CVPR2021-RSTNet-Captioning with Adaptive Attention on Visual and Non-Visual Words
论文地址: CVPR2021-RSTNet-Captioning with Adaptive Attention on Visual and Non-Visual Words

背景介绍
在image captioning领域最常使用的是 encoder-decoder 框架。最开始研究者都是使用CNN进行视觉特征的提取,然后在使用RNN进行句子的生成。近几年,基于区域的 (region-based) 的视觉特征提取占了主流地位。它是先使用比如Faster-RCNN 进行有效目标区域的框选,再使用这些框选的特征进行文字的生成。但是这一方法存在的问题是区域提取过程非常耗时,目前大多数具有区域特征的模型都是直接对缓存的视觉特征进行训练和评估的。
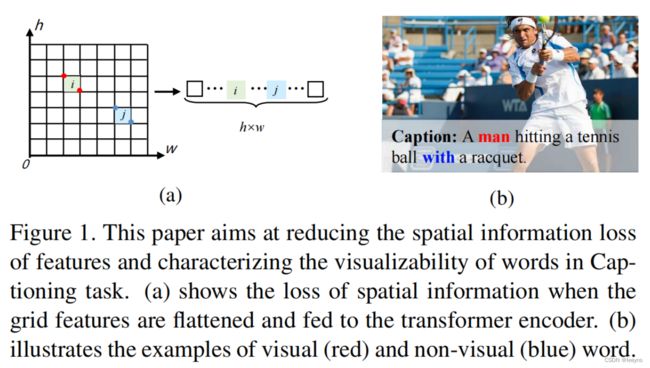
本文又重新探索了基于grid的特征提取。但是基于grid的特征,在作为Transformer的输入时,会被打平维度,因此会丢失空间信息。同时,大部分的image captioning的模型都是全程基于视觉特征和生成文字的关系来进行文本的生成,然而在一些句子中其实会存在一些与视觉无关的文字信息,比如with, and等。因此,所有文字都使用基于图片和文字的关系来生成是有弊端的。因此本文将生成的文字分为两种:
1. Visual word;
2. Non-visual word.
上述的两个当前image captioning模型存在的问题由下图展示。
主要改进
本文的主要改进点有两个:
- 提出了Grid-Augmented module, 将相对位置之间的空间几何关系合并到网格中,以便于更全面地使用grid feature。
- 提出了Adaptive Attention module, 它是基于语言上下文和视觉特征来衡量视觉特征和语言上下文对文本生成的贡献。
对于encoder部分的每个注意模块,结合网格特征的相对几何信息,计算出更准确的注意分布。对于decoder部分,视觉和语言线索之间需要权衡,而不是直接预测单词。
模型的整体结构如下:

视觉特征由我们的grid feature表示,文本特征由预训练的基于bert的语言模型提取,我们的Adaptive Attention module 衡量视觉特征和语言上下文对单词预测的贡献。
Grid-Augmented module
首先计算每个grid的位置: { ( x i m i n , y i m i n ) , ( x i m a x , y i m a x ) } \{(x_i^{min}, y_i^{min}), (x_i^{max}, y_i^{max})\} {(ximin,yimin),(ximax,yimax)},它们分别表示每个grid的左上和右下的坐标。然后计算出每个各自的中心点坐标和宽高,公式如下。
( c x i , c x i ) = ( x i min + x i max 2 , y i min + y i max 2 ) w i = ( x i max − x i min ) + 1 , h i = ( y i max − y i min ) + 1 \begin{aligned} \left(c x_{i}, c x_{i}\right) & =\left(\frac{x_{i}^{\min }+x_{i}^{\max }}{2}, \frac{y_{i}^{\min }+y_{i}^{\max }}{2}\right) \\ w_{i} & =\left(x_{i}^{\max }-x_{i}^{\min }\right)+1, \\ h_{i} & =\left(y_{i}^{\max }-y_{i}^{\min }\right)+1 \end{aligned} (cxi,cxi)wihi=(2ximin+ximax,2yimin+yimax)=(ximax−ximin)+1,=(yimax−yimin)+1
接着我们需要计算整个feature map中每个grid和其他grid之间的位置关系 λ g ∈ R N × N \lambda_g \in R^{N \times N} λg∈RN×N.
r i j = ( log ( ∣ c x i − c x j ∣ w i ) log ( ∣ c y i − c y j ∣ h i ) log ( w i w j ) log ( h i h j ) ) , G i j = F C ( r i j ) , λ i j g = ReLU ( w g T G i j ) , \begin{array}{c} r_{i j}=\left(\begin{array}{c} \log \left(\frac{\left|c x_{i}-c x_{j}\right|}{w_{i}}\right) \\ \log \left(\frac{\left|c y_{i}-c y_{j}\right|}{h_{i}}\right) \\ \log \left(\frac{w_{i}}{w_{j}}\right) \\ \log \left(\frac{h_{i}}{h_{j}}\right) \end{array}\right), \\ G_{i j}=F C\left(r_{i j}\right), \\ \lambda_{i j}^{g}=\operatorname{ReLU}\left(w_{g}^{T} G_{i j}\right), \end{array} rij=⎝⎜⎜⎜⎜⎜⎜⎛log(wi∣cxi−cxj∣)log(hi∣cyi−cyj∣)log(wjwi)log(hjhi)⎠⎟⎟⎟⎟⎟⎟⎞,Gij=FC(rij),λijg=ReLU(wgTGij),
一般的Transformer encoder中 Scaled Dot-Product Attention的公式如下:
Q = U W q , K = U W k , V = U W v Z = softmax ( Q K T d k ) V \begin{array}{c} Q=U W_{q}, K=U W_{k}, V=U W_{v} \\ Z=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \end{array} Q=UWq,K=UWk,V=UWvZ=softmax(dkQKT)V
其中的 W q W_q Wq, W k W_k Wk, W v W_v Wv 是可学习的权重参数。
本文提出的Grid-Augmented module,对于encoder中的Scaled Dot-Product Attention进行了基于grid相对位置的增强,改进后的公式如下:
Q = U W q , K = U W k , V = U W v Z = softmax ( Q K T d k + λ g ) V \begin{array}{c} Q=U W_{q}, K=U W_{k}, V=U W_{v} \\ Z=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}} + \lambda^g\right) V \end{array} Q=UWq,K=UWk,V=UWvZ=softmax(dkQKT+λg)V
这样就在计算grid feature之间的attention关系时,加入了grid之间的位置关系,避免了一定的位置信息的丢失。
Adaptive Attention module
Language Feature Representation
本文使用了预训练的Bert-based模型进行文本特征的提取。由于在模型推理时,模型应该只能看到当前生成文字之前的文本,因此加入了masked类似于Transformer decoder。整体的文本特征提取如下图所示:
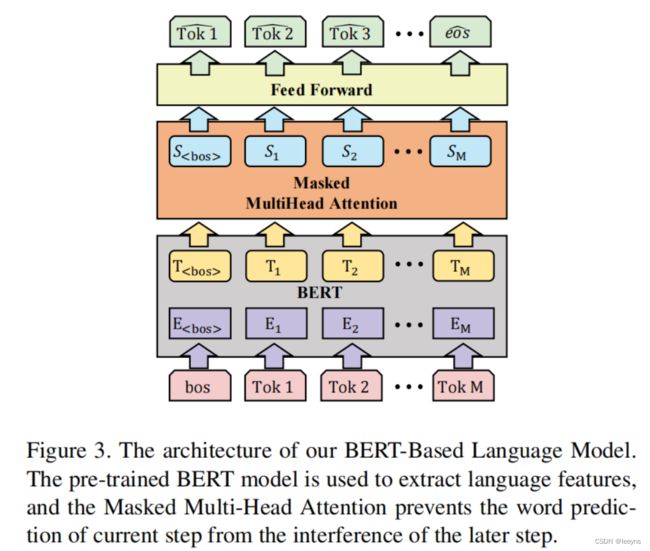
其中图中的 S S S 表示文本特征。
假设文本需要生成的句子为 W ^ = ( w ^ 1 , w ^ 2 , … , w ^ M , < cos > ) \hat{W}=\left(\hat{w}_{1}, \hat{w}_{2}, \ldots, \hat{w}_{M},<\cos >\right) W^=(w^1,w^2,…,w^M,<cos>) 那么,传统的decoder部分仅仅使用视觉特征和之前生成的文字来生成接下来的文字:
h t = D e c o d e r ( U , W < t ) h_t = Decoder(U, W_{
但是本文加入了文本特征,通过衡量视觉特征和文本特征对于接下来生成文字的重要程度来生成文字。整体的流程如下图:
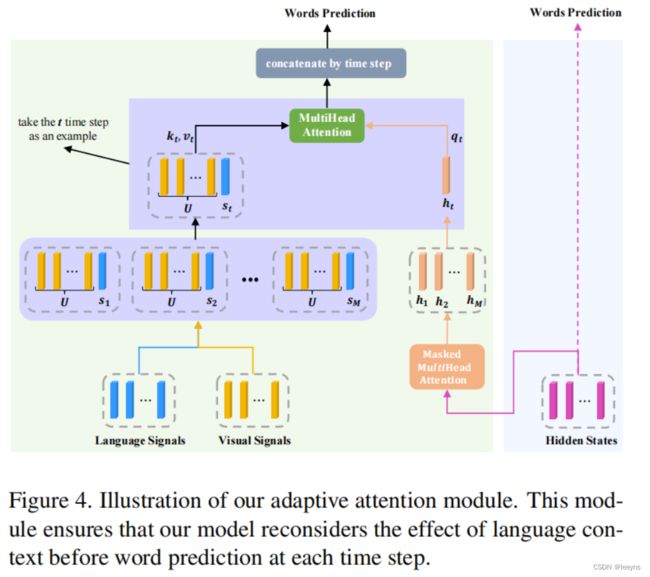
图中最右侧粉红色的输出为一般Transformer decoder生成的文字特征,我们需要将每一次生成的文字特征拿出来再通过衡量文字特征和视觉特征的重要性来决定这个字是更加基于哪一种特征生成。每次生成完当前的文本后,都需要对当前的文本进行bert-based模型的文本特征提取,即图中蓝色部分。将当前生成step的文本特征和视觉特征结合起来,再于传统decoder生成的预测的文字特征进行attention运算,即图中绿色部分,从而衡量当前生成的文字更注重visual word 还是 non-visual word. 这个过程可以用一下公式表达:
q i , t = h t W i Q , k i , t = [ U ; s t ] W i K , v i , t = [ U ; s t ] W i V head i , t = softmax ( q i , t k i , t T ) v i , t h e a d = Concate ( h i e a d i , 1 , … , head i , M ) att = Concate ( head 1 , … , head h ) W O \begin{array}{c} q_{i, t}=h_{t} W_{i}^{Q}, k_{i, t}=\left[U ; s_{t}\right] W_{i}^{K}, v_{i, t}=\left[U ; s_{t}\right] W_{i}^{V} \\ \text { head }_{i, t}=\operatorname{softmax}\left(q_{i, t} k_{i, t}^{T}\right) v_{i, t} \\ h_{e a d}=\text { Concate }\left(h_{i} e a d_{i, 1}, \ldots, \text { head }_{i, M}\right) \\ \text { att }=\text { Concate }\left(\text { head }_{1}, \ldots, \text { head }_{h}\right) W^{O} \end{array} qi,t=htWiQ,ki,t=[U;st]WiK,vi,t=[U;st]WiV head i,t=softmax(qi,tki,tT)vi,thead= Concate (hieadi,1,…, head i,M) att = Concate ( head 1,…, head h)WO
其中att则为最终的预测文本特征。
结合此图和上文中整体模型图,不难理解这篇文章的主要工作内容。核心就是:
- 在视觉特征提取时加入了每个grid与其他grid的相对位置关系;
- 在传统decoder生成的prediction representation的基础上有增加了一步特征的提取融合,通过将视觉特征和基于当前已经生成的文本所预测的下一个文字的文本特征结合起来,然后再衡量两种特征对于下一步预测的重要程度来决定下一步的预测。
结果
文中展示了,模型预测时visual word 和 non-visual word 对应图片的区别,如下图所示:
本文提出的模型与其他模型的对比如下,可以看出本文提出的模型有一定的提升,但是提升的幅度还是有限的。
