语境的。
同一个词语在不同的语境中表示的意思是有所区别的 => 关注一个词,同时考虑上下文信息



注意力机制做的事情:把平稳特征转换成层次分明
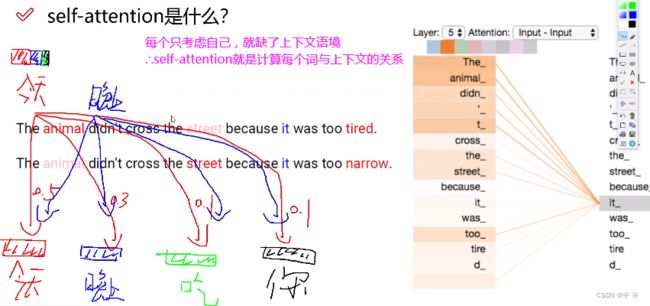
引入三个辅助向量:Q(由这个词出发去问别人)、K(被问到的时候要回答的)、V,那怎么用Query和Key衡量词与词之间的上下文的关系呢?

向量之间内积越小关系越差;向量之间内积越大关系越好。
由谁出发提供一个Query向量,谁被问到要提供一个key向量。所以x1访问x1就是q1`k1、x1访问x2就是q1`k2,所以这里要做的就是权重赋值,多少给x1多少给x2
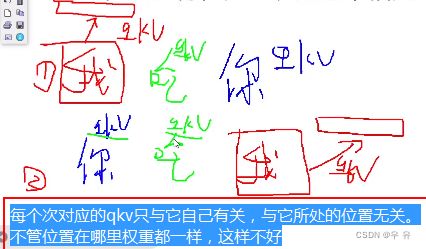
原始输入只有x1,x2,怎么得到QKV?通过训练得到kqv:用三组权重参数矩阵,分别训练得到三组权重向量QKV

输入序列中的每一个token都有qkv

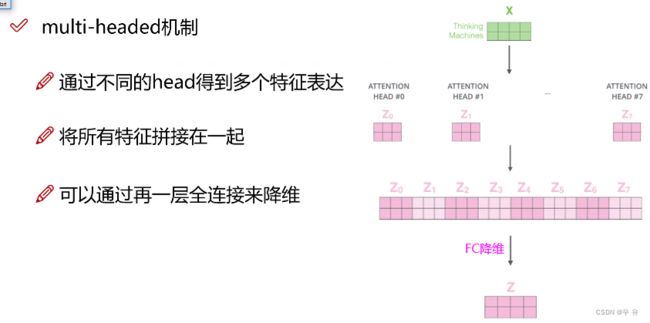
multi-headed多头注意力机制:




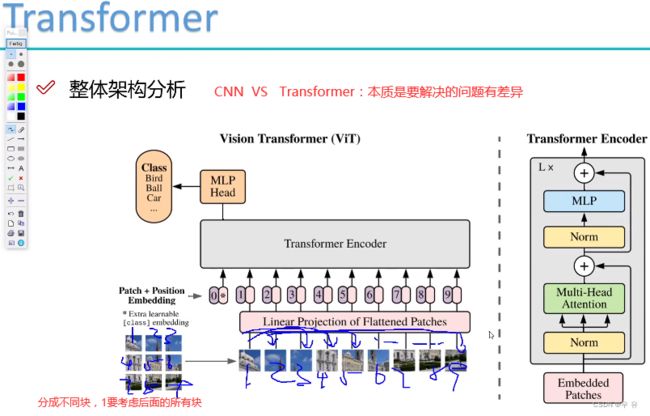
CNN vs Transformer


Transformer优点:三个臭皮匠顶上诸葛亮;
缺点:每个点与其他点都要计算很慢,且input大效果好但是特征多也复杂;同时一个点真的需要跟所有的点都要求他们之间的关系呢?=>不同的注意力机制(周围点、横向轴向点)=>现在transformer都在解决的一个问题是怎么简化计算。

transformer的应用:物体检测、轨迹估计、时间序列、 关键点匹配

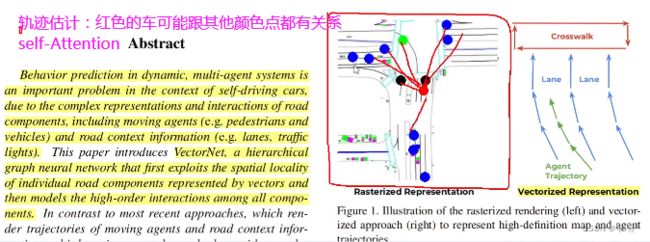


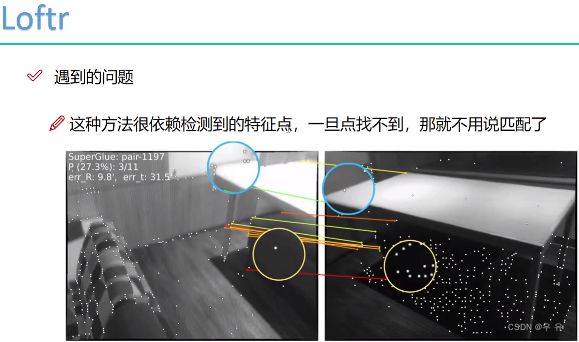
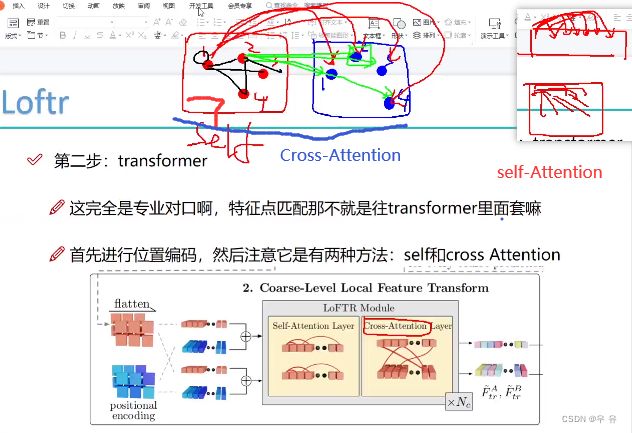 自注意力机制:一张图片中点与这张图中其他点之间的位置关系;CrossAtention跨图片
自注意力机制:一张图片中点与这张图中其他点之间的位置关系;CrossAtention跨图片