DETR训练VOC数据集
在学习DETR过程中,原模型用的COCO数据集,训练的太慢了,故使用VOC数据集。网上找了好长好长时间,好多博客都走不通,特此记录一下。
1. 数据集准备
数据集转换目标:文件夹名为coco, 里面包含以下几个文件夹:

1.1 标注划分
首先, 根据VOC数据集中的train.txt和val.txt两个记事本(两个记事本位置在VOCdevkit -->VOC 2012-->ImageSets-->Main), 将voc数据集中的标注文件(文件夹位置在:VOCdevkit-->VOC2012-->Annotations)划分为训练集和测试集,划分保存的文件夹名分别为train和val. 划分代码如下:
from PIL import Image
import os
f3 = open("E:/VOCdevkit/VOC2012/ImageSets/Main/val.txt", 'r')
# txt文件所在路径
for line2 in f3.readlines():
line3 = line2[:-1]
xmldir = 'E:/VOCdevkit/VOC2012/Annotations' # 所有的xml文件绝对路径
savedir = './val/'
# 将用于xml文件提取出来的绝对路径
xmllist = os.listdir(xmldir)
for xml in xmllist:
# if '.xml' in xml:
if '.xml' in xml:
if line3 in xml:
fo = open(savedir + '/' + '{}'.format(xml), 'w')
fi = open(xmldir + '/' + '{}'.format(xml), 'r')
content = fi.readlines()
for line in content:
fo.write(line)
fo.close()
f3.close()
1.2 图像划分
其次,根据划分好的标注文件夹将图像(文件夹位置在:VOCdevkit-->VOC2012-->JPE GImages)划分为训练集和测试集,划分保存的文件夹名分别为train2017和val2017. 划分代码如下:
# 将图片根据xml中的文件名挑选出来
from PIL import Image
import os
def convert(input_dir1, input_dir2, output_dir):
for filename in os.listdir(input_dir1):
for filename1 in os.listdir(input_dir2):
path = input_dir1 + "/" + filename # 图片路径
path1 = input_dir2 + '/' + filename1 # xml路径
if path1[-10:-4] == path[-10:-4]: # 只有图片代号和xml代号相等的时候才会保存
image = Image.open(path)
image.save(output_dir + "/" + filename[:-4] + ".jpg")
if __name__ == '__main__':
input_dir1 = "E:/VOCdevkit/VOC2012/JPEGImages" # 输入图片路径
input_dir2 = "./val" # 输入标注路径
output_dir = "./val2017" # 保存路径
convert(input_dir1, input_dir2, output_dir)(注:图像划分也可直接根据train.txt和val.txt两个记事本进行划分)
1.3 json文件生成
最后,根据train.txt和val.txt两个记事本将VOC数据集的标注文件划分为coco数据集格式的json文件,并将生成的json文件分别命名为instances_train2017.json和instances_val2017.json, 然后将其挪到annotations文件夹下。代码如下:
import xml.etree.ElementTree as ET
import os
import json
voc_clses = ['aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
categories = []
for iind, cat in enumerate(voc_clses):
cate = {}
cate['supercategory'] = cat
cate['name'] = cat
cate['id'] = iind
categories.append(cate)
def getimages(xmlname, id):
sig_xml_box = []
tree = ET.parse(xmlname)
root = tree.getroot()
images = {}
for i in root: # 遍历一级节点
if i.tag == 'filename':
file_name = i.text # 0001.jpg
# print('image name: ', file_name)
images['file_name'] = file_name
if i.tag == 'size':
for j in i:
if j.tag == 'width':
width = j.text
images['width'] = width
if j.tag == 'height':
height = j.text
images['height'] = height
if i.tag == 'object':
for j in i:
if j.tag == 'name':
cls_name = j.text
cat_id = voc_clses.index(cls_name) + 1
if j.tag == 'bndbox':
bbox = []
xmin = 0
ymin = 0
xmax = 0
ymax = 0
for r in j:
if r.tag == 'xmin':
xmin = eval(r.text)
if r.tag == 'ymin':
ymin = eval(r.text)
if r.tag == 'xmax':
xmax = eval(r.text)
if r.tag == 'ymax':
ymax = eval(r.text)
bbox.append(xmin)
bbox.append(ymin)
bbox.append(xmax - xmin)
bbox.append(ymax - ymin)
bbox.append(id) # 保存当前box对应的image_id
bbox.append(cat_id)
# anno area
bbox.append((xmax - xmin) * (ymax - ymin) - 10.0) # bbox的ares
# coco中的ares数值是 < w*h 的, 因为它其实是按segmentation的面积算的,所以我-10.0一下...
sig_xml_box.append(bbox)
# print('bbox', xmin, ymin, xmax - xmin, ymax - ymin, 'id', id, 'cls_id', cat_id)
images['id'] = id
# print ('sig_img_box', sig_xml_box)
return images, sig_xml_box
def txt2list(txtfile):
f = open(txtfile)
l = []
for line in f:
l.append(line[:-1])
return l
# voc2007xmls = 'anns'
voc2007xmls = 'E:/VOCdevkit/VOC2012/Annotations'
val_txt = 'E:/VOCdevkit/VOC2012/ImageSets/Main/val.txt'
xml_names = txt2list(val_txt)
xmls = []
bboxes = []
ann_js = {}
for ind, xml_name in enumerate(xml_names):
xmls.append(os.path.join(voc2007xmls, xml_name + '.xml'))
json_name = './instances_val2017.json'
images = []
for i_index, xml_file in enumerate(xmls):
image, sig_xml_bbox = getimages(xml_file, i_index)
images.append(image)
bboxes.extend(sig_xml_bbox)
ann_js['images'] = images
ann_js['categories'] = categories
annotations = []
for box_ind, box in enumerate(bboxes):
anno = {}
anno['image_id'] = box[-3]
anno['category_id'] = box[-2]
anno['bbox'] = box[:-3]
anno['id'] = box_ind
anno['area'] = box[-1]
anno['iscrowd'] = 0
annotations.append(anno)
ann_js['annotations'] = annotations
json.dump(ann_js, open(json_name, 'w'), indent=4) # indent=4 更加美观显示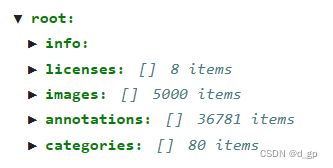 coco数据集json文件内容示例
coco数据集json文件内容示例
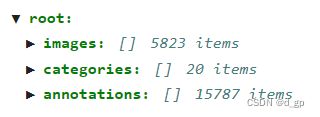 自己生成的voc数据集json文件内容示例
自己生成的voc数据集json文件内容示例
通过上述代码生成的voc数据集ison文件与原coco数据集的json文件略有不同,但没什么影响。
2. 开始训练
DETR模型代码仓库:https://github.com/facebookresearch/detr
需要修改的地方:
1) main.py文件下:

在‘--coco_path’参数中添加刚才准备好的数据集地址。
2) models文件夹下detr.py文件下:
![]()
将num_classes改为21,voc数据集共有20类物体,加上背景共21类。
3) 可根据自己电脑配置修改batch_size, num_workers, epochs等
然后就可以运行main.py文件,愉快的训练了。
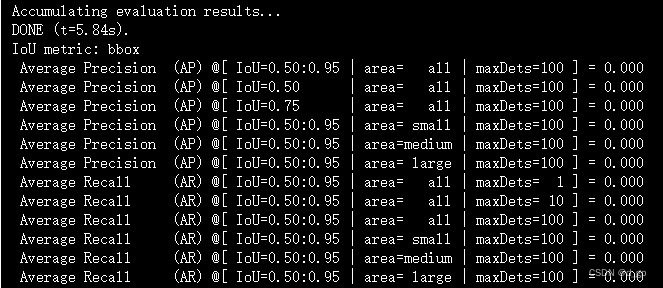
单卡3090训练了一个小时,就训练了5个epoch,各指标结果是0,是出错了还是模型收敛太慢,有待排查......
参考博客:detr训练简单记录_lingle1的博客-CSDN博客_detr训练