人工智能与机器学习课程设计
笑脸识别,口罩识别
- 一、人脸图像特征提取的各种方法(至少包括HoG、Dlib和卷积神经网络特征)
-
- 1.HOG:(方向梯度直方图)
- 2.Dlib:
- 3.卷积神经网络(CNN):
- 二、dlib安装与使用
-
- 1.conda 换源
- 2.更新conda
- 3.创建新环境python3.6,名字叫tensorflow
- 4.使用新环境
- 5.安装cmake,boost,wheel,dlib==19.6.1
- 6.安装numpy
- 7.pip 一些库
- 8.安装dlib
- 三、dlib笑脸识别
- 四、口罩识别
-
- 1.训练
- 2.测试
一、人脸图像特征提取的各种方法(至少包括HoG、Dlib和卷积神经网络特征)
1.HOG:(方向梯度直方图)
1.分割图像
overlap和non-overlap两种分割策略。overlap指的是分割出的区块(patch)互相交叠,有重合的区域。non-overlap指的是区块不交叠,没有重合的区域。
2.计算每个分割区块的方向梯度直方图
利用任意一种梯度算子,例如:sobel,laplacian等,对该patch进行卷积,计算得到每个像素点处的梯度方向和幅值。将360度(2*PI)根据需要分割成若干个bin,例如:分割成12个bin,每个bin包含30度,整个直方图包含12维,即12个bin。然后根据每个像素点的梯度方向,利用双线性内插法将其幅值累加到直方图中。
3.组合特征
将从每个patch中提取出的“小”HOG特征首尾相连,组合成一个大的一维向量,这就是最终的图像特征。可以将这个特征送到分类器中训练了。例如:有44=16个patch,每个patch提取12维的小HOG,那么最终特征的长度就是:1612=192维。
2.Dlib:
dlib中是先检测都人脸,然后把人脸通过Resnet生成一个128维的向量,Resnet有几种不同深度的结构.dlib使用的是34层的网络.
resnet34的最后一层是fc 1000,就是1000个神经元.resnet如何生成128维的向量的呢?很简单,在fc1000后面再加一个Dense(128)就行了生成向量之后再求两个向量之间的距离即可判定两个人脸的相似程度.那么如何从0开始构建一个和dlib一样的人脸识别网络呢?就是应该先构建一个resnet34,后面加一个Dense(128),后面再接分类,训练完成后舍弃最后Dense(128)接分类的那一部分,只保留前面的参数,这样每输入一张图片就可以得到一个128维的向量了.
3.卷积神经网络(CNN):
第一步:找出所有的面孔,方向梯度直方图(Histogram of Oriented Gradients)”的方法,或简称HOG。
第二步:脸部的不同姿势,将使用一种称为脸部标志点估计(Face Landmark Estimation)的算法。这一算法的基本思想是,我们找到人脸上普遍存在的68个特定点(称为Landmarks)——下巴的顶部,每只眼睛的外部轮廓,每条眉毛的内部轮廓等。接下来我们训练一个机器学习算法,能够在任何脸部找到这68个特定点。可以自己使用Python和dlib来尝试完成这一步的话,这里有一些代码帮你寻找脸部标志点和图像变形。
第三步:给脸部编码。这个通过训练卷积神经网络来输出脸部嵌入的过程,需要大量的数据和计算机应用。即使使用昂贵的Nvidia Telsa显卡,它也需要大约24小时的连续训练,才能获得良好的准确性。但一旦网络训练完成,它可以生成任何面孔的测量值,即使它从来没有见过这些面孔!所以这种训练只需一次即可。幸运的是,OpenFace上面的大神已经做完了这些,并且他们发布了几个训练过可以直接使用的网络。
第4步:从编码中找出人的名字。我们将使用一个简单的线性SVM分类器,但实际上还有很多其他的分类算法可以使用。我们需要做的是训练一个分类器,它可以从一个新的测试图像中获取测量结果,并找出最匹配的是哪个人。分类器运行一次只需要几毫秒,分类器的结果就是人的名字!
以上内容来源网络。
二、dlib安装与使用
1.conda 换源
c盘用户目录,.condarc文件:
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
show_channel_urls: yes
2.更新conda
conda update -n base -c defaults conda

3.创建新环境python3.6,名字叫tensorflow
conda create -n tensorflow python=3.6
4.使用新环境
conda activate tensorflow
5.安装cmake,boost,wheel,dlib==19.6.1
pip install cmake boost wheel dlib==19.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
6.安装numpy
pip install numpy opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
7.pip 一些库
conda install nb_conda
activate tensorflow
pip install ipykernel
python -m ipykernel install --user --name tensorflow --display-name tf
pip install keras
pip install tensorflow
pip install matplotlib
pip3 install pillow
8.安装dlib
pip install cmake
pip install boost
pip install dlib
三、dlib笑脸识别
import cv2 # 图像处理的库 OpenCv
import dlib # 人脸识别的库 dlib
import numpy as np # 数据处理的库 numpy
class face_emotion():
def __init__(self):
self.detector = dlib.get_frontal_face_detector()
self.predictor = dlib.shape_predictor("data/data_dlib/shape_predictor_68_face_landmarks.dat")
self.cap = cv2.VideoCapture(0)
self.cap.set(3, 480)
self.cnt = 0
def learning_face(self):
line_brow_x = []
line_brow_y = []
while(self.cap.isOpened()):
flag, im_rd = self.cap.read()
k = cv2.waitKey(1)
# 取灰度
img_gray = cv2.cvtColor(im_rd, cv2.COLOR_RGB2GRAY)
faces = self.detector(img_gray, 0)
font = cv2.FONT_HERSHEY_SIMPLEX
# 如果检测到人脸
if(len(faces) != 0):
# 对每个人脸都标出68个特征点
for i in range(len(faces)):
for k, d in enumerate(faces):
cv2.rectangle(im_rd, (d.left(), d.top()), (d.right(), d.bottom()), (0,0,255))
self.face_width = d.right() - d.left()
shape = self.predictor(im_rd, d)
mouth_width = (shape.part(54).x - shape.part(48).x) / self.face_width
mouth_height = (shape.part(66).y - shape.part(62).y) / self.face_width
brow_sum = 0
frown_sum = 0
for j in range(17, 21):
brow_sum += (shape.part(j).y - d.top()) + (shape.part(j + 5).y - d.top())
frown_sum += shape.part(j + 5).x - shape.part(j).x
line_brow_x.append(shape.part(j).x)
line_brow_y.append(shape.part(j).y)
tempx = np.array(line_brow_x)
tempy = np.array(line_brow_y)
z1 = np.polyfit(tempx, tempy, 1)
self.brow_k = -round(z1[0], 3)
brow_height = (brow_sum / 10) / self.face_width # 眉毛高度占比
brow_width = (frown_sum / 5) / self.face_width # 眉毛距离占比
eye_sum = (shape.part(41).y - shape.part(37).y + shape.part(40).y - shape.part(38).y +
shape.part(47).y - shape.part(43).y + shape.part(46).y - shape.part(44).y)
eye_hight = (eye_sum / 4) / self.face_width
if round(mouth_height >= 0.03) and eye_hight<0.56:
cv2.putText(im_rd, "smile", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 2,
(0,255,0), 2, 4)
if round(mouth_height<0.03) and self.brow_k>-0.3:
cv2.putText(im_rd, "unsmile", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 2,
(0,255,0), 2, 4)
cv2.putText(im_rd, "Face-" + str(len(faces)), (20,50), font, 0.6, (0,0,255), 1, cv2.LINE_AA)
else:
cv2.putText(im_rd, "No Face", (20,50), font, 0.6, (0,0,255), 1, cv2.LINE_AA)
im_rd = cv2.putText(im_rd, "S: screenshot", (20,450), font, 0.6, (255,0,255), 1, cv2.LINE_AA)
im_rd = cv2.putText(im_rd, "Q: quit", (20,470), font, 0.6, (255,0,255), 1, cv2.LINE_AA)
if (cv2.waitKey(1) & 0xFF) == ord('s'):
self.cnt += 1
cv2.imwrite("screenshoot" + str(self.cnt) + ".jpg", im_rd)
# 按下 q 键退出
if (cv2.waitKey(1)) == ord('q'):
break
# 窗口显示
cv2.imshow("Face Recognition", im_rd)
self.cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
my_face = face_emotion()
my_face.learning_face()
四、口罩识别
1.训练
import keras
import os, shutil
train_smile_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\train\\smile\\"
train_umsmile_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\train\\unsmile\\"
test_smile_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\test\\smile\\"
test_umsmile_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\test\\unsmile\\"
validation_smile_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\validation\\smile\\"
validation_unsmile_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\validation\\unsmile\\"
train_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\train\\"
test_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\test\\"
validation_dir="F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\validation\\"
from keras import optimizers
from keras import layers
from keras import models
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
import os
import matplotlib.pyplot as plt
from PIL import Image
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
#归一化处理
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=6,
epochs=60,
validation_data=validation_generator,
validation_steps=50)
model.save('F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\smileAndUnsmile.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
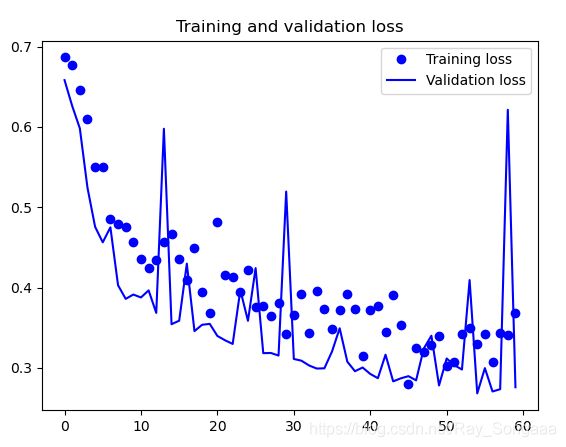
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
2.测试
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
#加载模型
model = load_model('F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\smileAndUnsmile.h5')
#本地图片路径
def pic(img_path):
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='非笑脸'
else:
result='笑脸'
print(result)
a=[]
a.append(r'F:\\BaiduNetdiskDownload\\aidazuoye\\smile2\\data\\test\smile\\file1115.jpg')
a.append(r"F:\BaiduNetdiskDownload\aidazuoye\smile2\data\test\smile\file1120.jpg")
a.append(r'F:\\BaiduNetdiskDownload\\aidazuoye\smile2\\data\\test\unsmile\\file2205.jpg')
a.append(r"F:\BaiduNetdiskDownload\aidazuoye\smile2\data\test\unsmile\file2183.jpg")
for url in a:
pic(url)
参考链接:https://blog.csdn.net/qq_34591921/article/details/107132144