Learning to Customize Model Structures for Few-shot Dialogue Generation Tasks
Learning to Customize Model Structures for Few-shot Dialogue Generation Tasks
Abstract
对于开放域对话系统来说在小数据集上训练生成模型是一件比较困难的事情。已经存在的meta-learning,它通过在非目标任务上进行预训练然后在目标任务上进行参数微调。但是,微调从参数的角度区分了任务,但忽略了模型结构的,导致对于不同任务却产生了相似对话的模型。在这篇文章中,作者提出一个算法,在few-shot setting 中对于每个任务定制化的生成唯一一个模型。在这篇文章的方法中,每个模型包含3个模块:shared module(共享模块),gating module,private module(私有模块)。前两个模块对于所有模块都是共享的,然而第三个模块不同的网络结构具有不同的私有模块,从而可以更好的捕获相应任务的特征。作者在两个外部数据集上展示了该方法在任务的一致性、response的质量和多样性都优于所有的baseline。
Introduction
生成对话模型需要大量的数据训练,但是通过有限的数据训练一个新的领域或则新的任务是比较困难的。[Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2018]提出在来自非目标域的大规模数据集上预训练一个生成模型,然后在特殊任务语料库数据集上微调它。预训练在有些时候是有益的,但是在给定样本很少的情况下达不到让人满意的性能。在定制化的对话中,我们需要在几次对话中很快的适应用户任务角色的response 风格。本文可以在k次对话的中训练一个生成对话模型。
在之前的一些工作中,他们将few-shot 对话生成看作是meta-learning问题,提出了model-agnostic(模型无关的) meat-learning(MAML)。利用不同的用户角色处理不同的学习对话作为不同的任务。他们在新任务中使用MAML通过最大化损失函数的灵敏度来查找模型的初始化参数。对于目标任务,可以通过微调MAML的初始参数及其特定任务的训练样本来获得其对话模型。
MAML在few-shot的对话生成上取得了不错的效果,但是效果仍然是有限的。生成对话模型最终的目标是构建一个函数映射,这个函数映射由模型结构和参数决定。而MAML只能搜索最优的参数,而忽略了模型结构,不能找到一个最优的模型结构。相比于图像相关的任务而言,语言数据本身是离散的,而且对话模型很少受到输入改变的影响,这意味着从几句话计算出的梯度可能不足以将输出单词从一个改变为到另一个。因此,需要找到一个有效的方法解决MAML在对话生成任务中模型的多样化问题。
在这篇文章中,作者提出Customized Model Agnostic Meta-Learning algorithm(CMAML),它基于MAML框架,可以在参数和模型结构两方面定制化对话模型。每个对话模型包含三个部分:
- 共享模块。学习生成语言模型的能力以及任务之间共同特征
- 私有模块。对任务进行特有特征的提取
- gating模块。从共享模块和私有模块中提取信息,然后生成最终的输出
共享模块和gating模块存在于所有模块中。私有模块中从相同的网络开始,但是有不同的结构,从而捕获特定任务的独有特征。
总之,在这篇文章中作者的贡献如下:
- 提出CMAML算法。在few-shot setting中,对于不同的任务可以为对话模型定制不同的网络结构。该算法general and well unified,适用于各种few-shot 生成场景
- 提出剪枝算法。可以矫正网络结构更好的适合训练数据集。作者用这个策略可以为不同的任务定制唯一的对话模型
- 研究了基于meta-learning的方法的两个关键影响因素,即训练数据的数量和任务的相似性。 然后,我们描述了meta-learning可以超过其他微调方法的情况。
Related Work
Few-shot Text Generation应用场景
- 冷启动
- 多语言
- 个性化对话
- 情感对话
Few-shot 对话生成,之前的那些方法都需要手动的创建任务描述,导致在许多实际场景中不能用。
解决上述Few-shot 对话生成问题比较好的方式是Meta-Learning,特别是MAML。 MAML提出将用每个用户的对话语料库的学习视为一个任务,然后在特定任务数据集上微调初始化参数来赋予个性化模型。将多领域面向任务的对话生成中的每个领域的学习视为一项任务,并以类似方式应用MAML。 由于MAML与模型无关,所有这些方法都不会更改原始MAML,而是将其直接应用于其方案。 因此,任务区分始终依靠微调,它仅在参数级别而不是模型结构级别为每个任务搜索最佳模型。
经典的Meat-Learning方法–MAML

元学习的常见三种方法
- 基于度量 metric-based:学习核变换参数
- 基于模型 model-based:一次性输入数据,学习1个模型的参数
- 基于优化 optimization-based:学习元模型参数
Meta-learning两种使用场景
- Meta-learning的方法与模型无关,适用性强。任何的一个监督的学习,比如分类回归、强化学习等,凡是用梯度下降来更新参数的,都可以使用这种方法。
- 需要的场景数据少。
具体算法:
1)方法:利用一系列分类器task的训练数据作为训练样本,找到一个最好的全局参数θ,将其迁移到新的任务上,迅速的去学习到一个对新的场景的分类器。
2)算法:以分类任务和回归任务为例:
- 准备N个训练任务(Train Task)、每个训练任务对应的Support Set和Query Set。再准备几个测试任务,测试任务用于评估meta learning 学习到的参数的效果。训练任务和测试任务均从Omniglot中采样产生。
- 初始化一个meta网络的参数为θ。
- 开始执行迭代“预训练” 。
- 通过上一步得到meta网络的参数,该参数可以在测试任务中,使用测试任务的SupportSet对met网络的参数进行finetuing。
- 最终使用测试任务的Query Set评估meta learning的效果
MAML特点
MAML的目标是在应用于新任务时,通过最大化损失函数的灵敏度来找到模型参数的初始化。对于一个目标任务,它的对话模型是通过使用特定于任务的训练样本微调是来自MAML的初始参数获得。
生成式对话模型的目标是构建一个函数,将用户查询映射到它的回复,其中函数由模型结构和参数决定。
MAML仅从参数优化的角度搜索最佳参数设置,而忽略了从结构优化的角度搜索最佳网络结构。
原生的MAML在图像和文本分类场景能力有限。
In this paper, we propose a new meta-learning algorithm based on MAML that can enhance task-specific characteristics for generation models.
在这篇文章中,我们提出一个新的基于MAML的Meat-learning方法,对于生成模型而言可以加强特定任务的特征。
Dialogue Model
Model Architecture

旨在对于few-shot setting中的每个不同的生成任务构建对话模型。对话模型包括三个网络模块,记作Seq2SPG。如上图。
共享模块
获得生成句子的基础能力,因此它的参数在所有任务之间是共享的。作者采用seq2seq对话模型。对于每个解码单元,在step t t t 输入 x t x_t xt和上一个隐藏层状态 h t − 1 h_{t-1} ht−1 ,获得在词汇表上的输出分布 o s o_s os 。
私有模块
对每个任务的唯一特征进行建模。作者设计了一个多层感知机,开始时进行相同的初始化,然后在训练过程中演变成不同的结构。在每一次decoding step t t t ,多层感知机采用当前词 x t x_t xt以及在t-1步共享模型的输出 h t − 1 h_{t-1} ht−1,然后一个分布 o p o_p op。在作者的实验中,也尝试在私有模型中采用不同的输入。
门控Gating模块
采用一个gate融合共享和私有模块的信息。
g s = t a n h ( W s [ o s , o p ] + b s ) g_s = tanh(W_s[o_s,o_p]+b_s) gs=tanh(Ws[os,op]+bs)
g p = t a n h ( W p [ o s , o p ] + b p ) g_p = tanh(W_p[o_s,o_p]+b_p) gp=tanh(Wp[os,op]+bp)
o = g s ∘ o s + g p ∘ o p o = g_s \circ o_s +g_p \circ o_p o=gs∘os+gp∘op
其中 W s , W p , b s , b p W_s,W_p,b_s,b_p Ws,Wp,bs,bp为参数, ∘ \circ ∘ 是元素积(element-wise product), o是词分布。
Training Overview
$p(\mathcal T) 表 示 任 务 分 布 , 表示任务分布, 表示任务分布,T_i$ 表示第i个被训练的任务, D i t r a i n D_i^{train} Ditrain 和 D i v a l i d D_i^{valid} Divalid表示任务 T i T_i Ti的训练集和验证集。 θ i \theta_i θi表示对于 T i T_i Ti任务对话模型的所有训练参数。模型训练主要有两部分组成:预训练和定制化模型训练。
在与训练中,CMAML采用普通MAML目的是获得一个一个与训练对话模型作为所有任务的初始化参数。在MAML开始阶段, θ \theta θ 被随机初始化。然后,迭代的执行两个主要的过程:meta-training和meta-testing. 在meta-training 阶段,MAML首先从任务集中进行采样 T i ∼ p ( T ) T_i \sim p(\mathcal T) Ti∼p(T),然后对于每个任务 i i i,MAML根据特定任务集调整 θ \theta θ 以获得 θ ′ \theta' θ′:
θ ′ = θ − α ▽ θ L D i t r a i n ( f ( θ ) ) \theta' = \theta - \alpha \triangledown_{\theta} \mathcal L_{D_i^{train}}(f(\theta)) θ′=θ−α▽θLDitrain(f(θ))
在meta-testing中,用 θ ′ \theta' θ′对MAML 测试任务 T i ∼ p ( T ) T_i \sim p(\mathcal T) Ti∼p(T) 以获得损失函数,从而对 θ \theta θ进行更新
θ = θ − β ▽ θ ∑ T i ∼ p ( T ) L D i v a l i d ( f ( θ i ′ ) ) \theta = \theta - \beta \triangledown_{\theta} \sum_{T_i \sim p(\mathcal T)} \mathcal L_{D_i^{valid}}(f(\theta'_i)) θ=θ−β▽θTi∼p(T)∑LDivalid(f(θi′))
其中 α \alpha α和 β \beta β 是超参。
在标准的MAML中不能搜索到最好的模型,生成的模型不易受到输入变化的影响,不能让每个任务对应的模型多样。为了解决这个问题,提出了CMAM,可以捕获每个任务的特征,使模型具有多样性。
Customized Model Training
在从获得MAML中获得预训练模型参数 θ \theta θ后,作者采用Customized Mode Training ,包含以下两步:
- private network pruning 这一步只在私有模块中应用,在每个私有模块中每个任务有不同的多层感知机结构。每个任务通过保留其自己的active 多层感知机 参数子集而具有不同的MLP结构,以表征此任务的唯一性。
- joint Meta-learning 在这一步,作者再次采用MAML训练每个任务的三个(shared,gating,private)模块,但是每个私有模块采用的是它自己剪枝的多层感知机结构。同时,相似的任务一起训练以丰富训练数据,相似的任务采用相似的剪枝多层感知机结构。
下面对这两部进行详细介绍。
Private Network Pruning
在预训练之后,不同任务的对话模型仍然有相同的参数 θ \theta θ ,包括在共享/私有/门控模块中的 θ s / θ p / θ g \theta^s/\theta^p/\theta^g θs/θp/θg。在这一步中,带有初始参数 θ p \theta^p θp的私有模块会在不同结构中产生不同的参数 θ i p \theta^p_i θip, 以更好的获取任务的唯一特征。
首先,作者微调使用MAML初始化的每个任务的整个对话模型,微调时采用的是每个任务它自己的训练数据,并在私有模块的参数上添加L-1正则化。L-1正则化的目的是使参数稀疏,以便只有对生成特定任务句子有利的参数才有效。
其次,采用从上倒下的策略对每个任务的私有多层感知机进行剪枝。这就相当于在多层感知机中选择全连接层的边。作者没有对多层感知机中输入输出层的全连接层进行剪枝。对于其余层,作者从离输出层最近的开始剪枝。对于第 l l l层,作者认为大于 l l l的是离输出层更近,小于 l l l的是离输入层更近。当处理第 l l l层时,它的上层应该是已经完成了剪枝的。作者只保留当前层权重超过阀值 γ \gamma γ的边。如果在 l l l层的节点被裁剪了,那么与它相连的所有的边都被剪枝掉。这种方式里,私有模型的参数 θ p \theta^p θp不同于在任务 ∣ T ∣ |T| ∣T∣里的参数 θ i p \theta^p_i θip,每个 θ i p \theta^p_i θip是 θ p \theta^p θp是的子集。详细算法如下图:

Joint Meta-learning
到目前为止,每个任务在私有模块中都有有唯一的网络结构。之后将所有任务联合起来训练整个对话模型。
作者再次从预训练MAML初始化开始。对于共享模块和门控(gating)模块而言,所有的任务共享同样的参数,它们的训练采用所有的训练集进行训练。私有模块采用特定任务自己的数据集,从而可以更好的捕获每个任务唯一的特征。然而在少样本数据集中,对于每个任务而言,作者没有充足的数据导致私有模块可能训练不好。好在,所有的私有模块从相同的MLP(多层感知机)结构演化而来,相似的任务自然共享重叠的网络结构。修剪后剩余的边缘重叠。 这使作者想到了可以通过不修剪边的所有任务来训练私有MLP中的每条边。
进一步而言,训练私有MLP采用以下方式:
对于MLP中的每条边 e e e,如果它在一些任务中是active的,在所有的任务 j j j中更新相应的参数 θ e p \theta^p_e θep, θ e p ∈ θ j p \theta^p_e \in \theta^p_j θep∈θjp:
θ e ′ p = θ e p − α ▽ θ e p ∑ T j : θ e p ∈ θ j p L D j t r a i n ( f ( θ j p ) ) \theta'^p_e = \theta^p_e - \alpha \triangledown_{\theta^p_e} \sum_{T_j:\theta^p_e \in \theta^p_j} \mathcal L_{D_j^{train}}(f(\theta_j^p)) θe′p=θep−α▽θepTj:θep∈θjp∑LDjtrain(f(θjp))
其中每个 θ i p / θ i ′ p \theta^p_i/\theta'^p_i θip/θi′p只包含第 i i i个任务中所有活动边 θ e p / θ e ′ p \theta^p_e/\theta'^p_e θep/θe′p。
在meta-testing中,损失函数是由使用相应对话模型的任务累积的,因此 θ p \theta^p θp根据以下进行更新:
θ p = θ p − β ∑ T i ∼ p ( T ) ▽ θ i p L D i v a l i d ( f ( θ i ′ p ) ) \theta^p = \theta^p - \beta \sum_{T_i \sim p(\mathcal T)} \triangledown_{\theta^p_i} \mathcal L_{D_i^{valid}}(f(\theta'^p_i)) θp=θp−βTi∼p(T)∑▽θipLDivalid(f(θi′p))
Gradient Updates
在定制化模型训练时,我们汇总了对话模块的三种模块的梯度更新,如算法2。对于共享和门控模块,梯度更新与MAML相同。私有模型的梯度更新引入联合meta-learning同上面两个式子。
在这个模型中,给定输入查询q时,用于计算模型中梯度的损失函数是生成响应r的负对数似然性,
L = − l o g p ( r ∣ q , θ s , θ p , θ g ) \mathcal L = -log p(r|q,\theta^s,\theta^p,\theta^g) L=−logp(r∣q,θs,θp,θg)

Experiments
实验数据和模型
在两个数据集上进行实验,Persona-chat和MojiTalk。
- 在Persona-chat中,把为用户建立对话模型视为一项任务。
- 在MojiTalk中,把用cemoji生成响应视为一项任务。
使用4种类型的Competing Methods:
1)Pretrain-Only
预训练仅表示用来自所有训练任务的数据预训练一个统一的对话生成模型,然后直接在测试任务上测试它。
2)Fine-tune
微调是用特定于任务的数据来微调统一模型。
3)MAML
在两个基础模型上应用MAML,主要使用了传统的seq2seq和讲者团队提出的seq2SPG。
4)CMAML
采用CMAML算法的两种变体,CMAML-Seq2SP’G和CMAML-Seq2SPG。
Evaluation Metrics
自动评估
从三方面进行评估:
- Response quality/diversity
- 使用BLEU来测量词和生成句子的单词重叠;
- PPL,生成句子的负对数。
- Dist-1 评估response 的多样性
- Task consistency
- c score 评分使用预先训练的自然语言推理模型来测量与角色描述相关的response一致性
- E-acc 使用情感分类器预测响应和指定情感之间的相关性
- Model difference
人为评估
实验结果

整体结果表明,微调方法比仅预训练更好,MAML方法在BLEU分数上没有比微调方法更好的表现,但是具有相对较高的Dist-1分数。这表明MAML有助于促进反应的多样性。
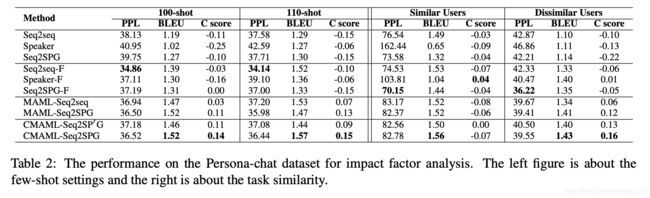
在不同的场景设置中进行评估:
- 由左图表明,对于非基于MAML的方法,任务一致性不会随着数据的增长而提高。而对于基于MAML的方法,句子质量和任务一致性都随着数据的增长而增加。
- 由右图表明,当任务不太相似时,基于MAML的方法表现更好。
Conclusion
- 作者在研究报告中提出的算法CMAML可以为任务定制模型,其中每个任务具有唯一的网络结构和参数,并且在生成任务中只需要一个或两个数百个训练样本。
- 每个任务独特的结构能够记忆其特征,相似的任务从模型结构的角度共享训练数据。
- CMAML是通用的,并且很好地统一以适应各种few-shot的生成场景。