机器学习笔记之监督学习和无监督学习
学习机器学习的过程中,打算记录一些笔记,又想赚点积分,于是厚颜无耻写几篇博客。限于水平,可能会有表达不清楚甚至错误的地方,希望大家指正,其实这才是真正的目的。班门弄斧,希望大家多多包涵。
基本定义。
机器学习(machine learning)
“一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升”这是在吴恩达的视频和周志华的书上均有提到的概念。简言之,程序从经验中学习从而改善一个任务的性能。经验可以被认为是一组数据。大方向上机器学习分为监督学习(supervised learning)和非监督学习(unsupervised learning)。
抛砖引玉
吴恩达的视频中给了三个例子。
例一、房价预测,将一组搜集到的房价数据绘制成图如下:
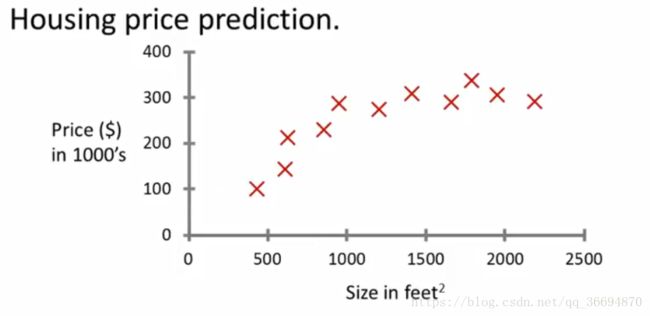
看到这一组数据的时候不免想到数学中的求函数问题(拟合一个函数)。

在这一副图中拟合了一条直线和一条曲线,并且给定的一个自变量(房间的大小)即可根据线条来预测输出(房价),同时在这组数据中有两个关键点:
(1)对于每一个输入都有对应的输出(X:size Y:price ,X—>Y )
(2)输出的值有很多个,近似的可以认为输出是连续值(continuous value)
例二:肿瘤性质预测,根据肿瘤的大小来判断肿瘤是恶性还是良性,下面是搜集的数据绘图
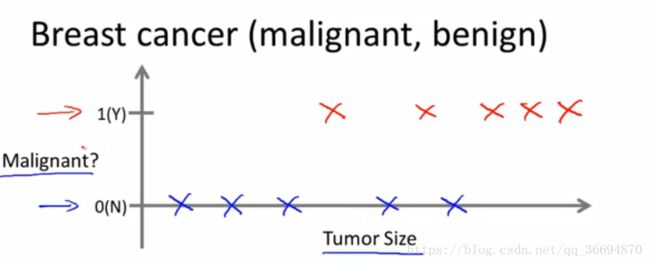
我们希望可以通过这个图来根据给定的肿瘤大小来预测良性还是恶性,我们直观上考虑用一条竖直的线来将图中的点分成两组,吴恩达视频也是这样处理的。
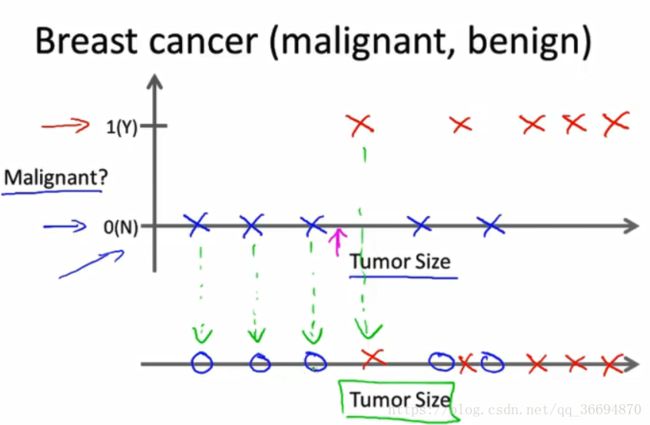
在这组给定的数据中同样有两个点:
(1)给定的输入(肿瘤大小)对应一个输出(肿瘤性质)
(2)输出值只有良性和恶性两种,是离散值(discrete value)
对于例一和例二的异同:
共同点:给定的数据中,对于输入都有一个对应的输出,或者说对于给定的每一个数据都有一个标签(label);可以被用来预测新输入的输出值。
不同点:输出值有连续值也有离散值。
例三:给定一组数据,绘图如下:

图中的圈是一个颜色,用来表示我们只有输入,对于输出并不知情
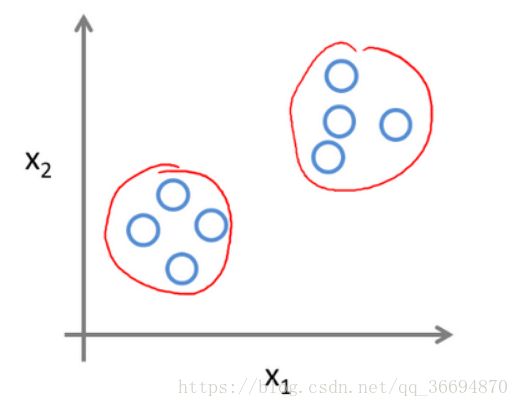
程序通过对数据进行比较共同点,将这一组数据根据某种结构分成两组。
这个例子不具备前面两个例子所有的任何一个点。但是程序还是完成了分类。
监督学习和无监督学习
一组数据称为“数据集”(dataset),其中的每一条数据(记录)称为一个示例,也称为一个样本(sample)。
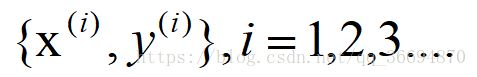
对于每一个样本可能会有标签(既有输入,也有对应的输出),也可能没有标签(只有输入数据,没有对应的输出),输入称为特征(feature)。
Def:学习过程根据有无标签分为监督学习和无监督学习。前两个例子属于监督学习,第三个是无监督学习。
而前两个例子又有不同点,即例一的输出(标签)可以看做是连续值,而例二中输出却是离散值
监督学习又根据输出是连续值还是离散值分为回归(regression)和分类(classification)这两类问题,例一是回归问题,例二是分类问题。
在非监督学习中学习算法会将数据集自动地根据数据集来抽出一组结构来将数据集分为若干组(clustering 聚簇)。
参考资料
吴恩达老师在Coursera上的Machine learning视频
周志华老师的机器学习(西瓜书)