迁移学习——冻结部分参数,修改全连接层
目录
一、迁移学习简单概念
二、代码例子
1、加载AST网络
2、修改网络结构
3、 加载预先训练好的模型参数
4、弹出mlp_head.1层参数
5、更新自己的模型参数
6、冻结部分层
7、选出requires_grad = True 的参数
8、定义损失函数、优化器等等
一、迁移学习简单概念
迁移学习是指利用旧知识来学习新知识,主要目标是将已经学会的知识很快地迁移到一个新的领域中[1]。
[1]刘鑫鹏,栾悉道,谢毓湘,等.迁移学习研究和算法综述.长沙大学学报,2018,32(5):33−36,41。
二、代码例子
此处以预训练模型AST为例,修改最后的mlp.1。
1、加载AST网络
pretrained_model = ASTModel(label_dim=527,
fstride=10, tstride=10,
input_fdim=128, input_tdim=1024,
imagenet_pretrain=False, audioset_pretrain=False,
model_size='base384')
print(pretrained_model)将“imagenet_pretrain, audioset_pretrain“都设为了False,此时只加载了AST的网络结构,没有用预训练模型的参数来初始化。print后的输出为:
ASTModel(
....
....
(mlp_head): Sequential(
(0): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(1): Linear(in_features=768, out_features=527, bias=True)
)
)因为我们修改的是最后的mlp_head[1],这里只给出mlp_head的部分。 可见此时的输出维度为527。
2、修改网络结构
num_ftrs = pretrained_model.mlp_head[1].in_features # 获取mlp_head[1]输入
pretrained_model.mlp_head[1] = nn.Linear(num_ftrs,10) # 修改mlp_head[1]的输出
print(pretrained_model)将mlp_head[1]的输出改为了10 ,结果如下:
ASTModel(
....
....
(mlp_head): Sequential(
(0): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(1): Linear(in_features=768, out_features=10, bias=True)
)
)3、 加载预先训练好的模型参数
AST的pth文件下载路径:https://github.com/YuanGongND/ast
pretrained_dict = torch.load(r'E:\code\DESED_shujia\pretrained_models\audioset_0.4593.pth')
print(pretrained_dict)
此时的输出为:

4、弹出mlp_head.1层参数
pretrained_dict.pop('module.mlp_head.1.weight')
pretrained_dict.pop('module.mlp_head.1.bias')此时mlp_head.1层参数已经被删除。
5、更新自己的模型参数
# 自己的模型参数变量,在开始时里面参数处于初始状态,所以很多0和1
model_dict = pretrained_model.state_dict()
print(f"自己模型参数更新前的状态:{model_dict}")
# 去除不需要的参数
pretrained_dict={k: v for k, v in pretrained_dict.items() if k[7:] in model_dict}
# 模型参数更新
model_dict.update(pretrained_dict)
print(f"自己模型参数更新后的状态:{model_dict}")模型参数更新之前,参数处于初始状态,有很多0和1,输出的部分截图如下:
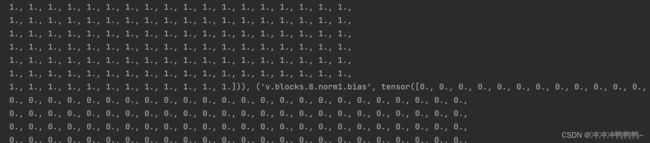
模型参数更新之后, 已经不再是0和1,与上图同一处参数如下:
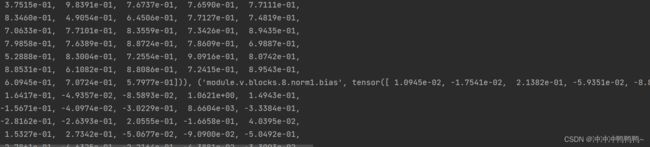
⭐由于pretrained_dict和mode_dict的keys()相差一个"moudle.",所以“#去除不需要的参数”的代码中k后加上了[7:],若两者的keys()相同,则不需要加。本例子中的pretrained_dict和mode_dict的keys()输出如下:
![]()
6、冻结部分层
# 冻结部分层——将满足条件的参数的 requires_grad 属性设置为 False。
# requires_grad 为 true 进行更新,为 False 时权重和偏置不进行更新。
for name, value in pretrained_model.named_parameters():
if (name != 'fc.weight') and (name != 'fc.bias'):
value.requires_grad = False7、选出requires_grad = True 的参数
# 将模型中属性 requires_grad = True 的参数选出来(要更新的参数在 params_conv 当中)
params_conv = filter(lambda p: p.requires_grad, pretrained_model.parameters())8、定义损失函数、优化器等等
后面这些看自己的需求。优化器只更新需要更新的层,比如:
optimizer = torch.optim.SGD(params_conv, lr=1e-3)