seq2seq的论文学习和代码实现
文章目录
- seq2seq
- 代码
-
- tensorlfow常用RNN函数(主要是我的代码中用到的)
-
- [tf.nn.rnn_cell.LSTMCell](https://tensorflow.google.cn/api_docs/python/tf/nn/rnn_cell/LSTMCell)
- [tf.nn.rnn_cell.DropoutWrapper](https://tensorflow.google.cn/api_docs/python/tf/nn/rnn_cell/DropoutWrapper)
- [tf.nn.rnn_cell.MultiRNNCell](https://tensorflow.google.cn/api_docs/python/tf/nn/rnn_cell/MultiRNNCell)
- [tf.contrib.legacy_seq2seq.embedding_rnn_seq2seq](https://tensorflow.google.cn/api_docs/python/tf/contrib/legacy_seq2seq/embedding_rnn_seq2seq)
- [tf.contrib.legacy_seq2seq.sequence_loss](https://tensorflow.google.cn/api_docs/python/tf/contrib/legacy_seq2seq/sequence_loss)
参考文章:
Lstm的理解: https://blog.csdn.net/songhk0209/article/details/71134698
seq2seq 论文地址: https://arxiv.org/pdf/1409.3215.pdf
seq2seq相关git上学习代码: https://github.com/suriyadeepan/practical_seq2seq
我自己的项目地址是:
seq2seq
我看的论文是Sequence to Sequence Learning
with Neural Networks
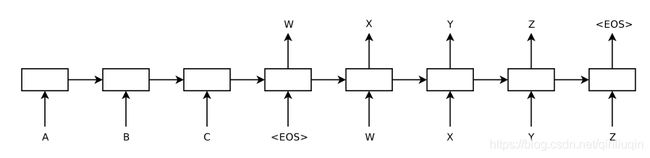 这篇论文的模型类似于Encoder-Decoder的模型,Encoder和Decoder的部分采用两个不同的RNN,这个Sequence to Sequence的学习中,首先将可变长的Sequence用一个RNN提取出—定长的特征向量,这个特征向量取自最后一个LSTM单元。之后,把这个向量输入另一个RNN(语言模型),如条件语言模型,使用beam search计算出概率最大的句子,得到输出。
这篇论文的模型类似于Encoder-Decoder的模型,Encoder和Decoder的部分采用两个不同的RNN,这个Sequence to Sequence的学习中,首先将可变长的Sequence用一个RNN提取出—定长的特征向量,这个特征向量取自最后一个LSTM单元。之后,把这个向量输入另一个RNN(语言模型),如条件语言模型,使用beam search计算出概率最大的句子,得到输出。
文章的创新之处在于:源串作为第一个RNN的输入,其中的每一个单词是逆向输入的,这样做得到了更高的BLEU分数;也发现使用深层的LSTM表现的更好(文中是4层LSTM单元)
代码
tensorlfow常用RNN函数(主要是我的代码中用到的)
之前一直写的代码都是有关图像方面的,都是cnn的一些函数,这是我看的第一篇关于rnn的,所以首先将一些tenforflow中rnn函数整理一下,便于代码理解,也能通过代码对一些原理有一些认识。
tf.nn.rnn_cell.LSTMCell
之前看到的tf.nn.rnn_cell.BasicLSTMCell 它将在未来版本中删除。官网有更新说明:不推荐使用此类,请使用tf.nn.rnn_cell.LSTMCell,它支持此单元格当前具有的所有功能, 请用tf.nn.rnn_cell.LSTMCell(name =‘basic_lstm_cell’)替换现有代码,因此我只介绍lstmcell
num_units这个参数的大小就是LSTM输出结果的维度。例如num_units=128,那么LSTM网络最后输出就是一个128维的向量(也就是lstm中的ht,一般在函数中只要指定num_units就会自动实现一个完整lstm结构)
tf.nn.rnn_cell.DropoutWrapper
init(
cell,
input_keep_prob=1.0,
output_keep_prob=1.0,
state_keep_prob=1.0,
variational_recurrent=False,
input_size=None,
dtype=None,
seed=None,
dropout_state_filter_visitor=None
)
需要了解的是循环神经网络一般只在不同层循环体结构之间使用dropout,而不在同一层的循环体结构之间使用,也就是说从时刻t-1传递到时刻t,循环神经网络不会进行状态的dropout,而在同一个时刻t中,不同层循环体之间会dropout。
- cell 指代之前定义的lstmcell,是要对lstmcell进行dropout,dropout这个概念在深度学习中并不陌生,在CNN中也经常用到过。input_keep_prob: 对每一层RNN的输入进行dropout;output_keep_prob: 对每一层的RNN的输出进行dropout;state_keep_prob: 对每一层的RNN的中间传递的隐层状态,通常是tensorflow的cell返回的turple中的第二个值,也就是(output,state)中德state,进行dropout。
- 在tensorflow中使用DropoutWrapper时不建议input_keep_prob和output_keep_prob同时使用,因为上一步的输出对应下一步的输入,导致连个keep_prob相乘,因此只需要指定一个就好。
tf.nn.rnn_cell.MultiRNNCell
init(
cells,
state_is_tuple=True
)
这个函数主要用来支持深层循环神经网络,深层循环神经网络在每个时刻将循环体结构复制了很多次,和卷积神经网络类似,每一层的循环体中的参数是一致的,而不同层中的参数可以不同。
- cells:将按此顺序组成的RNNCell列表。一般代入参数是:[basic_cell]*num_layers
- state_is_tuple如果为True,接受和返回的states是n-tuples,其中n=len(cells)。如果为False,则状态全部沿列轴连接。 后一种行为很快就会被弃用。
tf.contrib.legacy_seq2seq.embedding_rnn_seq2seq
outputs, states=tf.contrib.legacy_seq2seq.embedding_rnn_seq2seq(
encoder_inputs,
decoder_inputs,
cell,
num_encoder_symbols,
num_decoder_symbols,
embedding_size,
output_projection=None,
feed_previous=False,
dtype=None,
scope=None
)
输出为output和states,states是当前的state是由Ct 和 ht组成(如果有多个cell,就有多个),而output是h1到ht的所有输出组合的总的输出结果
- encoder_inputs:encoder的输入,一个tensor的列表。列表中每一项都是encoder时的一个词(batch,每个位置都只是一个token id)
- decoder_inputs: decoder的输入,同上
- num_encoder_symbols:通俗的说其实就是encoder端的vocab_size。enc和dec两端词汇量不同主要在于不同语言的translate task中,如果单纯是中文到中文的生成,不存在两端词汇量的不同。
- num_decoder_symbols:同上
- embedding_size:我的理解是一个隐层向量大大小
- feed_previous:如果为false,这意味着在解码器端,使用decoder_inputs作为输入,例如,decoder_inputs 是‘GO, W, X, Y, Z ’,正确的输出应该是’W, X, Y, Z, EOS’,假设第一个时刻的输出不是’W’,在第二个时刻也要使用’W’作为输入;当设为true时,只使用decoder_inputs的第一个时刻的输入,即’GO’,也就是解码器的在每一时刻的真实输出作为下一时刻的输入。通常在测试时候用true,训练时候用false
tf.contrib.legacy_seq2seq.sequence_loss
tf.contrib.legacy_seq2seq.sequence_loss(
logits,
targets,
weights,
average_across_timesteps=True,
average_across_batch=True,
softmax_loss_function=None,
name=None
)
- logits:(这里的list指句子长度) List of 2D Tensors of 尺寸 [batch_size x num_decoder_symbols].
- targets:List of 1D batch-sized int32 Tensors of the same length as logits.
- weights:List of 1D batch-sized float-Tensors of the same length as logits,即mask,滤去padding的loss计算,使loss计算更准确。