Qualcomm NPU 高通神经网络处理芯片
“专人专事专办”听起来是个很诱人的事情,当在某一方面有需要就去找专门对应的人员或是硬件进行快速处理和反馈,这个道理似乎很简单。然而在当今的移动领域满足人工智能运算需求这方面,移动平台制造商们分成了2个派系。其一是“专人专事专办”的独立NPU;与之对立的是以“人多力量大”为指导,调用整个芯片不同组件的不同内核进行异构运算。
说实话我们对独立NPU这东西其实抱着一定的怀疑态度,并且并不认为它绝对能够大幅度增强一个移动平台整体的人工智能性能。给移动平台芯片内增加一个NPU专门处理人工智能运算任务,就好像ZAEKE知客招聘一个全职摄影师专门负责帮编辑们拍摄评测所需配图一样,听起来似乎是各司其职的好想法但实际执行起来却并不那么理想。
原因很简单,因为每个编辑在写文章的时候都会有自己的想法。所以那位全职摄影师不但要有良好的拍照技术和效率,更要能充分理解每位编辑在写每一篇文章时的想法,才能做到真正的图文和谐。而真正有这个本事的摄影师大多不是ZAEKE知客这座小庙容得下的大佛,更别提额外的薪资支出了。
虽然这话有点糙,但道理就是这样。因为一个专精于某一种应用的单元虽然在处理自己对应的任务时可以兼顾高性能和低功耗,但是在进行其他应用的时候这一单元却不能发挥作用。如果一个NPU需要跟上快速发展的移动人工智能的步伐,那么移动平台的制造方智能无休无止地给这个NPU做加法,导致这个NPU在每次更新换代后变得更大更耗电,新的人工智能应用也不能被旧的NPU加速,最终背离为移动平台芯片加入NPU的初衷。
所以不管从什么角度来看,让写稿的编辑自己根据自己需要去准备配图都是最好的方案(笑)。

人工智能并不是一颗芯片,或是芯片里某一个单元的事情——前面派系2的主推者高通就是这么认为的。
这就是高通这边一直很排斥“NPU”这个说法,而不停地强调“高通人工智能引擎AI Engine”这一概念的原因。高通的理念很简单,通过一款移动平台内部CPU、GPU和DSP(Hexagon处理器)的协作,或专业点称之为“异构计算”,将不同的人工智能运算需求分配到移动平台中不同的部分,最终实现在整个移动平台内部高效且快速地完成人工智能运算任务。
高通人工智能引擎AI Engine这个概念最早可以追溯至2015年,当年高通推出了骁龙820。在这款当年的旗舰移动平台上,高通特别将DSP作为整个芯片的一个重要组成部分提及,并且也启用了新的Hexagon 680命名。Hexagon 680 DSP和高通之前集成于移动平台中的DSP相比新增了“向量扩展(HVX)”单元,让DSP在移动设备运行的过程中参与到计算和处理里面去,降低移动平台整体功耗的同时,提升处理速度。
当然,在那个时候“人工智能”的概念远不如今天这般火热,所以高通人工智能引擎AI Engine这个名字是在稍迟些时候,也就是支持AI Engine的高通骁龙660发布之后才大规模进入我们的视野。

在即将标配于众多2019旗舰智能手机里的骁龙855中,高通人工智能引擎发展至了第四代。第四代AI Engine依旧是用着CPU、GPU和DSP处理器多处理内核协作的异构运算策略。得益于技术的发展,第4代AI Engine每秒钟能够进行超过7万亿次运算——其性能达到了上一代产品(骁龙845)的3倍以及竞争对手的2倍。
这些性能提升从何而来呢?
从最好理解的开始,是全新的7nm制程工艺带来的性能密度提升,制程工艺的进步使得移动平台芯片本身的性能比起上一代就上了一个台阶。Kryo 485 CPU不仅拥有比上一代产品高45%的性能,还支持全新的点积指令。而且,Adreno 640 GPU的算术逻辑单元(ALU)数量比起上一代产品增加了50%,整体性能提升20%。
至于新一代的Hexagon 690处理器,改变就更多了。
在高通,Hexagon DSP有了简单易懂的名号,开始“自立门户”的那天起,搭载了Hexagon DSP的设备在人工智能领域就有硬件层面的优势。因为首先和固定功能的“NPU”相比,Hexagon DSP拥有更高的可编程性和客制化能力,并且拥有极为优秀的多线程与平行运算能力,使得设备的机器学习性能更强。
其次,由于高通当时在设计Hexagon DSP之初就坚定了异构计算的策略,于是在骁龙移动平台中的Hexagon DSP拥有一条直接连接至影像传感器的总线。如此在进行图像识别、AR/XR等应用场景下,影像传感器捕捉的图像可以直接被DSP读取而不经过设备的内存,大大缩短了影像处理所需要的时间——事实上谷歌在研发出自己的Pixel Visual Core芯片之前,就是利用高通Hexagon DSP来处理HDR+的繁重计算任务。曾经昙花一现,支持的谷歌Project Tango的华硕ZenFone AR也利用了这一特性来加速AR视觉的生成。
在新一代的Hexagon 690处理器里面,高通直接将内置向量扩展内核(HVX)的数量翻番至4个,以更好地配合同样集成于Hexagon 690里面的4个线程标量内核。当然因为制程工艺和架构设计的进步,Hexagon 690 里本身单个HVX的性能就比上一代强了20%。

Hexagon 690里面的另一个重要创新,在于一个全新设计的Hexagon张量加速器(Hexagon Tensor Accelerator,HTA)的加入,在业界可能会被称之为NPU、DLA、神经网络引擎等等,这也是张量加速单元首次出现在移动平台芯片当中。对于Hexagon 690处理器以及整个骁龙855移动芯片平台来说,HTA将作为硬件级别的加速器,专门针对高开销等级的矩阵乘法运算,以及在硬件层级作为非线性功能的加速器。
为啥Hexagon张量加速器(HTA)的加入对于Hexagon 690乃至整个第四代高通AI Engine是非常重要的嘞?因为对于计算机,尤其是智能手机这样的强调移动性的计算平台来说,进行张量计算,比如大规模乘法运算的代价非常高昂。单纯通过CPU或是GPU去进行运算不仅效率偏低,并且所需要的功耗也会直线上升。通过加入HTA张量加速器单元,移动平台就可以在运算效率和所消耗的电能之间取得平衡。
此外,在正式介绍Hexagon 690处理器的同时,高通表示还会在将来升级这个HTA模块,以便它支持更大规模的张量计算。这一模块作为Hexagon 690里面的重要组成部分,会和Hexagon中的标量以及向量运算模块共同完成所面对的人工智能运算。
简单点说,得益于新加入的HTA单元,Hexagon 690拥有更强的语音识别能力、机器学习能力以及图像识别能力。这一能力将帮助搭载骁龙855移动平台的设备更准确地识别唤醒热词、直接在本地进行语音指令分析以及基于人工智能的通话背景环境音消除;或者是对摄像头所拍摄到的画面进行更深度的优化,大幅度提升成片品质。
所以,Hexagon 690如今已经成为了在骁龙855移动平台中一个支持声音/图像处理、AI运算、机器学习、语音识别的重要部分。在整个高通人工智能引擎的架构中,它不仅肩负着低功耗快速处理相对较低精度人工智能运算需求的重任。还会智能地根据实际需要,以“上帝视角”在高通人工智能引擎内部分配计算任务——至于开发者所需要做的,只是将人工智能算法丢给骁龙855而已。
有意思的是,和独立的NPU那种类似于“专人专事专办”的设定相比,由于本身在设计之初就是走着异构计算的思路,所以由Kryo CPU、Adreno GPU以及Hexagon处理器组成的高通 AI Engine有更高的开放程度。由于人工智能运算任务会在骁龙855移动平台内根据需要对运算任务灵活分配,也使得这套人工智能引擎系统能够被更轻松地应用到移动平台的其他部位,比如主要负责相机图像处理的ISP。
“AI相机”是个我们已经听得耳朵要长茧的营销词汇,而智能手机厂商们所推出的“AI相机”大部分指的是相机的场景识别功能。确实随着移动平台芯片性能的发展,乃至近年来移动平台人工智能运算能力的加强和独立NPU单元的加入,“AI相机”们识别场景的速度和准确度都让人刮目相看。
但是在我们看来,简单地将一个智能化场景识别功能当做“AI相机”未免有点太过片面了。人工智能这四个字本该有很多可能,场景识别只是其中一个。与相机结合的时候,人工智能的能力不该仅限于区分画面中的花花草草,然后给整个画面套一个艳丽到有些虚假的滤镜。

既然人工智能的应用领域包含有图像识别,那么为啥不想想办法让移动平台内部的图像处理器也聪明起来呢?
这就是骁龙855里人工智能技术另外一个重要的应用领域——计算机视觉ISP(CV-ISP)。骁龙855移动平台里面集成的Spectra 380 ISP是世界上第一个拥有计算机视觉功能的图像处理器,并且它在工作时还会和高通人工智能引擎AI Engine合作,将图像处理的效率和性能提升到全新的高水准。
在之前的移动平台中,图像处理器(ISP)的工作是将相机传感器(类似于人眼睛里的视网膜)获得的原生RAW信号进行转换获得照片,相对来说是个功能非常单一的模块(类似于人大脑中的视觉中枢)。至于那些听起来高大上又酷炫得很的场景识别、物体追踪则是由移动平台芯片中其他部分(类似于人类大脑中负责认知的部分)去观察、处理和计算由ISP传来的照片完成的。
而高通Spectra 380之所以能被称为“CV-ISP”,就是因为这颗ISP本身具有了一定的“认知能力”。或者换句话说,高通将人工智能中的计算机视觉特性“下放”到了Spectra 380里面。如此它能够在处理原生图像信号的同时“看懂”一部分画面,从而大幅度减轻芯片里其他参与到人工智能运算的组件的工作负担,在骁龙855上就是CPU、GPU和Hexagon处理器这三大件。
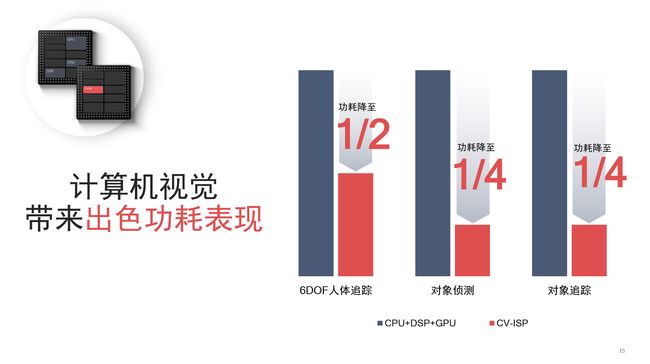
得益于计算机视觉特性的帮助,Spectra 380支持原生的,硬件层级的多对象分类、多对象追踪、背景分割、6DoF人体追踪和基于计算机视觉的防抖。这就像将已经洗净拣好的新鲜食材放到大厨面前一般,能大幅度提升运算效率并且降低功耗。使用Spectra 380进行6DoF人体追踪、对象侦测和对象追踪的功耗仅有单纯使用CPU+DSP+GPU进行运算的1/2、1/4和1/4。为ISP加入计算机视觉技术之后,移除了制约着整个移动平台在进行影像处理任务时的性能瓶颈。
在这颗CV-ISP和第四代高通人工智能引擎的加持下,高通骁龙855移动平台能够在记录4K HDR 60fps视频的同时分析画面的同时将拍摄主题和拍摄背景完全分离,进行背景虚化、替换或是生成AR/XR影像。这不仅对于智能手机十分有意义,更让骁龙855很适合用于新一代的AR/VR/XR头戴显示装置。
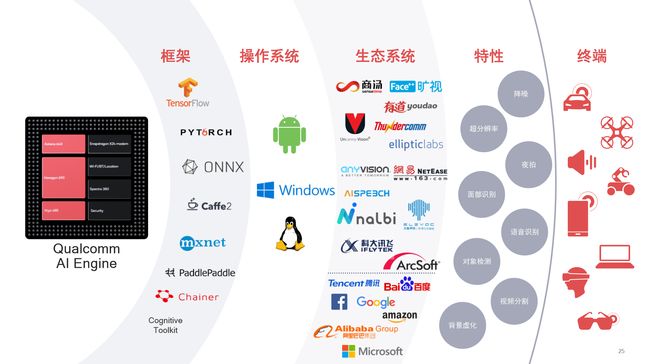
将眼光投向骁龙855之外,高通人工智能引擎AI Engine还催生了一个生机勃勃并且处于迅速发展中的巨大生态系统。
首先得益于与微软的合作,高通的移动平台如今可被用于打造全天在线的Windows PC,这也意味着高通人工智能引擎是目前世界上唯一一个覆盖了Windows、Android和Linux三大操作系统的人工智能生态。
Windows平台的开发者也能够利用高通人工智能引擎打造相关的应用。其次通过广泛的人工智能语言支持以及Hexagon神经网络库,应用开发者能够直接将人工智能算法部署于Hexagon向量处理器,加速人工智能应用的运行和激活。
最后也是最重要的,因为骁龙处理器被广泛应用于各个层级的Android智能手机中,所以也为高通人工智能引擎提供了巨大的用户基数。这也刺激了更多软件开发商们进行深入的开发和投入。
比如国内知名的人工智能开发商商汤与旷视科技,就在骁龙移动平台上提供包括单相机背景虚化、面部解锁等特性在内的神经网络应用。在拍照领域拥有极高知名度的虹软则非常积极地在这一平台上开发包含人工智能特性的用户体验。另外,在2018年百度则宣布采用高通人工智能引擎AI Engine,以加速自己PaddlePaddle深度学习平台的应用。

虽然基于智能手机等移动设备的人工智能已经发展了1~2年,并且取得了相当的成果。可在放眼全局的时候,其实不难看出整个人工智能产业依旧处于初级,甚至只是萌芽阶段而已。
这也是如今人工智能行业中各种解决方案百花齐放百家争鸣的重要原因之一,在这个新兴的行业和领域里面,每家都希望自己的方案能够迅速抢占市场并且最终成为行业标准,种竞争则是能够和市场需求一起促进整个行业的进步。基于智能手机的人工智能,也从最早单纯的系统级语音助手,发展成根植在软件中和硬件芯片里全面提升设备运行效率和使用体验的重要工具。
所以从这个角度出发,在打造一台具有人工智能特性的手机、汽车乃至生产机械的时候,并不只是简单地塞个“NPU”然后把一切相关的运算都丢过去。因为哪怕是发达如人类大脑这样的器官,也拥有功能截然不同的分区和神经中枢。
比如我们之所以能认出苹果是苹果,是因为我们的视觉中枢认出了苹果的颜色,或是因为我们的触觉中枢感受到了苹果的形状,也可以是因为我们的味觉中枢尝出了苹果的香甜。而不是因为我们的大脑里头有个所谓的“NPU”,在从视网膜或指尖神经或味觉细胞处获得了信息并计算之后告诉我们的意识“这是个苹果”,这样速度太慢效率也不够高。
所以答应我,别再把有没有“NPU”当做评价人工智能的唯一标准了,好吗?