数据分析知识——统计学学习笔记(拉勾数据分析训练营)
模块1 统计学基本概念
1 测量尺度
人文社科中的分类尺度
1定类尺度
功能:分类作用,比如性别。英文:Norminal
2定序尺度
功能:分类、排序作用,比如喜欢的艺人、年级。英文:Ordinal
3定距尺度
功能:分类、排序、加减,比如温度。英文:Scale
4定比尺度
功能:分类、排序、加减、乘除,比如年龄、体重等。有绝对零点。英文:Scale
实际应用说明
分类说法:定类与定序合称分类变量,定距与定比合称连续变量。Tableau就是这样分类:分类-维度,连续-度量。
描述统计方法:
- 分类变量:只能用频次统计
- 连续变量:既可以用频次统计,也可以用均值和标准差。
2 平均值
分类概念
1算术平均
2几何平均
n个数据的乘积开n次方。计算多年增长率的复合增长率
3调和平均
互联网数据分析用的很少,一般当数据在下限值附近的时候,例如是右偏分布的时候(波峰偏左),这个均值比前两个都小。
4调整平均
又称trim平均,从上限值和下限值中去掉一定比例(通常5%)的数据后剩下的数据的算术平均。可以去除最大最小值的原因是因为这些值可能是异常值。
3中位数和众数
概念
1中位数
当一组序列数据之间差异较大时,导致平均值代表性较弱,可通过中位数来表示数据的集中趋势
2中位数和众数的应用差异
平均值、中位数通常应用在连续变量中,即数值型变量。众数既可以用在连续变量,也可用在分类变量中。
4极差和标准差
对数据的离散状态进行分析,本课程内只介绍最常用的两个。
概念
极差
指分布的最大值和最小值的距离。
标准差
作为表示各个数据相当于平均值的离散程度的指标。
要点
- 对于不同样本量的两个样本做离散程度对比时,直接用标准差是不合适的。可以用离散系数,即,标准差/平均值,来代表。
- 在计算过程中,用n去除的公式适合于总体数据的场合,而用(n-1)去除的公式则适合于从总体中抽取样本的场合。原因是总体的样本量比较大,其离散程度肯定大于抽样样本。除以(n-1)可以人为的少量放大样本的离散程度,从而更贴近总体。
模块一2 总体推断
统计推断/假设检验
z值转换公式:用来将t分布转换为z分布,即(标准差0,均值为1),又称为标准化,或Z值标准化。Z=(xi-x)/s(xi原始样本数值,x样本均值,s标准差),用于判断哪些数值为异常值。Z值绝对值大于3为异常值,大于5为极端值。
t分布
Excel两个函数:TINV(概率值求t值)、TDIST(t值求概率值)
置信度
T=1.65,对应90%的置信度,T=1.98,对应95%的置信度,T=2.58,对应99%的置信度
假设检验的步骤
- 定义H0和H1:原假设H0一般定义没有相关性或没有显著差异,研究假设H1定义为有相关性。
- 选择合适的检验方法,计算统计量(t值、F值等)。置信度即显著性水平,一般取t为1.98。
- 根据统计量计算概率P值,或者取值区间。
- P值与显著性水平(通常0.05)进行对比,P<0.05,则拒绝原假设H0,接收研究假设H1;反之,P>0.05,则接受原假设H0。
模块一3 抽样方法
10万以下一般都属于小样本
1分层抽样
如何选择分层变量,考虑因素:
- 选择那些与研究主题高度相关的变量,比如研究收入问题时,考虑学历、年龄、性别等影响收入的基本属性。
- 成本:分层因素考虑越多,选取的样本量则越多,学历(高、中、低3类)、收入(高中低3类)、性别(男女2类).则共有总共18类,每类样本量至少保证30人以上(一般认为只有30人以上的单元才有统计学意义),此时就需要18*30=540人的样本。
因此可以将与研究主题不太相关的主题可以不考虑,或者将因素的分类减少。
模块一4 卡方检验
很多场景都用,非常经典的方法。
假设检验的结论:P<0.05,则研究假设成立;反之,p>0.05,则研究假设不成立。
应用场景
属于非参数检验,适用于不知道总体参数的检验,是最常用的一种非参数检验。当不适用参数检验法时,第一个想到的就是卡方检验。
常见的单样本非参检验方法
1 比例分布检验(卡方检验)
检验一个变量是否包含相同频率或与用户指定比例一致。
操作:分析-非参数检验-旧对话框-卡方检验
原假设:变量的取值分布与均匀分布(或研究者设定的分布)没有显著差异
研究假设:变量的取值分布与均匀分布(或研究者设定的分布)有显著差异
P<0.05,则研究假设成立。
2 二项式检验
检验一个变量取二分类两个值的概率是否符合设定的概率。概率有时候是50%,有时候可以是别的值。
操作:分析-非参数检验-旧对话框-二项
原假设:变量的第一个取值比例与设定比例没有显著差异
研究假设:变量的第一个取值比例与设定比例有显著差异
分割点:是将一个连续变量,选择一个值分割为大于该值和小于该值。
3 K-S检验
检验样本来自的总体中,一个变量的分布是否服从正态分布、均匀分布、泊松分布、指数分布。
原假设:变量来自总体的分布与正态分布(或均匀分布等)没有显著差异,即变量在总体中呈现正态分布(或均匀分布等)。
研究假设:变量来自总体的分布与正态分布(或均匀分布等)有显著差异,即变量在总体中不呈现正态分布(或均匀分布等)。
4 游程检验
检验某一变量的两个值的出现顺序是否随机。
研究假设:变量两个值出现顺序不是随机的
5 独立样本非参数检验
独立样本:两组不同不重叠的样本,比如男性和女性
检验两组样本在收入、年龄等分布上是否有差异。即检验不同人群在特定变量取值上是否有差异。
研究假设:两组来自总体的变量数据在分布上有差异,即两组数据在该变量的去之上有显著差异
操作:分析-非参数检验-旧对话框-2个独立样本
注意:分组变量是分类变量、比较变量是连续变量
6 配对样本非参数检验
配对样本:同一组人群在不同时间采集的两组或多组数据;或者同一组人群不同身体部位采集的两组或多组数据。
检验同一组人群在不同时间、不同部位采集的数据是否有差异。
研究假设:来自总体的同一组人群的两组数据在分布上有差异,即两组数据在该变量的取值上有显著差异
操作:分析-非参数检验-旧对话框-2个相关样本
注意:t1、t2,比较的变量必须是连续变量
7 交叉分析(列联表分析)
检验两个分类变量是否存在相关性。
如果场景中需要对连续变量进行卡方检验,首先需要将连续变量转换为分类变量,如年龄分为70后、80后、90后、00后……
连续变量转成分类变量的操作:转换-重新编码为不同变量,收入分为0-50,50-100,100以上等。
如果两个变量都是定类变量,相关系数可通过卡方检验中“名义”里的四个相关系数;如果两个都是定序变量,则选择“有序”里的四个相关系数。
问:如果两个变量中,一个为定类变量,一个位定序变量,相关系数应该选哪个?
答:应该用“名义”中的四个相关系数,原因是定序变量可降级为定类变量,而定类变量不可以升为定序变量。
卡方检验结果解读
第一步:看卡方统计结果,根据P值判断两个变量是否存在相关性,如P<0.05,则说明两者存在显著相关性
第二步:看相关系数,判断两者之间相关性到底有多大。0-0.2,较弱相关;0.2-0.4,弱相关;0.4-0.6,相关性一般;0.6-0.8,较强相关;0.8-1,极强相关。
第三步:看频次分布,具体分析两者存在什么样的相关。
模块一5 t检验
假设检验的结论:P<0.05,则研究假设成立;反之,p>0.05,则研究假设不成立。(有时P值也称Sig,significance)
单样本均值t检验
某个连续变量的样本均数与给定总体的已知均数相比,其差异是否有显著。
用到的变量:一个连续变量
数据要求:小样本时来自的总体服从正态分布,如果大样本或者是数据收集的时候没有特殊性,可以忽略正态分布的假设。
操作:分析-比较平均值-单样本t检验
独立样本均值t检验
用来检验两组独立样本在某个连续变量的均值是否有显著差异。
用到的变量:一个连续变量和一个分类变量(也可以将连续变量进行分组(分割点)变成分类变量)
原假设:两组独立样本来自的总体在该变量的均值上没有显著差异
研究假设:两组独立样本来自的总体在该变量的均值上有显著差异
操作:分析-比较平均值-独立样本t检验
方差齐性检验
用于判断看哪个t值
原假设:两组总体中的方差是相等的
研究假设:两组总体中的方差是不等的
当p<0.05,则研究假设成立,即两组总体中的方差是不等的,需要看第二行的t值检验结果。反之则看第一行的t值结果。
配对样本均值t检验
用来检验同一组样本不同时间/部位/处理条件测量得到的两组数据均值是否存在差异。
原假设:两组配对数据之间没有显著差异
研究假设:两组配对数据之间有显著差异
变量:两个连续变量(其实是针对同一组人群不同时间/部位/处理条件测量的两组数据)
操作:分析-比较平均值-成对样本t检验
模块一6 方差检验
又称F检验、ANOVA。
变量要求:自变量既可以是分类也可以是连续变量,因变量必须是连续变量。
因素:因素是可能对因变量有影响的变量
水平:因素的不同取值等级称作水平
单元:亦称为实验单位,指各因素的水平之间的每种组合。
交互作用:
- 如果一个因素的效应大小在另一个因素不同水平下明显不同,则称为两因素间存在交互作用。当存在交互作用时,单纯研究某个因素的作用是没有意义的,必须分另一个因素的不同水平研究该因素的作用大小。
- 如果所有单元格内都至多只有一个元素,则交互作用无法进行分析,只能不考虑
单因素方差检验
检验3组及以上人群在某个连续变量均值上是否存在差异,或某个分类变量对某个连续变量是否存在显著影响(显著相关)
变量:**因变量是一个,且为连续变量;**自变量是一个,为分类变量(如果是连续变量要分组)
研究假设:自变量与因变量之间存在显著相关(不同人群之间在该连续变量的均值上有显著差异)
操作:分析-比较平均值-单因素ANOVA检验
- 两两比较中根据方差齐性检验结果,来选择方差相等的比较结果或方差不等的检验结果。
- 方差齐性检验在:选项-方差齐性检验。当方差不齐时,则通过非参数检验中的K个独立样本检验法进行检验。
多因素方差检验
检验多个变量在某个连续变量均值上是否存在差异,或多个变量对某个连续变量是否存在显著相关。
变量:**一个因变量,且为连续变量;**自变量有多个(既可以是分类变量也可以是连续变量)
研究假设:多个自变量与因变量之间存在显著相关
拆开来看研究假设:
因子A对因变量有影响;因子B对因变量有影响;因子A与因子B有交互作用(三个因素的交互影响一般不考虑)
操作:分析-一般线性模型-单变量
也要进行方差齐性检验
选用模型
当自变量特别多时,尤其是分类自变量特别多,且样本量不多时,应该使用定制模型。
全因子模型:既考虑所有自变量对于因变量的直接效应,又考虑所有分类变量的交互作用对因变量的影响。
(构建项/构建定制项)定制模型:可根据研究者自身需求,定制需要考虑的对因变量的影响因素。比如只考虑自变量的直接效应,或部分自变量的交互作用。
模块二1 多变量分析方法的选择
- 有因变量,则建立有监督模型。有监督模型有两大通用目的:1)分析哪些自变量对因变量存在显著影响作用;2)通过选择对因变量存在显著影响的自变量,建立预测因变量取值的预测模型。
- 因变量为连续变量,建立的模型称为回归预测模型:
- 自变量为连续变量时,可选择回归分析、方差分析;
- 自变量为分类变量+连续变量,可选择带虚拟变量的回归分析、联合分析、方差分析
- 因变量为分类变量(定性数据),建立的模型称为分类预测模型:
- 自变量为连续变量(或连续+分类)时,可选择判别分析、Logistic/probit analysis
- 自变量为定性数据时,可选择对数线性回归(Logit)。预测因变量是如何分类的,在人文社科常用。
- 因变量为连续变量,建立的模型称为回归预测模型:
- 无因变量,则建立无监督模型。只要是无监督分析,都叫做描述分析,分析方法得到的结果没有客观标准判断结论是否准确。目的:1)对人进行分类;2)对变量/指标进行分类;3)分析变量与变量之间的测量关系
- 自变量为连续变量时,选择因子分析(其中一个目的就是对变量/指标分类)、聚类分析(对人分类、对变量/指标分类)
- 自变量为分类变量时,选择对应分析(对人分类)、多维尺度分析(对人分类)
- 其他分析
- 当模型中需要加入潜在变量(通过多个客观指标测量的抽象概念整体)、或需要考虑多个变量之间的因果关系分析模型,建立结构方程模型、路径模型、协方差分析。
- 综合评价:通过多个指标对多个评价对象进行排名,可选择层次分析法(AHP)、因子分析等。
模块二2 相关系数
相关系数是衡量两个变量之间变化趋势的相关性
不同变量类型的相关系数
- 两个变量都为连续变量,则可用Pearson相关系数。在统计中常用r这个符号来表示。
- 两个变量都为定序变量,则可用GMMA、Spearman、Kendall’s tau-b等相关系数
- 两个变量都为定类变量,则可用LAMMDA等相关系数
- 一个变量为定类变量,一个变量为连续变量,可通过ETA系数来测量相关性
三种重要相关系数
- Pearson相关系数:参数检验,针对两个都是连续变量的数据进行相关性判断
- Spearman相关系数:非参数检验,针对两个都是定序变量
- Kendall’s tau-b相关系数:非参数检验,针对两个都是定序变量
其他概念
常用方法:散点图;计算相关系数
相关分析的假设检验
原假设:两个变量来自总体中不存在显著相关性
研究假设:两个变量来自总体中存在显著相关性
显著性检验目的:是用来判断两个变量在总体中是否存在相关性
相关系数:是计算两个变量在样本数据中的相关性强弱
操作:分析-相关-双变量
偏相关分析的假设检验
注意:计算相关性的变量为连续变量,加入控制的变量同样也是连续变量
操作:分析-相关-偏相关性
模块二3 回归分析
*目的:*当需要用一个数学表达式(模型)表示多个因素与另外一个因素之间关系时,可选用回归分析法。
*R2:*自变量对因变量的解释能力,即r(相关系数)的平方。注意r不一定是一元一次回归模型里x前面的值,x前面的值是要考虑x和y的量纲的。
*应用:*和有监督模型的两个通用目的相同:
1)分析哪些自变量对因变量存在显著影响作用,R2值可以不要求大于0.8;
2)通过选择对因变量存在显著影响的自变量,建立预测因变量取值的预测模型,模型R2必须要求大于等于0.8。
但是,在人文社科领域,很多回归模型的R2值达不到0.8,也可以用来做预测。
回归分析的建立步骤
- 选择变量
- 因变量:根据研究需求或问题推导出来
- 自变量:1)前人的研究成果;2)个人经验
- 确定变量之间关系
- 挨个将自变量与因变量画散点图,判断每个自变量与因变量之间是线性还是非线性关系
- 通过卡方检验、T检验、F检验或相关分析法,挨个分析每个备选的自变量与因变量之间是否存在显著的相关性。将与因变量明显没有相关性的自变量剔除掉,不加入到后期模型中。
- 选择对应的线性或非线性方程,进行各项参数计算
- 回归方程计算,对模型进行全方位检验
- 多重共线性检验:检验多个自变量之间是否存在相关性较高的变量,如有,则保留与因变量相关性最高的一个自变量。
- 模型拟合优度检验:方差检验/判定系数(R2)/残差检验/自变量参数检验
回归分析的软件操作
画图位置:图形-图表构建器
解决问题:分析影响人们家庭收入的因素有哪些,建立预测收入的回归方程
因变量:家庭收入
自变量:年龄、工作年限、性别(因为只有男女01)、学历(变成虚拟变量)
操作:分析-回归-线性
“统计”中勾选共线性诊断、DW
“图”中勾选标准化残差图下的:直方图、正态概率图
虚拟变量
原因:分类变量无法参与到回归模型中的加减乘除运算
操作:将原先的分类编码统一转换为0、1数值
Ed=12345,转换为4个变量,选择第三个值为对照(也可以选其他值为对照人群)
还可以转换为5个变量,这时没有对照人群,都有一个1。
1 2 3(对照人群) 4 5 Ed1 1 0 0 0 0 Ed2 0 1 0 0 0 Ed3 0 0 0 1 0 Ed4 0 0 0 0 1 SPSS软件操作:选中要转换的字段列-转换-重新编码为不同变量,定义新值和旧值的对应关系
回归分析的结果解读
-
拟合优度检验:
- R2值
- F值:F值对应的概率P值小于0.05,研究假设成立,即至少有一个自变量对因变量存在显著影响
-
参数显著性检验:
-
根据每个自变量的t值对应的概率P值是否小于0.05,如小于0.05,则研究假设成立,即该自变量对因变量存在显著影响。
根据下表得出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NPJl7JWu-1613448172329)(G:\个人文档\拉勾教育数据分析训练营\第六阶段 统计学\统计学个人笔记.assets\image-20210209091708359.png)]
工作年龄和学历对收入有显著影响,而年龄和性别没有。通过标准化系数来判断两者对影响程度大小,可知工作年限的影响明显大于学历。
工作年限对收入影响程度(未标准化系数的B):在其他变量不变的情况下,工作年限每增加一个单位(1年),则因变量家庭收入平均增加6.279个单位。
学历对收入的影响程度(4个虚拟变量):Ed1 = -51.042表示Ed1代表的学历(高中以下)比对照的学历人群(大专学历)在因变量家庭收入上,平均低51.042个单位 ——其他同理
-
-
共线性检验:通常根据VIF>10,自变量之间存在共线性。如果存在共线性,可用逐步法解决。
-
残差检验:DW越接近2,表示残差越不存在自相关性。——主要看两个图表:直方图、正态P-P图
-
将对模型没有显著影响的因素剔除掉
操作:用逐步回归法,在线性回归的方法中选“步进”,从自变量中将对模型没有影响的因素删除掉。
以下结果为三次逐步回归后,R方值很接近1得到的结果。第三个模型是最准确的
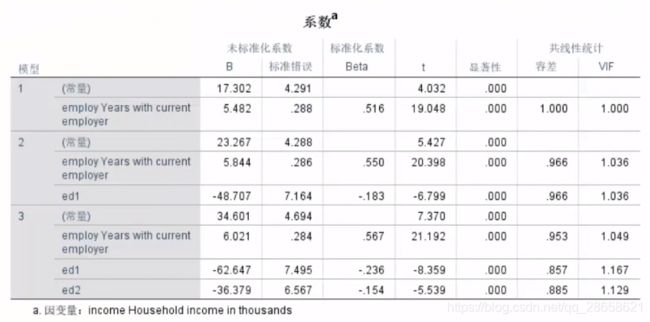
-
回归方程:y=34.601+6.021
*工作年限-62.647*ed1-36.379*ed2 -
发现模型中没有ed3和ed4,那就无法完整反应学历的影响。需要强制将他们放到模型里。操作是:
任务三-6-32:42,在回归分析中将四个学历放在下一层(SPSS软件里选“下一个”),方法选强制。得到如下结果
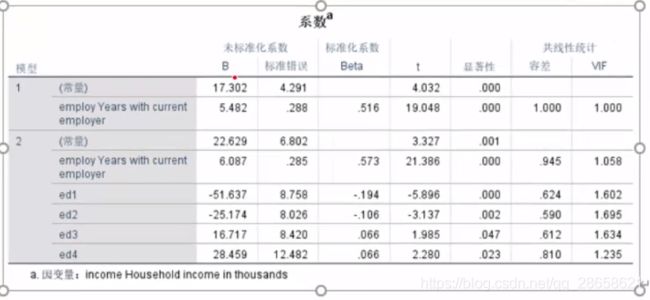
-
回归方程:y=22.629+6.087*工作年限-51.637
*ed1-25.174*ed2+16.717*ed3+28.459*ed4
非线性回归
求解方式:
- 线性转换:原因是非线性方程拟合方法和参数初始值设置均会导致求出的结果并非全局最优解,因此尽量将非线性方程转换为多元线性回归方程。
- 直接建立非线性方程,求解非线性模型。
操作:先通过散点图判断是否存在非线性关系(用telecon数据)
SPSS操作1:分析-回归-曲线估算
自变量:Ininc;因变量:Income
Income = eIninc
SPSS操作2:分析-回归-非线性
- 因变量:Income
- 自己写模型表达式a*EXP(b
*Ininc)- 点“参数”设置初始值
模块二4 因子分析
目的:对多个具有较高相似性的变量/指标进行降维,前提是这些变量/指标之间必须存在一定的相关性/相似性
应用场景
- 降维后做综合评价
- 效度检验:对抽象概念的测量工具进行有效性检验,判断哪些指标需要保留或删除,并对保留的指标进行维度划分
- 降维后做其他分析:由于变量存在较高相关性,不适合做回归分析、聚类等其他分析,需要用因子分析消除变量间较高的共线性
因子旋转的目的
- 使得因子可以更好地代表原来的变量
- 降低或消除提取的因子之间的相关性
SPSS软件操作
分析-降维-因子
- 判断相关性:描述-相关性矩阵-KMO和巴特利特球形度检验
- 旋转-最大方差法
- 得分-保存为变量
- 选项-按大小排序、排除小系数
结果解读
-
KMO>0.7,适合做因子分析
-
累计方差贡献率需要达到多少才合适:
- 做综合评价:>80%(类似于回归分析需要R2>0.8)
- 效度检验或其他分析:>60%,效度检验更宽泛,甚至可以不要求
-
判断因子数量:碎石图拐点位置的因子数量(现在已经比较少用);因子特征值>1;因子的累计方差贡献率
-
因子的划分:根据每个变量在每个因子中的取值是否大于0.5
-
效度检验(应用场景2)(用因子旋转载荷矩阵):
用于判断保留哪些变量,这种方法也主要应用于探索性因子分析
- 第一判断标准:每个变量有且只有一个因子载荷值大于0.5,如果所有因子载荷值均小于0.5,则说明该变量不具有收敛效度,需要删除;
- 第二判断标准:变量在两个或以上因子中的载荷值同时大于0.5,则说明该变量不具有区分效度,需删除;
- 第三判断标准:某变量单独成为一个因子,则说明该变量也不存在收敛效度
-
因子原始得分计算(用因子得分系数矩阵,一般每个值都不大于0.5):F1 = x1*a1 + x2
*a2…… -
因子轴旋转后的因子得分:在变量视图里可以找到几个
Logistic回归(逻辑回归)
应用场景:
做分类预测模型,且为非参数检验方法。可以用于二分类、无序多分类、有序多分类。
SPSS软件操作
二元(因变量有两个值)
位置:分析-回归-二元Logistic
首先选“输入”方法,统一看下自变量对因变量的影响程度
结果解读
-
很重要的一个结果是“分类表”,用来判断逻辑回归模型的准确率。
-
看另一个表“方程中的变量”:
- 根据参数检验中的p是否<0.05,得到自变量对因变量是否存在显著影响。
- 根据“瓦尔德”(Wald)值的大小,判断自变量对因变量的影响程度
然后再次进行逻辑回归操作,选“向前”或“向后”方法,剔除影响程度小的变量。
之后如果发现有的变量被剔除了,可以用分层的方法(选“下一个”),用“输入”方法,强制将某变量加进来
-
优势比(OR值,在表格中是Exp(B))大于1,表示该自变量会增加因变量取1的概率的发生;反之会降低因变量取1的概率。
-
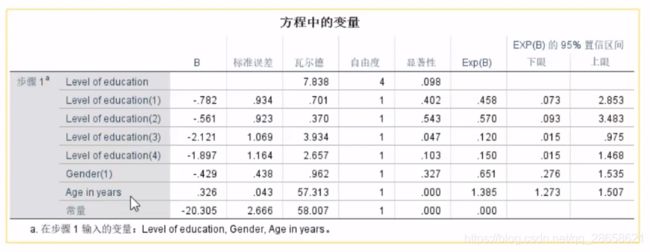
连续自变量对因变量的影响程度解读:在其他变量不变的情况下,当年龄增加一个单位(1岁)时,优势比增加1.385倍(年龄越大、退休概率越高)
-

分类自变量对因变量的影响程度解读:
在Level of education的4个虚拟变量中,只有第3个虚拟变量有显著影响。虚拟变量的对照组是"Post-undergraduate",第3个虚拟变量是"Some college"。所以这个结果的解读是:在其他变量不变的情况下,大专学历的优势比是研究生学历优势比的0.120倍,即大专学历高于研究生学历的退休概率
-
Logistic公式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Idmi5va0-1613448172339)(G:\个人文档\拉勾教育数据分析训练营\第六阶段 统计学\统计学个人笔记.assets\image-20210213111220030.png)]
l n ( p / ( 1 − p ) ) = − 20.305 − 0.782 ∗ e d 1 − 0.561 ∗ e d 2 − 2.121 ∗ e d 3 − 1.897 ∗ e d 4 − 0.429 ∗ g e n d e r + 0.326 ∗ a g e ln(p/(1-p)) = -20.305-0.782*ed1-0.561*ed2-2.121*ed3-1.897*ed4-0.429*gender+0.326*age ln(p/(1−p))=−20.305−0.782∗ed1−0.561∗ed2−2.121∗ed3−1.897∗ed4−0.429∗gender+0.326∗age -
最后SPSS会自动生成两个变量:
PRE是指每个人的概率,概率和0.5比较,如果>0.5,则因变量取值。这个0.5是在回归分析中的“选项”里设置“分类分界值”
PGR是指每个人的因变量取值
多元无序回归
位置:分析-回归-多元Logistic回归
参考类别选哪个都可以,结果没差别。
统计里的几个模型可以定制看各个变量的影响
因子选分类变量,协变量选连续变量。
保存里选择“预测类别”和“预测类别概率”,和二元回归一样。
结果解读
似然比检验,根据其显著性的值,可以判断几个自变量和因变量有没有相关性。
参数估算值有两个大表,原因是其实相当于建立了两个二元逻辑回归。
有序多分类回归
操作位置:分析-回归-有序
在“输出”勾选“平行线检验”、“预测类别”和“预测类别概率”。位置,选主效应。
结果解读
-
“模型拟合信息”表:显著性<0.05,说明至少有一个自变量对因变量有影响作用
-
“拟合优度”表,显著性>0.05,说明模型的拟合状态还不错。
-
“伪R方”,一般不看这个结果。
-
“参数估算值”:
-
阈值一栏里:对有序变量逐次切割之后做的二元回归
-
位置一栏里:“显著性”<0.05的,说明该变量对因变量有显著影响,可将“显著性”>0.05的变量去除后,再重新做一次回归预测
-

“平行线检验”,检验当因变量划分不同取值时建立的多个二元Logistic回归,自变量对因变量的影响程度是相同的。如果该检验不成立,则不能选择有序多分类模型,改用无序多分类模型。当P>0.05,说明原假设成立,则平行性检验成立,可以建立有序多分类模型。
-
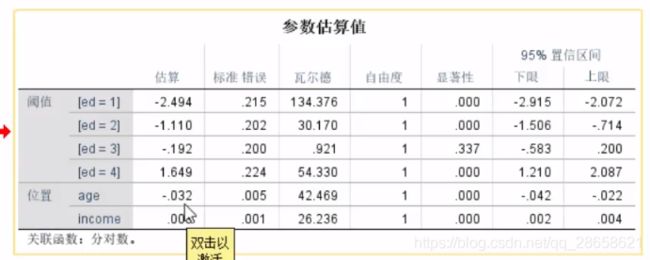
“参数估算值”:这里没有直接计算出优势比(Exp(B)),但是“位置”一栏的“估算”就是B。所以可以根据估算值的正负来判断:如果为正,则该参数增加因变量取大于1的概率,如果为负则增加因变量取小于1的概率。
-
模型公式:
-
l n ( p 1 / ( 1 − p 1 ) ) = − 2.494 − 0.032 ∗ a g e + 0.003 ∗ i n c o m e ln(p1/(1-p1)) = -2.494-0.032*age+0.003*income ln(p1/(1−p1))=−2.494−0.032∗age+0.003∗income
p1表示学历取1的概率
-
l n ( p 2 / ( 1 − p 2 ) ) = − 1.110 − 0.032 ∗ a g e + 0.003 ∗ i n c o m e ln(p2/(1-p2)) = -1.110-0.032*age+0.003*income ln(p2/(1−p2))=−1.110−0.032∗age+0.003∗income
p2表示学历取1和2的概率
-
l n ( p 3 / ( 1 − p 3 ) ) = − 0.192 − 0.032 ∗ a g e + 0.003 ∗ i n c o m e ln(p3/(1-p3)) = -0.192-0.032*age+0.003*income ln(p3/(1−p3))=−0.192−0.032∗age+0.003∗income
p3表示学历取1、2、3的概率 -
l n ( p 4 / ( 1 − p 4 ) ) = 1.649 − 0.032 ∗ a g e + 0.003 ∗ i n c o m e ln(p4/(1-p4)) = 1.649-0.032*age+0.003*income ln(p4/(1−p4))=1.649−0.032∗age+0.003∗income
p4表示学历取1、2、3、4的概率
-
-
模块二5 时间序列分析
普通ARIMA模型和因果关系ARIMA模型的区别就是,自变量是否要考虑因果关系的滞后性(普通的不考虑)
格兰杰因果检验
因果关系成立的三个条件:
- AB两个事件必须存在相关性
- 原因A必须发生在结果B之前
- 排除其他干扰因素(没有A导致B,或A+C导致B)
平稳序列
ARIMA模型建立的前提是时间序列数据必须为平稳序列,可通过单位根检验(ADF)来判断一个序列是否平稳。如果不平稳,可通过差分进行转换。
ARIMA中的I就是差分进行了几阶差分,如果没有差分就是0
周期性计算
通过自相关系数(ACF)的拐点,乘以4得到周期。
SPSS软件操作
普通ARIMA模型
-
定义时间:数据-定义日期和时间
-
建立模型:分析-时间序列预测-创建传统模型
- 加入因变量和自变量(自变量可以不加,在这里添加的自变量是不考虑滞后性的,只有和因变量的相关性)
- 方法选“专家建模器”,条件可以自订
- “统计”里的勾选项用于判断模型的好坏
- “图”一般画预测值和拟合值
-
结果解读:
- (看“模型统计”表)时间序列的假设检验:通过杨-博克斯模型(Ljung-Box Q(18)),原假设是模型可以很好地拟合原始数据,p>0.05表示模型可以接受,P值越大模型越好。R方值仍然是0~1之间,越大越好。
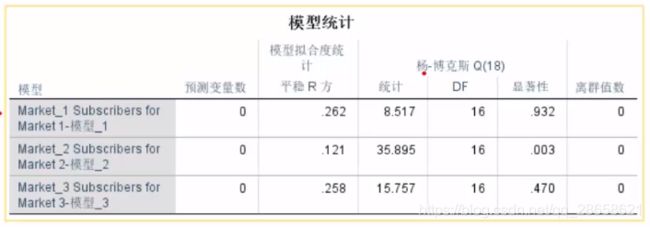
-

模型1:Yt = 8.579+0.999
*Yt-1+0.6333*Yt-12(12个月为一个周期,所以这里是t-12) -
只有当数据窗口中有空的时间数据时,选了预测之后才会有预测结果,不然的话就没有预测。预测结果在输出窗口中,数据窗口中没有。
因果关系ARIMA模型
-
操作位置:分析-时间序列预测-创建时间因果模型
- 字段窗口:
- 目标:因变量,最好选择连续变量
- 候选输入:自变量的候选项,有可能是自变量
- 目标和输入:选入的变量既是自变量又是因变量
- 强制输入:一定需要作为自变量,不管有没有影响
- 字段窗口:
-
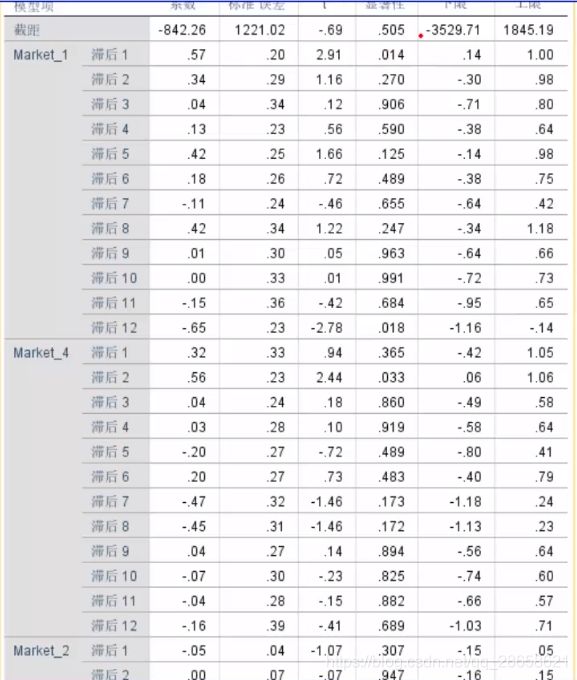
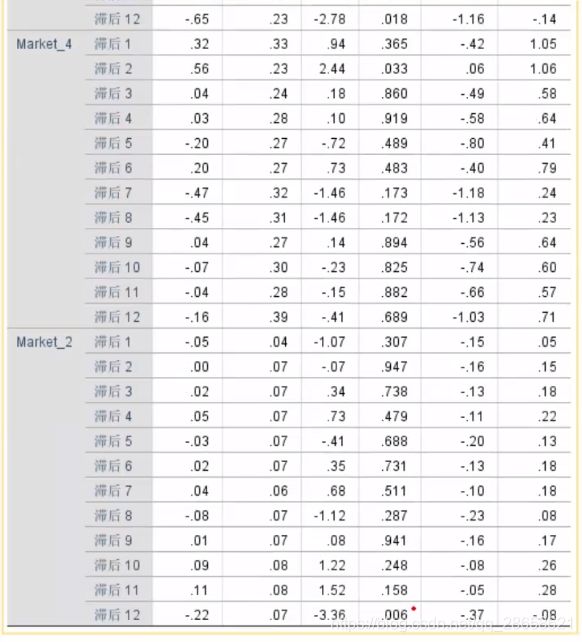
时间序列因果模型:Y1t = a1*Yt-1+a2*Y1t-12+a3*Y4t-2+a4*Y2t-12+a0
之后再进行拟合,做多元回归线性模型测试
分析-时间序列预测 下的其他几个功能的简介
都用的不太多
交叉相关性
用来分析不同变量之间是否存在滞后性相关
自相关性
用来画自相关(ACF)图和偏自相关图。这两个图一般做分析的时候是要画
序列图
用来画时间序列图
谱图
用的非常少,但功能很重要,主要用在分析音频上。可以作为第二种判断周期性的方法(第一种是看ACF图)。通过频率取值最高的点对应的频率乘以数据量,得到周期
季节性分解
一般是在建模前进行的操作,看数据是否在季节上有周期性。不过实用性不强,这一步可以直接交给模型做判断。