MobileNetV1作为CenterNet的Backbone尝试
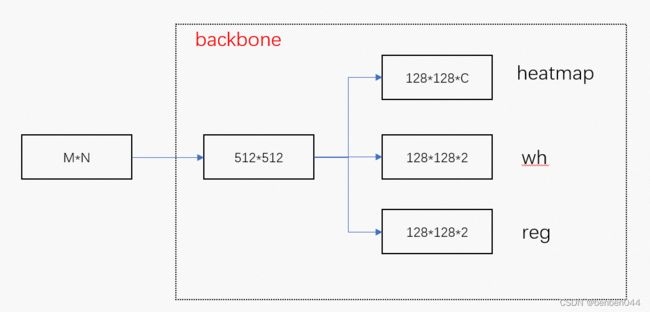
1、CenterNet对于Backbone的要求是:
输入为512*512,输出为:heatmap(128*128*C)、wh(128*128*2)、reg(128*128*2)。
2、原生的MobileNet V1输出:
最后一层通过x.view(x.size(0), -1)和nn.Linear后得到[batch_num * class_num]
3、改造输出使得输出符合业务要求:
将之前的x.view(x.size(0), -1)修改为:
x.view(x.shape[0], -1, 128, 128),其中第2个维度为16。
然后通过1*1卷积核进行通道数的升、降维。
网络定义阶段:
self.hm = nn.Conv2d(16, class_num, kernel_size=1)
self.wh = nn.Conv2d(16, 2, kernel_size=1)
self.reg = nn.Conv2d(16, 2, kernel_size=1)
forward阶段:
y = x.view(x.shape[0], -1, 128, 128)
z = {}
z['hm'] = self.hm(y)
z['wh'] = self.wh(y)
z['reg'] = self.reg(y)
4、完整MobileNetv1适配centerNet的代码如下:
import torch
import torch.nn as nn
class BasicConv2dBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, downsample=True, **kwargs):
super(BasicConv2dBlock, self).__init__()
stride = 2 if downsample else 1
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class DepthSeperabelConv2dBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, **kwargs):
super(DepthSeperabelConv2dBlock, self).__init__()
# 深度卷积
self.depth_wise = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size, groups=in_channels, **kwargs),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
# 逐点卷积
self.point_wise = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.depth_wise(x)
x = self.point_wise(x)
return x
class MobileNet(nn.Module):
def __init__(self, heads):
super(MobileNet, self).__init__()
class_num = heads['hm']
self.stem = nn.Sequential(
BasicConv2dBlock(3, 32, kernel_size=3, padding=1, bias=False),
DepthSeperabelConv2dBlock(32, 64, kernel_size=3, padding=1, bias=False)
)
self.conv1 = nn.Sequential(
DepthSeperabelConv2dBlock(64, 128, kernel_size=3, stride=2, padding=1, bias=False),
DepthSeperabelConv2dBlock(128, 128, kernel_size=3, padding=1, bias=False)
)
self.conv2 = nn.Sequential(
DepthSeperabelConv2dBlock(128, 256, kernel_size=3, stride=2, padding=1, bias=False),
DepthSeperabelConv2dBlock(256, 256, kernel_size=3, padding=1, bias=False)
)
self.conv3 = nn.Sequential(
DepthSeperabelConv2dBlock(256, 512, kernel_size=3, stride=2, padding=1, bias=False),
DepthSeperabelConv2dBlock(512, 512, kernel_size=3, padding=1, bias=False),
DepthSeperabelConv2dBlock(512, 512, kernel_size=3, padding=1, bias=False),
DepthSeperabelConv2dBlock(512, 512, kernel_size=3, padding=1, bias=False),
DepthSeperabelConv2dBlock(512, 512, kernel_size=3, padding=1, bias=False),
DepthSeperabelConv2dBlock(512, 512, kernel_size=3, padding=1, bias=False)
)
self.conv4 = nn.Sequential(
DepthSeperabelConv2dBlock(512, 1024, kernel_size=3, stride=2, padding=1, bias=False),
DepthSeperabelConv2dBlock(1024, 1024, kernel_size=3, padding=1, bias=False)
)
self.hm = nn.Conv2d(16, class_num, kernel_size=1)
self.wh = nn.Conv2d(16, 2, kernel_size=1)
self.reg = nn.Conv2d(16, 2, kernel_size=1)
def forward(self, x):
x = self.stem(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
y = x.view(x.shape[0], -1, 128, 128)
z = {}
z['hm'] = self.hm(y)
z['wh'] = self.wh(y)
z['reg'] = self.reg(y)
return [z]
def main():
heads = {'hm': 10, 'wh': 2, 'reg': 2}
model = MobileNet(heads)
for _,param in enumerate(model.named_parameters()):
print(param[0], param[1].shape, param[1].shape.numel())
param_num = sum(x.numel() for x in model.parameters())
print('model parameters num:', param_num)
x = torch.rand([1, 3, 512, 512])
y = model(x)
print(y[-1]['hm'].shape)
print(y[-1]['wh'].shape)
print(y[-1]['reg'].shape)
if __name__ == '__main__':
main()5、与DLASeg的对比
(1)效果:
DLASeg的训练集loss可以降到1.0以下,而MobileNet v1的训练姐loss只能降到3.0左右。
在车牌目标检测的试验中,MobileNet v1最好的效果如下,效果不佳。

(2)性能(CPU下)
DLASeg的模型参数有19655846个,大致为2000W个;而MobileNetv1的模型参数有3213030个,大致为320W个。所以参数量上降了一个数量级。
DLASeg的cpu下一次推理平均需要1.2s左右,而mobilenet v1在未剪枝情况下为232ms,这一块到时提升比较明显。