TensorRT详细入门指北,如果你还不了解TensorRT,过来看看吧!
原文:TensorRT详细入门指北,如果你还不了解TensorRT,过来看看吧! - 知乎
前言
大名鼎鼎的TensorRT有多牛逼就不多说了,因为确实很好用。
作为在英伟达自家GPU上的推理库,这些年来一直被大力推广,更新也非常频繁,issue反馈也挺及时,社区的负责人员也很积极,简直不要太NICE。
只是TensorRT的入门门槛略微高一点点,劝退了一部分玩家。一部分原因是官方文档也不够详细(其实也挺细了,只不过看起来有些杂乱)、资料不够;另一部分可能是因为TensorRT比较底层,需要一点点C++和硬件方面的知识,相较学习Python难度更大一点。
不过吐槽归吐槽,TensorRT官方文档依旧是最权威最实用的查阅手册,另外TensorRT也是全面支持Python的,不习惯用C++的小伙伴,用Python调用TensorRT是没有任何问题的。
一直也想写TensorRT的系列教程,也顺便整理一下自己之前做的笔记。拖了好久的TensorRT入门指北终于写完了。
本教程基于目前(2021-4-26)最新版TensorRT-7.2.3.4,TensorRT更新频繁,TensorRT-8可能不久也会发布,不过TensorRT对于向下兼容的API做的还是比较好的,不必担心太多的迁移问题。
今天简单一刷(2021-5-5),TensorRT终于发布8版本了,仍然是尝鲜的Early Access (EA),官方release。不过TensorRT8-EA版一些功能不是很稳定,我们先不着急使用。尝鲜的小伙伴们可以先试试,生产环境版本建议先不要动。
之前老潘也写过一些关于TensorRT文章,其中的部分内容也会整合到这一系列中,方便查阅:
- 利用TensorRT对深度学习进行加速
- 利用TensorRT实现神经网络提速(读取ONNX模型并运行)
- 实现TensorRT自定义插件(plugin)自由!
- (抛砖引玉)TensorRT的FP16精度问题?怎么办?在线支招!
不废话了,直接开始吧~
附上TensorRT官方文档链接。
什么是TensorRT
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
借官方的话来说:
The core of NVIDIA® TensorRT™ is a C++ library that facilitates high-performance inference on NVIDIA graphics processing units (GPUs). TensorRT takes a trained network, which consists of a network definition and a set of trained parameters, and produces a highly optimized runtime engine that performs inference for that network. TensorRT provides API's via C++ and Python that help to express deep learning models via the Network Definition API or load a pre-defined model via the parsers that allow TensorRT to optimize and run them on an NVIDIA GPU. TensorRT applies graph optimizations, layer fusion, among other optimizations, while also finding the fastest implementation of that model leveraging a diverse collection of highly optimized kernels. TensorRT also supplies a runtime that you can use to execute this network on all of NVIDIA’s GPU’s from the Kepler generation onwards. TensorRT also includes optional high speed mixed precision capabilities introduced in the Tegra™ X1, and extended with the Pascal™, Volta™, Turing™, and NVIDIA® Ampere GPU architectures.
TensorRT支持的平台如下:
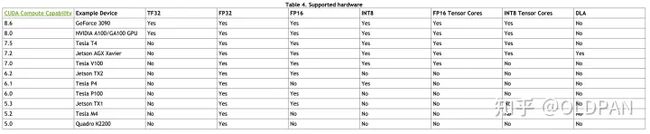
支持计算能力在5.0及以上的显卡(当然,这里的显卡可以是桌面级显卡也可以是嵌入版式显卡),我们常见的RTX30系列计算能力是8.6、RTX20系列是7.5、RTX10系列是6.1,如果我们想要使用TensorRT,首先要确认下我们的显卡是否支持。
至于什么是计算能力(Compute Capability),咋说嘞,计算能力并不是描述GPU设备计算能力强弱的绝对指标,准确的说,这是一个架构的版本号。一般来说越新的架构版本号更高,计算能力的第一个数值也就最高(例如3080计算能力8.6),而后面的6代表在该架构前提下的一些优化特性,具体代表什么特性可以看这里:
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities
可以通过这里查阅自己显卡的计算能力。
说回TensorRT本身,TensorRT是由C++、CUDA、python三种语言编写成的一个库,其中核心代码为C++和CUDA,Python端作为前端与用户交互。当然,TensorRT也是支持C++前端的,如果我们追求高性能,C++前端调用TensorRT是必不可少的。
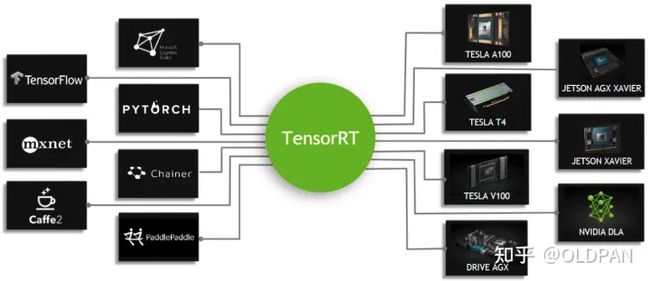
使用TensorRT的场景
TensorRT的使用场景很多。服务端、嵌入式端、家用电脑端都是我们的使用场景。
- 服务端对应的显卡型号为A100、T4、V100等
- 嵌入式端对应的显卡为AGX Xavier、TX2、Nano等
- 家用电脑端对应的显卡为3080、2080TI、1080TI等
当然这不是固定的,只要我们显卡满足TensorRT的先决条件,用就对了。
TensorRT的加速效果怎么样
加速效果取决于模型的类型和大小,也取决于我们所使用的显卡类型。
对于GPU来说,因为底层的硬件设计,更适合并行计算也更喜欢密集型计算。TensorRT所做的优化也是基于GPU进行优化,当然也是更喜欢那种一大块一大块的矩阵运算,尽量直通到底。因此对于通道数比较多的卷积层和反卷积层,优化力度是比较大的;如果是比较繁多复杂的各种细小op操作(例如reshape、gather、split等),那么TensorRT的优化力度就没有那么夸张了。
为了更充分利用GPU的优势,我们在设计模型的时候,可以更加偏向于模型的并行性,因为同样的计算量,“大而整”的GPU运算效率远超“小而碎”的运算。
工业界更喜欢简单直接的模型和backbone。2020年的RepVGG(RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)),就是为GPU和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。相比resnet系列,更加适合充当一些检测模型或者识别模型的backbone。
在实际应用中,老潘也简单总结了下TensorRT的加速效果:
- SSD检测模型,加速3倍(Caffe)
- CenterNet检测模型,加速3-5倍(Pytorch)
- LSTM、Transformer(细op),加速0.5倍-1倍(TensorFlow)
- resnet系列的分类模型,加速3倍左右(Keras)
- GAN、分割模型系列比较大的模型,加速7-20倍左右(Pytorch)
TensorRT有哪些黑科技
为什么TensorRT能够提升我们模型在英伟达GPU上运行的速度,当然是做了很多对提速有增益的优化:
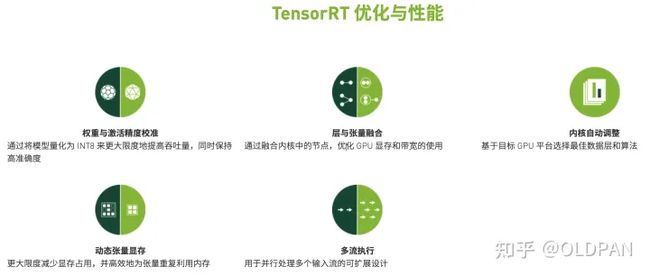
- 算子融合(层与张量融合):简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速
- 量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度
- 内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
- 动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
- 多流执行:使用CUDA中的stream技术,最大化实现并行操作
TensorRT的这些优化策略代码虽然是闭源的,但是大部分的优化策略我们或许也可以猜到一些,也包括TensorRT官方公布出来的一些优化策略:
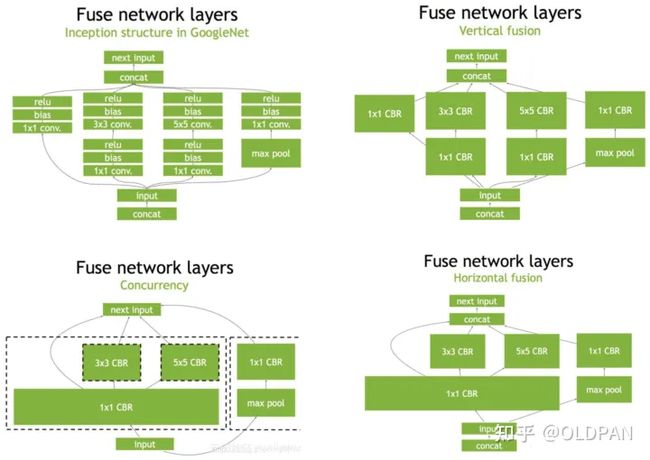
左上角是原始网络(googlenet),右上角相对原始层进行了垂直优化,将conv+bias(BN)+relu进行了融合优化;而右下角进行了水平优化,将所有1x1的CBR融合成一个大的CBR;左下角则将concat层直接去掉,将contact层的输入直接送入下面的操作中,不用单独进行concat后在输入计算,相当于减少了一次传输吞吐;
等等等等,还有很多例子。
上述的这些算子融合、动态显存分配、精度校准、多steam流、自动调优等操作,TensorRT都帮你做了。这样通过TensorRT帮你调优模型后,自然模型的速度就上来了。
当然也有其他在NVIDIA-GPU平台上的推理优化库,例如TVM,某些情况下TVM比TensorRT要好用些,但毕竟是英伟达自家产品,TensorRT在自家GPU上还是有不小的优势,做到了开箱即用,上手程度不是很难。
安装TensorRT!
安装TensorRT的方式有很多,官方提供了多种方式:
You can choose between the following installation options when installing TensorRT; Debian or RPM packages, a pip wheel file, a tar file, or a zip file.
这些安装包都可以从官方直接下载,从 https://developer.nvidia.com/zh-cn/tensorrt 进入下载即可,需要注意这里我们要注册会员并且登录才可以下载。老潘一直使用的方式是下载tar包,下载好后解压即可,只要我们的环境符合要求就可以直接运行,类似于绿色免安装。
例如下载TensorRT-7.2.3.4.Ubuntu-18.04.x86_64-gnu.cuda-11.1.cudnn8.1.tar.gz,下载好后,tar -zxvf解压即可。
解压之后我们需要添加环境变量,以便让我们的程序能够找到TensorRT的libs。
vim ~/.bashrc
# 添加以下内容
export LD_LIBRARY_PATH=/path/to/TensorRT-7.2.3.4/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=/path/to/TensorRT-7.2.3.4/lib::$LIBRARY_PATH这样TensorRT就安装好了,很快吧!
TensorRT常见FAQ
对于使用TensorRT,还是有一些需要注意的地方,老潘在这里总结了一些大家可能感兴趣或者之后可能遇到的一些问题。
TensorRT版本相关
TensorRT的版本与CUDA还有CUDNN版本是密切相关的,我们从官网下载TensorRT的时候应该就可以注意到:
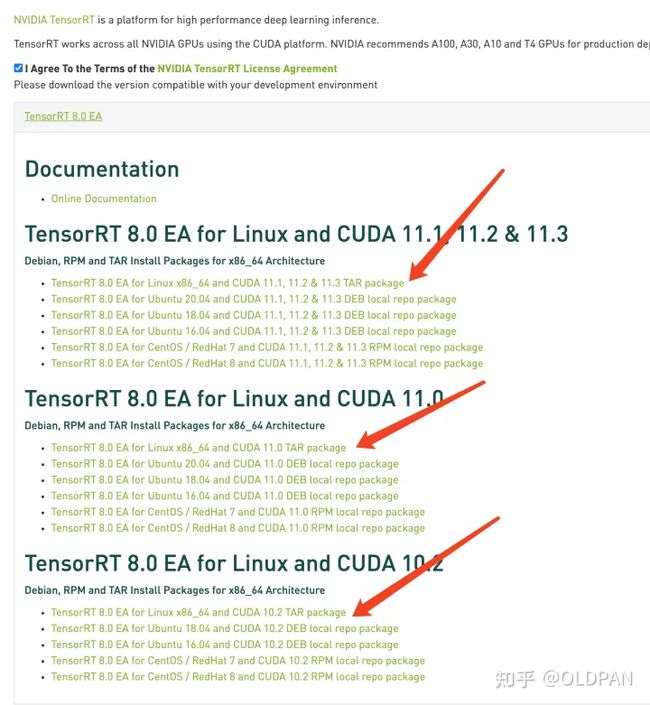
不匹配版本的cuda以及cudnn是无法和TensorRT一起使用的。
所以下载的时候要注意,不要搞错版本了哦。
关于如何选择合适自己的TensorRT版本,首先看驱动,其次看CUDA版本。
驱动怎么看,使用nvidia-smi命令即可:
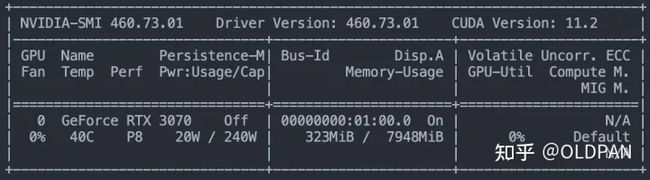
驱动可以通过root权限去换,而CUDA版本只要驱动满足要求就可以随便换(不需要root权限),这点注意下就好。
关于详细的环境配置可以看老潘之前的这篇文章:主机回来以及,简单的环境配置(RTX3070+CUDA11.1+CUDNN+TensorRT)
耍个小聪明,其实版本也不是严格限制的,只要是你需要的功能函数在这个低版本中存在,那也是可以使用的。
举个例子。
我们从官方下载的TensorRT-7.0.0.11.Ubuntu-16.04.x86_64-gnu.cuda-10.2.cudnn7.6.tar依赖libcudnn.so.7.6.0。但我们使用libcudnn.so.7.3.0去跑这个TensorRT去做一些事情时,因为版本不一致就会报错:
TensorRT-7.0.0.11/lib/libmyelin.so.1: undefined reference to `[email protected]'
TensorRT-7.0.0.11/lib/libmyelin.so.1: undefined reference to `cudnnGetBatchNormalizationForwardTrainingExWorkspaceSize@libcudnn.so.7'
TensorRT-7.0.0.11/lib/libmyelin.so.1: undefined reference to `cudnnGetBatchNormalizationTrainingExReserveSpaceSize@libcudnn.so.7'
TensorRT-7.0.0.11/lib/libmyelin.so.1: undefined reference to `[email protected]'
TensorRT-7.0.0.11/lib/libmyelin.so.1: undefined reference to `[email protected]'显然在链接TensorRT的时候,libmyelin.so.1这个东西需要的符号表在libcudnn.so.7.3.0这里找不到,因此也无法编译成功。
但是如果我们使用libcudnn.so.7.6.0将其编译好得到可执行文件,但跑这个程序时只给它提供libcudnn.so.7.3.0的运行环境。那么运行的时候会有 TensorRT was linked against cuDNN 7.6.3 but loaded cuDNN 7.3.0的提示,不过程序可以正常运行!
原因很简单,libcudnn.so.7.6.0所拥有的cudnnGetBatchNormalizationBackwardExWorkspaceSize虽然libcudnn.so.7.3.0没有,但是我们也不用它,所以程序可以正常运行而不会报错,但如果你需要这个函数调用这个函数那么就没有办法了。
通过strings命令观察可以看到libcudnn.so.7.3.0确实没有cudnnGetBatchNormalizationBackwardExWorkspaceSize这个函数实现:
strings /usr/local/cuda/lib64/libcudnn.so.7.3.0 | grep cudnnGetBatchNormalizationBackwardExWorkspaceSize
而7.6.5中有
strings /usr/local/cuda/lib64/libcudnn.so.7.6.5 | grep cudnnGetBatchNormalizationBackwardExWorkspaceSize
cudnnGetBatchNormalizationBackwardExWorkspaceSize
cudnnGetBatchNormalizationBackwardExWorkspaceSize更多关于动态链接库的细节可以(收藏必看系列)咱不知道的一些动态链接库小细节。
什么模型可以转换为TensorRT
TensorRT官方支持Caffe、Tensorflow、Pytorch、ONNX等模型的转换(不过Caffe和Tensorflow的转换器Caffe-Parser和UFF-Parser已经有些落后了),也提供了三种转换模型的方式:
- 使用
TF-TRT,将TensorRT集成在TensorFlow中 - 使用
ONNX2TensorRT,即ONNX转换trt的工具 - 手动构造模型结构,然后手动将权重信息挪过去,非常灵活但是时间成本略高,有大佬已经尝试过了:tensorrtx
不过目前TensorRT对ONNX的支持最好,TensorRT-8最新版ONNX转换器又支持了更多的op操作。而深度学习框架中,TensorRT对Pytorch的支持更为友好,除了Pytorch->ONNX->TensorRT这条路,还有:
- torch2trt
- torch2trt_dynamic
- TRTorch
总而言之,理论上95%的模型都可以转换为TensorRT,条条大路通罗马嘛。只不过有些模型可能转换的难度比较大。如果遇到一个无法转换的模型,先不要绝望,再想想,再想想,看看能不能通过其他方式绕过去。
TensorRT是否支持动态尺寸(dynamic shape)吗
支持,而且用起来还很方便,如果某些OP不支持,也可以自己写动态尺度的Plugin。
动态尺度支持NCHW中的N、H以及W,也就是batch、高以及宽。
对于动态模型,我们在转换模型的时候需要额外指定三个维度信息即可(最小、最优、最大)。
举个转换动态模型的命令:
./trtexec --explicitBatch --onnx=demo.onnx --minShapes=input:1x1x256x256 --optShapes=input:1x1x2048x2048 --maxShapes=input:1x1x2560x2560 --shapes=input:1x1x2048x2048 --saveEngine=demo.trt --workspace=6000很简单吧~
TensorRT是硬件相关的
这个很好明白,因为不同显卡(不同GPU),其核心数量、频率、架构、设计(还有价格..)都是不一样的,TensorRT需要对特定的硬件进行优化,不同硬件之间的优化是不能共享的。
The generated plan files are not portable across platforms or TensorRT versions. Plans are specific to the exact GPU model they were built on (in addition to platforms and the TensorRT version) and must be re-targeted to the specific GPU in case you want to run them on a different GPU
TensorRT是否开源
TensorRT是半开源的,除了核心部分其余的基本都开源了。TensorRT最核心的部分是什么,当然是官方展示的一些特性了。如下:
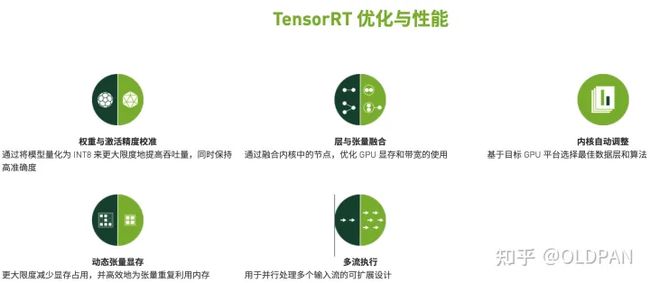
以上核心优势,也就是TensorRT内部的黑科技,可以帮助我们优化模型,加速模型推理,这部分当然是不开源的啦。
而开源的部分基本都在这个仓库里:
- TensorRT Open Source Software
插件相关、工具相关、文档相关,里面的资源还是挺丰富的。
Python中可以使用TensorRT吗
当然是可以的,官方有python的安装包(下文有说),安装后就可以import tensorrt使用了。
用ldd命令看一下tensorrt.so中都引用了什么。
ldd tensorrt.so
linux-vdso.so.1 => (0x00007ffe477d4000)
libnvinfer.so.7 => /TensorRT-7.0.0.11/lib/libnvinfer.so.7 (0x00007f2a76f6b000)
libnvonnxparser.so.7 => /TensorRT-7.0.0.11/lib/libnvonnxparser.so.7 (0x00007f2a76ca5000)
libnvparsers.so.7 => /TensorRT-7.0.0.11/lib/libnvparsers.so.7 (0x00007f2a76776000)
libnvinfer_plugin.so.7 => /TensorRT-7.0.0.11/lib/libnvinfer_plugin.so.7 (0x00007f2a758e2000)
libstdc++.so.6 => /TensorRT-7.0.0.11/lib/libstdc++.so.6 (0x00007f2a75555000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007f2a7532f000)
libc.so.6 => /lib64/libc.so.6 (0x00007f2a74f61000)
libcudnn.so.7 => /usr/local/cuda/lib64/libcudnn.so.7 (0x00007f2a60768000)
libcublas.so.10.0 => /usr/local/cuda/lib64/libcublas.so.10.0 (0x00007f2a5c1d2000)
libcudart.so.10.0 => /usr/local/cuda/lib64/libcudart.so.10.0 (0x00007f2a5bf57000)
libmyelin.so.1 => /TensorRT-7.0.0.11/lib/libmyelin.so.1 (0x00007f2a5b746000)
libnvrtc.so.10.0 => /usr/local/cuda/lib64/libnvrtc.so.10.0 (0x00007f2a5a12a000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f2a59f25000)
libm.so.6 => /lib64/libm.so.6 (0x00007f2a59c23000)
/lib64/ld-linux-x86-64.so.2 (0x00007f2a84f5c000)
libprotobuf.so.16 => /onnx-tensorrt/protobuf-3.6.0/lib/libprotobuf.so.16 (0x00007f2a597ad000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f2a59591000)
librt.so.1 => /lib64/librt.so.1 (0x00007f2a59389000)
libz.so.1 => /lib64/libz.so.1 (0x00007f2a59172000)TensorRT部署相关
部署TensorRT的方式,官方提供了三种:
- 集成在Tensorflow中使用,比例TF-TRT,这种操作起来比较便捷,但是加速效果并不是很好;
- 在TensorRT Runtime环境中运行模型,就是直接使用TensorRT;
- 搭配服务框架使用,最配的就是官方的triton-server,完美支持TensorRT,用在生产环境杠杠的!
TensorRT支持哪几种权重精度
支持FP32、FP16、INT8、TF32等,这几种类型都比较常用。
- FP32:单精度浮点型,没什么好说的,深度学习中最常见的数据格式,训练推理都会用到;
- FP16:半精度浮点型,相比FP32占用内存减少一半,有相应的指令值,速度比FP32要快很多;
- TF32:第三代Tensor Core支持的一种数据类型,是一种截短的 Float32 数据格式,将FP32中23个尾数位截短为10bits,而指数位仍为8bits,总长度为19(=1+8 +10)。保持了与FP16同样的精度(尾数位都是 10 位),同时还保持了FP32的动态范围指数位都是8位);
- INT8:整型,相比FP16占用内存减小一半,有相应的指令集,模型量化后可以利用INT8进行加速。
简单展示下各种精度的区别:

简单举一个例子吧!
说了那么多理论知识,不来个栗子太说不过去了。
这个例子的目的很简单,就是简单展示一下使用TensorRT的一种场景以及基本流程。假设老潘有一个onnx模型想要在3070卡上运行,并且要快,这时候就要祭出TensorRT了。
关于什么是ONNX(ONNX是一个模型结构格式,方便不同框架之间的模型转化例如Pytorch->ONNX->TRT)可以看这个,这里先不细说了~
老潘手头没有现成训练好的模型,直接从开源项目中白嫖一个吧。找到之前一个比较有趣的项目,可以通过图片识别三维人体关键点,俗称人体姿态检测,项目地址在此:
- https://github.com/digital-standard/ThreeDPoseUnityBarracuda
实现的效果如下,该模型的精度还是可以的,但是画面中只能出现一个目标人物。速度方面的话,主页有介绍:
- GeForce RTX2070 SUPER ⇒ About 30 FPS
- GeForce GTX1070 ⇒ About 20 FPS

让我们来试试TensorRT能够在3070卡上为其加速多少吧。
看一下模型结构
用到的核心模型在Github主页有提供,即ONNX模型Resnet34_3inputs_448x448_20200609.onnx。作者演示使用的是Unity与Barracuda,其中利用Barracuda去加载onnx模型然后去推理。
我们先用Netron去观察一下这个模型结构,3个输入4个输出,为什么是3个输入呢?其实这三个输入在模型的不同阶段,作者训练的时候的输入数据可能是从视频中截出来的连续3帧的图像,这样训练可以提升模型的精度(之后模型推理的时候也需要一点时间的预热,毕竟3帧的输入也是有是时间连续性的):

使用onnxruntime验证一下模型
一般来说,我们在通过不同框架(Pytorch、TF)转换ONNX模型之后,需要验证一下ONNX模型的准确性,否则错误的onnx模型转成的TensorRT模型也100%是错误的。
但显然上述作者提供的Resnet34_3inputs_448x448_20200609.onnx是验证过没问题的,但这边我们也走一下流程,以下代码使用onnxruntime去运行:
import onnx
import numpy as np
import onnxruntime as rt
import cv2
model_path = '/home/oldpan/code/models/Resnet34_3inputs_448x448_20200609.onnx'
# 验证模型合法性
onnx_model = onnx.load(model_path)
onnx.checker.check_model(onnx_model)
# 读入图像并调整为输入维度
image = cv2.imread("data/images/person.png")
image = cv2.resize(image, (448,448))
image = image.transpose(2,0,1)
image = np.array(image)[np.newaxis, :, :, :].astype(np.float32)
# 设置模型session以及输入信息
sess = rt.InferenceSession(model_path)
input_name1 = sess.get_inputs()[0].name
input_name2 = sess.get_inputs()[1].name
input_name3 = sess.get_inputs()[2].name
output = sess.run(None, {input_name1: image, input_name2: image, input_name3: image})
print(output)打印一下结果看看是什么样子吧~其实输出信息还是很多的,全粘过来太多了,毕竟这个模型的输出确实是多...这里只截取了部分内容意思一哈:
2021-05-05 10:44:08.696562083 [W:onnxruntime:, graph.cc:3106 CleanUnusedInitializers] Removing initializer 'offset.1.num_batches_tracked'. It is not used by any node and should be removed from the model.
...
[array([[[[ 0.16470502, 0.9578098 , -0.82495296, ..., -0.59656703,
0.26985374, 0.5808018 ],
[-0.6096473 , 0.9780458 , -0.9723106 , ..., -0.90165156,
-0.8959699 , 0.91829604],
[-0.03562748, 0.3730615 , -0.9816262 , ..., -0.9905239 ,
-0.4543069 , 0.5840921 ],
...,
...,
[0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[0. , 0. , 0. , ..., 0. ,
0. , 0. ]]]], dtype=float32)]看到Removing initializer 'offset.1.num_batches_tracked'. It is not used by any node and should be removed from the model这个提示我亲切地笑了,这不就是用Pytorch训练的么,看来作者这个模型也是通过Pytorch训练然后导出来的。
怎么对比下ONNX和Pytorch输出结果是否一致呢?可以直接看到输出的数值是多少,但是这个模型的输出还是比较多的,直接通过肉眼对比转换前后的结果是不理智的。我们可以通过代码简单对比一下:
y = model(x)
y_onnx = model_onnx(x)
# check the output against PyTorch
print(torch.max(torch.abs(y - y_trt)))ONNX转换为TensorRT模型
ONNX模型转换TensorRT模型还是比较容易的,目前TensorRT官方对ONNX模型的支持最好,而且后续也会将精力重点放到ONNX上面(相比ONNX,UFF、Caffe这类转换工具可能不会再更新了)。
目前官方的转换工具TensorRT Backend For ONNX(简称ONNX-TensorRT)已经比较成熟了,开发者也在积极开发,提issue官方回复的也比较快。我们就用上述工具来转一下这个模型。
我们不需要克隆TensorRT Backend For ONNX,之前下载好的TensorRT包中已经有这个工具的可执行文件了,官方已经替我们编译好了,只要我们的环境符合要求,是直接可以用的。
到TensorRT-7.2.3.4/bin中直接使用trtexec这个工具,这个工具可以比较快速地转换ONNX模型以及测试转换后的trt模型有多快:
- https://github.com/NVIDIA/TensorRT/blob/master/samples/opensource/trtexec/README.md
我们使用命令转换,可以看到输出信息:
&&&& RUNNING TensorRT.trtexec # ./trtexec --onnx=Resnet34_3inputs_448x448_20200609.onnx --saveEngine=Resnet34_3inputs_448x448_20200609.trt --workspace=6000
[05/09/2021-17:00:50] [I] === Model Options ===
[05/09/2021-17:00:50] [I] Format: ONNX
[05/09/2021-17:00:50] [I] Model: Resnet34_3inputs_448x448_20200609.onnx
[05/09/2021-17:00:50] [I] Output:
[05/09/2021-17:00:50] [I] === Build Options ===
[05/09/2021-17:00:50] [I] Max batch: explicit
[05/09/2021-17:00:50] [I] Workspace: 6000 MiB
[05/09/2021-17:00:50] [I] minTiming: 1
[05/09/2021-17:00:50] [I] avgTiming: 8
[05/09/2021-17:00:50] [I] Precision: FP32
[05/09/2021-17:00:50] [I] Calibration:
[05/09/2021-17:00:50] [I] Refit: Disabled
[05/09/2021-17:00:50] [I] Safe mode: Disabled
[05/09/2021-17:00:50] [I] Save engine: Resnet34_3inputs_448x448_20200609.trt
[05/09/2021-17:00:50] [I] Load engine:
[05/09/2021-17:00:50] [I] Builder Cache: Enabled
[05/09/2021-17:00:50] [I] NVTX verbosity: 0
[05/09/2021-17:00:50] [I] Tactic sources: Using default tactic sources
[05/09/2021-17:00:50] [I] Input(s)s format: fp32:CHW
[05/09/2021-17:00:50] [I] Output(s)s format: fp32:CHW
...
[05/09/2021-17:02:32] [I] Timing trace has 0 queries over 3.16903 s
[05/09/2021-17:02:32] [I] Trace averages of 10 runs:
[05/09/2021-17:02:32] [I] Average on 10 runs - GPU latency: 4.5795 ms
[05/09/2021-17:02:32] [I] Average on 10 runs - GPU latency: 4.6697 ms
[05/09/2021-17:02:32] [I] Average on 10 runs - GPU latency: 4.6537 ms
[05/09/2021-17:02:32] [I] Average on 10 runs - GPU latency: 4.5953 ms
[05/09/2021-17:02:32] [I] Average on 10 runs - GPU latency: 4.6333 ms
[05/09/2021-17:02:32] [I] Host Latency
[05/09/2021-17:02:32] [I] min: 4.9716 ms (end to end 108.17 ms)
[05/09/2021-17:02:32] [I] max: 4.4915 ms (end to end 110.732 ms)
[05/09/2021-17:02:32] [I] mean: 4.0049 ms (end to end 109.226 ms)
[05/09/2021-17:02:32] [I] median: 4.9646 ms (end to end 109.241 ms)
[05/09/2021-17:02:32] [I] percentile: 4.4915 ms at 99% (end to end 110.732 ms at 99%)
[05/09/2021-17:02:32] [I] throughput: 0 qps
[05/09/2021-17:02:32] [I] walltime: 3.16903 s
[05/09/2021-17:02:32] [I] Enqueue Time
[05/09/2021-17:02:32] [I] min: 0.776001 ms
[05/09/2021-17:02:32] [I] max: 1.37109 ms
[05/09/2021-17:02:32] [I] median: 0.811768 ms
[05/09/2021-17:02:32] [I] GPU Compute
[05/09/2021-17:02:32] [I] min: 4.5983 ms
[05/09/2021-17:02:32] [I] max: 4.1133 ms
[05/09/2021-17:02:32] [I] mean: 4.6307 ms
[05/09/2021-17:02:32] [I] median: 4.5915 ms
[05/09/2021-17:02:32] [I] percentile: 4.1133 ms at 99%其中FP32推理速度是4-5ms左右,而FP16只需要1.6ms。
PS:关于ONNX-TensorRT这个工具,本身是由C++写的,整体结构设计的比较紧凑,值得一读,之后老潘会讲述ONNX-TensorRT这个工具的编译和使用方法。
运行TensorRT模型
这里我们使用TensorRT的Python端加载转换好的resnet34_3dpose.trt模型。使用Python端时首先需要安装TensorRT-tar包下的pyhton目录下的tensorrt-7.2.3.4-cp37-none-linux_x86_64.whl安装包,目前7.0支持最新的python版本为3.8,而TensorRT-8-EA则开始支持python-3.9了。
安装Python-TensorRT后,首先import tensorrt as trt。
然后加载Trt模型:
logger = trt.Logger(trt.Logger.INFO)
with open("resnet34_3dpose.trt", "rb") as f, trt.Runtime(logger) as runtime:
engine=runtime.deserialize_cuda_engine(f.read())加载好之后,我们打印下这个模型的输入输出信息,观察是否与ONNX模型一致:
for idx in range(engine.num_bindings):
is_input = engine.binding_is_input(idx)
name = engine.get_binding_name(idx)
op_type = engine.get_binding_dtype(idx)
model_all_names.append(name)
shape = engine.get_binding_shape(idx)
print('input id:',idx,' is input: ', is_input,' binding name:', name, ' shape:', shape, 'type: ', op_type)可以看到:
engine bindings message:
input id: 0 is input: True binding name: input.1 shape: (1, 3, 448, 448) type: DataType.FLOAT
input id: 1 is input: True binding name: input.4 shape: (1, 3, 448, 448) type: DataType.FLOAT
input id: 2 is input: True binding name: input.7 shape: (1, 3, 448, 448) type: DataType.FLOAT
input id: 3 is input: False binding name: 499 shape: (1, 24, 28, 28) type: DataType.FLOAT
input id: 4 is input: False binding name: 504 shape: (1, 48, 28, 28) type: DataType.FLOAT
input id: 5 is input: False binding name: 516 shape: (1, 672, 28, 28) type: DataType.FLOAT
input id: 6 is input: False binding name: 530 shape: (1, 2016, 28, 28) type: DataType.FLOAT3个输入4个输出,完全一致没有问题!
然后载入图像,运行模型:
image = cv2.imread(image_path)
image = cv2.resize(image, (200,64))
image = image.transpose(2,0,1)
img_input = image.astype(np.float32)
img_input = torch.from_numpy(img_input)
img_input = img_input.unsqueeze(0)
img_input = img_input.to(device)
# 运行模型
result_trt = trt_model(img_input)咦?这么简单么,trt的engine在哪儿?
当然不是,其实这个trt_model是一个类,我们这样使用它:
# engine即上述加载的engine
trt_model = TRTModule(engine, ["input.1", "input.4", "input.7"])而这个TRTModule是什么呢,为了方便地加载TRT模型以及创建runtime,我们借鉴torch2trt这个库中的一个实现类,比较好地结合了Pytorch与TensorRT,具体实现如下:
class TRTModule(torch.nn.Module):
def __init__(self, engine=None, input_names=None, output_names=None):
super(TRTModule, self).__init__()
self.engine = engine
if self.engine is not None:
# engine创建执行context
self.context = self.engine.create_execution_context()
self.input_names = input_names
self.output_names = output_names
def forward(self, *inputs):
batch_size = inputs[0].shape[0]
bindings = [None] * (len(self.input_names) + len(self.output_names))
for i, input_name in enumerate(self.input_names):
idx = self.engine.get_binding_index(input_name)
# 设定shape
self.context.set_binding_shape(idx, tuple(inputs[i].shape))
bindings[idx] = inputs[i].contiguous().data_ptr()
# create output tensors
outputs = [None] * len(self.output_names)
for i, output_name in enumerate(self.output_names):
idx = self.engine.get_binding_index(output_name)
dtype = torch_dtype_from_trt(self.engine.get_binding_dtype(idx))
shape = tuple(self.context.get_binding_shape(idx))
device = torch_device_from_trt(self.engine.get_location(idx))
output = torch.empty(size=shape, dtype=dtype, device=device)
outputs[i] = output
bindings[idx] = output.data_ptr()
self.context.execute_async_v2(bindings,
torch.cuda.current_stream().cuda_stream)
outputs = tuple(outputs)
if len(outputs) == 1:
outputs = outputs[0]
return outputs我们重点看__init__()和forward这两个成员方法,即engine创建context,然后确定输入输出,执行execute_async_v2即可获取结果。
就这样,使用TensorRT调用已经序列化好的trt模型就成功啦。
利用Polygraphy查看ONNX与TRT模型的输出差异
Polygraphy是TensorRT官方提供的一系列小工具合集,通过这个工具我们看一下这个Resnet34_3inputs_448x448_20200609.onnx模型在转换为trt之后是否会有精度折损:
首先看一下FP32精度:

再看下FP16精度:

这里的绝对误差和相对误差容忍度设置的均为1e-3,精确到小数点后3位,可以看到上述onnx模型在转化为FP32的trt是没有大问题的,而FP16则有比较多的精度折损。至于会不会严重地影响结果需要我们通过具体或者一批case分析。限于篇幅放到后续说。
例子就这样~
TensorRT的缺点
TensorRT不是没有“缺点”的,有一些小小的缺点需要吐槽一下:
- 经过infer优化后的模型与特定GPU绑定,例如在1080TI上生成的模型在2080TI上无法使用;
- 高版本的TensorRT依赖于高版本的CUDA版本,而高版本的CUDA版本依赖于高版本的驱动,如果想要使用新版本的TensorRT,更换环境是不可避免的;
- TensorRT尽管好用,但推理优化infer还是闭源的,像深度学习炼丹一样,也像个黑盒子,使用起来会有些畏手畏脚,不能够完全掌控。所幸TensorRT提供了较为多的工具帮助我们调试。
正所谓爱之深恨之切,老潘也知道,这些”缺点“也是没有办法的缺点,既然无法避免,就轻轻吐槽一下吧。
TensorRT配套周边
TensorRT毕竟发展这么多年了,官方也深知大家使用TensorRT的一些痛点,所以开发了一些比较实用的小工具来供大家使用,工具目前在TensorRT的开源主页,也就是说这些工具也是开源的:

这三个工具的基本功能大概介绍下:
- ONNX GraphSurgeon 可以修改我们导出的ONNX模型,增加或者剪掉某些节点,修改名字或者维度等等
- Polygraphy 各种小工具的集合,例如比较ONNX和trt模型的精度,观察trt模型每层的输出等等,主要用来debug一些模型的信息,还是比较有用的
- PyTorch-Quantization 可以在Pytorch训练或者推理的时候加入模拟量化操作,从而提升量化模型的精度和速度,并且支持量化训练后的模型导出ONNX和TRT
老潘用过ONNX GraphSurgeon以及Polygraphy,两者都是在实际部署转换中比较实用的工具,也确实解决了一些问题。唯一不足的是这些工具的教程都不是很详细,较难上手,之后老潘也会详细介绍一哈这些工具的使用方法。
参考链接
- TensorRT-Index:https://docs.nvidia.com/deeplearning/tensorrt/quick-start-guide/index.html
- API:https://docs.nvidia.com/deeplearning/tensorrt/api/
- ONNX GraphSurgeon: https://docs.nvidia.com/deeplearning/tensorrt/onnx-graphsurgeon/docs/index.html
- https://docs.nvidia.com/deeplearning/tensorrt/quick-start-guide/index.html
后记
写不动了先这样吧...关于TensorRT想写的还有很多,不想错过可以关注我哦,希望这篇文章能够对学习TensorRT的各位有些帮助~
个人来讲,TensorRT最好的学习方式还是实战,只有踩过一些坑,改过一些代码,跑通过一些程序,才能更好地学习TensorRT。而所谓的那么些文档,也无非是帮助我们少踩些坑罢了。无论如何,大部分坑该踩的还是踩的,不要等准备好再上,赶紧的,代码跑起来吧!
往期精选
技术综述:
- 综述:图像处理中的注意力机制
- 搞懂Transformer结构,看这篇PyTorch实现就够了
- YOLO算法最全综述:从YOLOv1到YOLOv5
- 图像匹配大领域综述!涵盖 8 个子领域,近 20年经典方法汇总
- 一文读懂深度学习中的各种卷积
- 万字综述|核心开发者全面解读Pytorch内部机制
- 19个损失函数汇总,以Pytorch为例
顶会资源:
- CVPR 2021 结果出炉!最新500篇CVPR'21论文分方向汇总(更新中)
- CVPR 2020 Oral 汇总:论文/代码/解读(更新中)
- CVPR 2019 最全整理:全部论文下载,Github源码汇总、直播视频、论文解读等
- CVPR 2018 论文解读集锦(9月27日更新)
- CVPR 2018 目标检测(object detection)算法总览
- ECCV 2018 目标检测(object detection)算法总览(部分含代码)
- CVPR 2017 论文解读集锦(12-13更新)
- 2000 ~2020 年历届 CVPR 最佳论文汇总
理论深挖:
- 深入探讨:为什么要做特征归一化/标准化?
- 令人“细思极恐”的Faster-R-CNN
论文盘点:
- 图像分割二十年,盘点影响力最大的10篇论文
- 2020年54篇最新CV领域综述论文速递!涵盖14个方向:目标检测/图像分割/医学影像/人脸识别等
数据集:
- 人脸识别常用数据集大全
- 行人检测数据集汇总
实践/面经/求学:
- 如何配置一台深度学习工作站?
- 国内外优秀的计算机视觉团队汇总
- 50种Matplotlib科研论文绘图合集,含代码实现
Github优质资源:
- 25个【Awsome】GitHub 资源汇总(更新中)
- 超强合集:OCR 文本检测干货汇总(含论文、源码、demo 等资源)
- 2019-2020年目标跟踪资源全汇总(论文、模型代码、优秀实验室)