论文分享 | Yann LeCun 联合发布、工程师都在读的自监督学习论文
文章导读
本期文章中,我们为大家带来了 3 篇自监督学习的相关论文,其中两篇是由卷积网络之父 Yann LeCun 参与发布。
对于大型机器视觉训练任务而言,自监督学习 (Self-supervised learning,简称 SSL) 与有监督方法的效果越来越难分伯仲。
其中,自监督学习是指利用辅助任务 (pretext),从大规模的无监督数据中,挖掘自身的监督信息来提高学习表征的质量,通过这种构造监督信息对网络进行训练,从而学习对下游任务有价值的表征。
本文将围绕自监督学习,分享 3 篇论文,以期提高大家对自监督学习的认识和理解。
Barlow Twins:基于冗余减少的 SSL
题目:
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
作者:
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, Stephane Deny
对于自监督学习方法而言,一个非常受用的方法就是学习嵌入向量 (embedding),因为它不受输入样本失真的影响。
但是这种方法也存在一个无法避免的问题:trivial constant solution。目前大多数方法都试图通过在实现细节上下功夫,来规避 trivial constant solution 的出现。
本篇论文中,作者提出了一个目标函数,通过测量两个相同网络的输出(使用失真样本)之间的互相关矩阵,使其尽可能地接近单位矩阵 (identity matrix),从而避免崩溃 (collapse) 的发生。
这使得样本(失真)的嵌入向量变得相似,同时也会使这些向量组件 (component) 之间的冗余最少。该方法被称为 Barlow Twins。
 Barlow Twins 原理示意图
Barlow Twins 原理示意图
Barlow Twins 无需 large batches,也不需要 network twins 之间具有不对称性(如 pradictor network、gradient stopping 等),这得益于非常高维的输出向量。
Barlow Twins 损失函数:

其中 λ 为正常数 (positive constant),用于权衡 Loss 第一和第二项的重要性;C 为两个相同网络的输出之间,沿 batch 维度计算的互相关矩阵:

其中,b 表示 batch sample;i, j 代表网络输出的向量维度;C 则表示方块矩阵,其大小为网络输出的维度 (-1~1 之间)。
在 ImageNet 上,Barlow Twins 在低数据机制 (low-data regime) 下的半监督分类中的表现,优于之前的所有方法;在 ImageNet 分类任务中,与当下最先进的 linear classifier 效果相当;在分类和目标检测的迁移任务中也是如此。
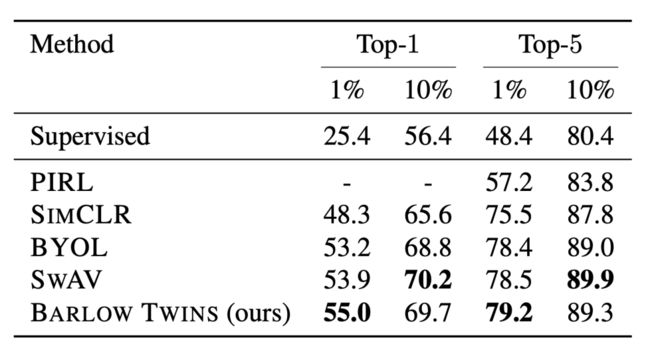 在 ImageNet 上用 1% 和 10% 的训练实例,进行半监督学习,粗体表示最佳结果
在 ImageNet 上用 1% 和 10% 的训练实例,进行半监督学习,粗体表示最佳结果
实验表明,与其他方法相比,Barlow Twins 的表现稍好(使用 1% 的数据时)或持平(使用 10% 的数据时)。
阅读完整论文见:Barlow Twins: Self-Supervised Learning via Redundancy Reduction
VICReg:方差 - 不变性 - 协方差正则化
题目:
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
作者:
Adrien Bardes, Jean Ponce, Yann LeCun,
用于图像表征学习的自监督方法,一般基于同一图像、不同视图的嵌入向量之间的一致性,进行最大化。当编码器 Encoder 输出常数向量时,就会出现一个 trivial solution。
一般情况下,会通过学习架构中的 implicit bias(缺乏明确的理由或解释),避免这个崩溃 (collapse) 问题的出现。
本篇论文中,作者介绍 VICReg (全称 Variance-Invariance-Covariance Regularization),它在每个维度的嵌入方差上,都有一个简单的正则化项,因此可以明确避免崩溃问题的发生。
VICReg 结合了方差项与基于减少冗余和协方差正则化的去相关机制 (decorrelation mechanism),并在几个下游任务上,取得了与目前技术水平相当的结果。
此外,实验表明将全新的方差项纳入其他方法,有助于稳定训练并提高性能。
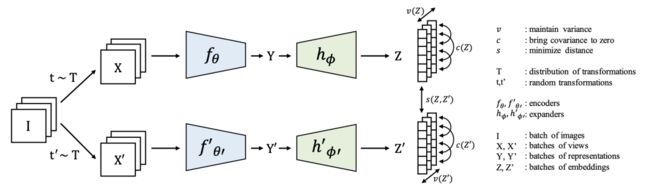 VICReg 原理示意图
VICReg 原理示意图
给定一批图像 I,X 和 X' 分别表示不同的视图,将其编码为表征 Y 和 Y'。表征被输入至扩展器 (expander),生成嵌入向量 Z 和 Z'。
来自同一图像的两个嵌入之间的距离被最小化,每个嵌入变量在一个 batch 中的方差,保持在阈值以上,并且一个 batch 中成对的嵌入变量之间的协方差被吸引到零,使这些变量之间相互关联。
虽然这两个分支不需要相同的架构,也不需要共享权重,但大多数实验中,它们是共享权重的孪生网络 (Siamese):编码器是输出维度为 2048 的 ResNet-50 主干网洛;扩展器包括 3 个大小为 8192 的全连接层。
 不同方法在 ImageNet 上的表现对比,下划线标注了表现最佳的前 3 个自监督方法
不同方法在 ImageNet 上的表现对比,下划线标注了表现最佳的前 3 个自监督方法
评估用 VICReg 预训练的 ResNet-50 骨干网络得到的表征:
1、在 ImageNet 冻结表征 (frozen representation) 之上的 linear classification;
2、从 1% 和 10% 的 ImageNet 样本的微调表征之上的半监督分类。
图片展示了 Top-1 和 Top-5 的准确率(单位:%)。
阅读完整论文见:VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
iBOT:Image BERT Online Tokenizer
题目:
iBOT: Image BERT Pre-Training with Online Tokenizer
作者:
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, Tao Kong
NLP 领域 Transformer 模型的成功,主要得益于掩码语言模型 (masked language modeling,简称 MLM) 的辅助任务 (pretext),即首先将文本分词为具有语义的片段。
本篇论文中,作者对掩码图像模型 (masked image modeling,简称 MIM) 进行研究,提出了一个自监督框架 iBOT。
iBOT 可以利用 online tokenizer 进行掩码预测 (masked prediction)。具体来说,作者对 masked patch token 进行自蒸馏 (self-distillation),并将 teacher 网络作为在线分词器,同时对 class token 进行自蒸馏,以获得视觉语义 (visual semantics)。
在线分词器还可以与 MIM 目标共同学习,并免除了分词器需要提前预训练的多阶段训练 pipeline。
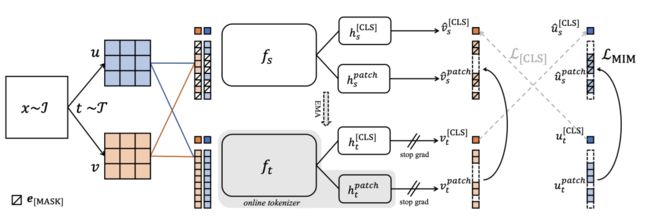 iBOT 框架概览,借助在线分词器进行掩码图像建模
iBOT 框架概览,借助在线分词器进行掩码图像建模
iBOT 表现突出,在与分类、目标检测、实例分割和语义分割等相关的下游任务上,均取得了最先进的结果。
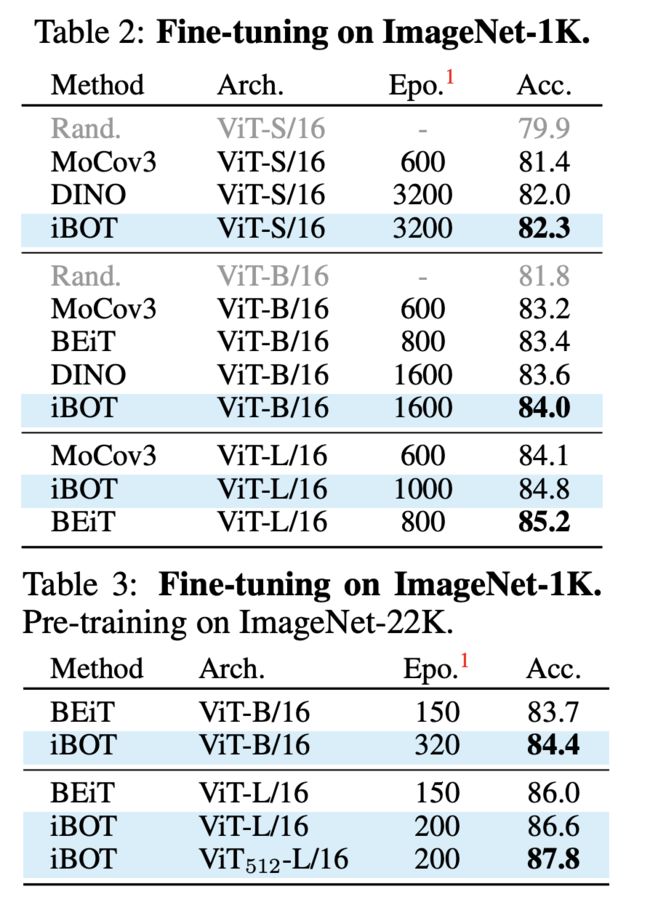 Table 2:在 ImageNet-1K 上进行微调,Table 3:在 ImageNet-1K上进行微调,并在 ImageNet-22K 上进行预训练
Table 2:在 ImageNet-1K 上进行微调,Table 3:在 ImageNet-1K上进行微调,并在 ImageNet-22K 上进行预训练
实验结果表明,iBOT 在 ImageNet-1K 上达到了 82.3% 的 linear probing 准确率,以及 87.8% 的微调准确率。
阅读完整论文见:iBOT: Image BERT Pre-Training with Online Tokenizer
DocArray:适用于非结构化数据的数据结构
自监督学习面临的众多挑战之一,就是对于大量无标签数据,进行表征学习。
随着互联网技术的迅猛发展,非结构化数据的数量得到了空前的增加,数据结构也覆盖了除文本、图像以外的音视频,甚至 3D mesh。
DocArray 可以极大简化非结构化数据的处理和利用 。
DocArray 是一种可扩展数据结构,完美适配深度学习任务,主要用于嵌套及非结构化数据的传输,支持的数据类型包括文本、图像、音频、视频、3D mesh 等。
与其他数据结构相比:
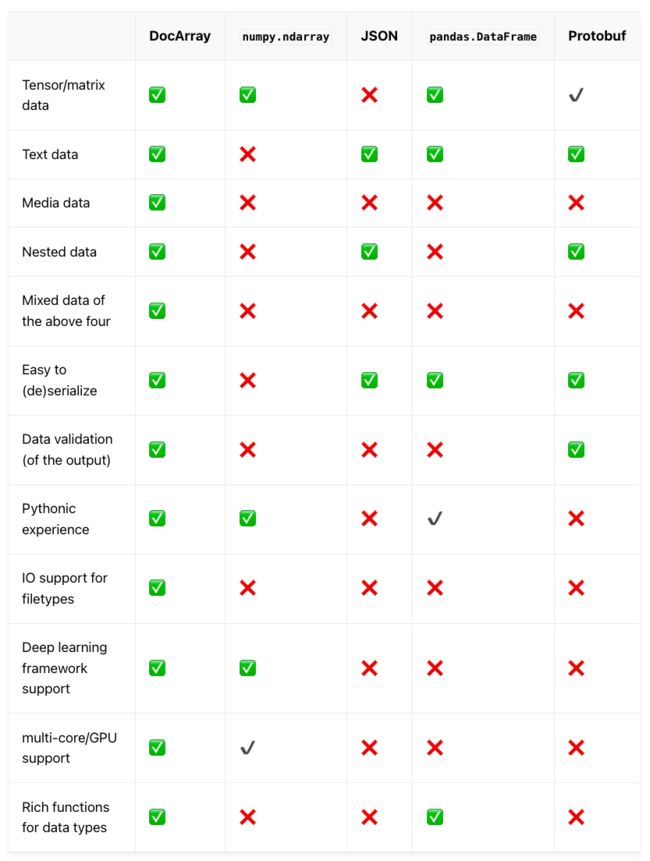
✅ 表示完全支持,✔ 表示部分支持,❌ 表示不支持
利用 DocArray,深度学习工程师可以借助 Pythonic API,有效地处理、嵌入、搜索、推荐、存储和传输数据。
以上就是本期自监督学习论文分享的全部内容,还想要了解哪些论文、教程以及工具推荐?欢迎后台留言告诉我们,我们将根据留言每周放送。
参考链接:
Jina GitHub
DocArray
Finetuner
加入 Slack