【多尺度混合卷积】Transformer模型ConvMAE开源:进一步挖掘和提升 MAE 的性能
作者 || 科技猛兽
转载 || 极市平台
编辑 || 3D视觉开发者社区
✨如果觉得文章内容不错,别忘了三连支持下哦~
导读
多尺度的金字塔式架构 + 局部的归纳偏置的模型,能不能经过 MAE 的训练方式之后,进一步挖掘和提升 MAE的性能?本文就是探索这个问题。
ConvMAE,简而言之就是:多尺度的金字塔式架构 + 局部的归纳偏置的模型,使用 MAE 的Self-supervised Learning 的训练方式。
文章目录
- ConvMAE:混合卷积-Transformer 模型实现更高效的 MAE
-
- 1 Self-supervised Learning
- 2 ConvMAE的动机
- 3 ConvMAE Encoder 架构
- 4 ConvMAE mask 策略
- 5 ConvMAE Decoder 架构
- 6 ConvMAE 下游任务
- 7 ConvMAE 实验结果
- 8 ConvMAE 消融实验
- 总结
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks) 。
其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。
ConvMAE:混合卷积-Transformer 模型实现更高效的 MAE
论文名称:ConvMAE: Masked Convolution Meets Masked Autoencoders
论文地址:https://arxiv.org/pdf/2205.03892.pdf
本文论点是多尺度的混合 Convolution-Transformer 模型,可以助力 Masked Auto-Encoding (MAE) 的训练范式,帮助其学习到更好的表征。
1 Self-supervised Learning
在预训练阶段我们使用无标签的数据集 (unlabeled data),因为有标签的数据集很贵,打标签得要多少人工劳力去标注,那成本是相当高的,太贵。
相反,无标签的数据集网上随便到处爬,它便宜。在训练模型参数的时候,我们不追求把这个参数用带标签数据从初始化的一张白纸给一步训练到位,原因就是数据集太贵。
于是,Self-Supervised Learning 就想先把参数从一张白纸训练到初步成型,再从初步成型训练到完全成型,注意这是2个阶段。
这个训练到初步成型的东西,我们把它叫做 Visual Representation。预训练模型的时候,就是模型参数从一张白纸到初步成型的这个过程,还是用无标签数据集。
等我把模型参数训练个八九不离十,这时候再根据你下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到完全成型,那这时用的数据集量就不用太多了,因为参数经过第1阶段,就已经训练得差不多了。
第一个阶段不涉及任何下游任务,就是拿着一堆无标签的数据去预训练,没有特定的任务,这个话用官方语言表达叫做:in a task-agnostic way。第二个阶段涉及下游任务,就是拿着一堆带标签的数据去在下游任务上 Fine-tune,这个话用官方语言表达叫做:in a task-specific way。
以上这些话就是 Self-Supervised Learning 的核心思想,如下图1所示,后面还会再次提到它。
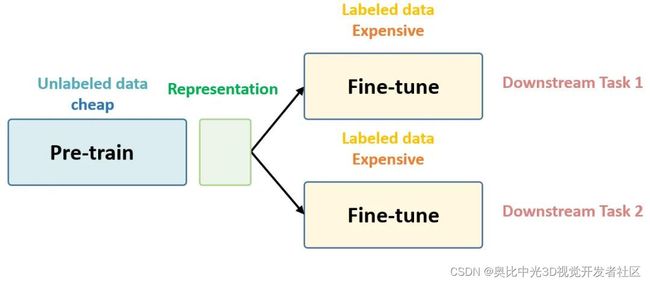 图1:Self-Supervised Learning 的核心思想
图1:Self-Supervised Learning 的核心思想
Self-Supervised Learning 不仅是在NLP领域,在CV, 语音领域也有很多经典的工作,如下图2所示。它可以分成3类:Data Centric, Prediction (也叫 Generative) 和 Contrastive。
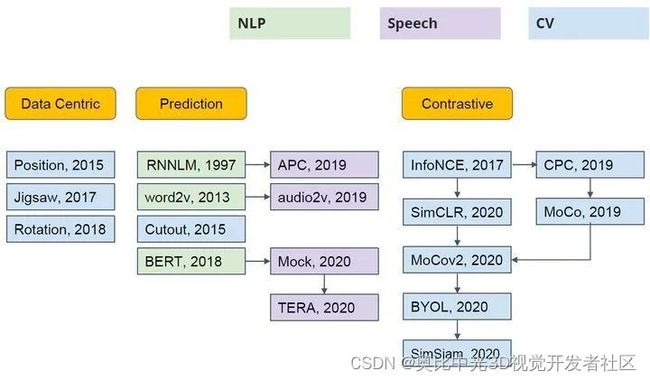 图2:各个领域的 Self-Supervised Learning (引用李宏毅老师 PPT)
图2:各个领域的 Self-Supervised Learning (引用李宏毅老师 PPT)
其中的主流,就是基于 Generative 的方法和基于 Contrative 的方法,如下图 3 所示,这里简单介绍下。
基于 Generative 的方法主要关注的重建误差,比如对于 NLP 任务而言,一个句子中间盖住一个 token,让模型去预测,令得到的预测结果与真实的 token 之间的误差作为损失。
基于 Contrastive 的方法不要求模型能够重建原始输入,而是希望模型能够在特征空间上对不同的输入进行分辨。
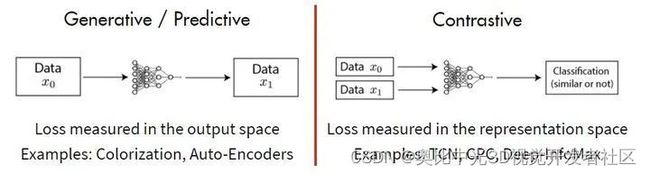
图3:基于 generative 的方法和基于 contrastive 的方法的总结图片 (引用李宏毅老师 PPT)
2 ConvMAE的动机
ConvMAE 这个方法所基于的论点是:
- 目前已经有许多工作 (如 MoCo[1],MAE[2],BEiT[3],DINO[4]) 验证了 MAE Self-Supervised Learning 的训练范式能够帮助释放 Vision Transformer 模型的潜力,并且在下有任务上取得非常好的性能。
MAE 作为这个范式的代表作,开发了一个非对称编码器 - 解码器架构,其中编码器只对可见的 patch 子集进行操作 (即没有被 mask 掉的 token),另一个非对称的解码器可以从潜在表征和被 masked 掉的 token重建原始图像。Decoder 的架构可以是十分轻量化的模型,且具体的架构对模型性能影响很大。研究人员进一步发现,Mask 掉大部分输入图像 (例如 75%) 会产生重要且有意义的自监督任务。
同时 MAE 这种训练的范式不但能够在不需要超大规模数据集 (JFT-300M,ImageNet-22K) 的情况下,学习到判别性能很强 (Discriminative) 的表征,而且可以轻松的扩展 (Scalable) 到更大的模型上,并且通过实验发现随着模型增大,效果越来越好。
- 为了加速 ViT 训练并得到更好的性能,大量工作验证了局部的归纳偏置 (local inductive bias) (如 SMCA-DETR [5],SAM-DETR[6],DAB-DETR[7],Uniformer[8],CoAtNet[9],ConViT[10],Early Convolution[11]) 和可以进一步帮助提升 ViT 模型的性能。同时,这种性能的提升也可以通过多尺度的金字塔式架构 (multi-scale hierarchical representation) (如 Swin Transformer[12],PVT[13]) 来实现。二者结合的有效性已经在大量的识别,检测,分割的监督学习任务中得到的验证。
所以一个自然而然的问题是:这种多尺度的金字塔式架构 + 局部的归纳偏置的模型,能不能经过 MAE 的训练方式之后,进一步挖掘和提升 MAE 的性能?
本文就是探索这个问题。ConvMAE 简而言之就是:多尺度的金字塔式架构 + 局部的归纳偏置的模型,使用 MAE 的 Self-supervised Learning 的训练方式。
与 MAE-Base 相比,ConvMAE-Base 将 ImageNet-1k 的微调精度提高到 85.0% (+1.4%),将 Mask-RCNN COCO 检测任务的 AP box 提高到 53.2% (+2.9%),将 UperNet 的 ADE20k 分割任务的 mIoU 提高到 51.7% (+3.6%)。
3 ConvMAE Encoder 架构
MAE 的做法如下图4所示。MAE 是一种以自监督的方式,以 ViT 为模型架构进行预训练的框架。MAE 的方法很简单:Mask 掉输入图像的随机的 patches 并重建它们。它基于两个核心理念:研究人员开发了一个非对称编码器 - 解码器架构,其中一个编码器只对可见的 patch 子集进行操作 (即没有被 mask 掉的 token),另一个简单解码器可以从可学习的潜在表征和被 masked 掉的 token重建原始图像。
Decoder 的架构可以是十分轻量化的模型,且具体的架构对模型性能影响很大。研究人员进一步发现,Mask 掉大部分输入图像 (例如 75%) 会产生重要且有意义的自监督任务。结合这两种设计就能高效地训练大型模型:提升训练速度至 3 倍或更多,并提高准确性。
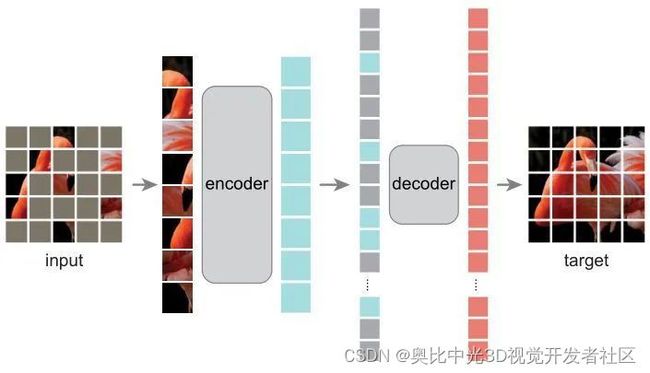 图4:MAE 框架
图4:MAE 框架
ConvMAE 相比于 MAE 框架做了一些微小却非常有效的改进,如前文所述它的特点是:多尺度的金字塔式架构 + 局部的归纳偏置的模型。
如下图5所示是 ConvMAE 框架,它也有一个 Encoder 和 Decoder。Encoder 是 convolution-transformer 混合架构,Decoder 是纯 transformer 架构。
先看左上角灰色的 Encoder 部分。它包括了3个 stage,设 H H H和 W W W是输入图片的尺寸,每个 stage 输出的特征分别是
前两个 stage 是卷积模块,使用 Masked Convolutional Block 对特征进行操作,其结构如下图右下角所示 (其中的 Depthwise Convolution 使用5×5大小卷积核)。在每个阶段之间,进行一次 stride 为2的卷积以进行下采样操作。最后一个 stage 都是 Transformer 模块,拉大感受野,并融合所有 patch 的特征。另外,作者发现绝对位置编码性能是最优的。
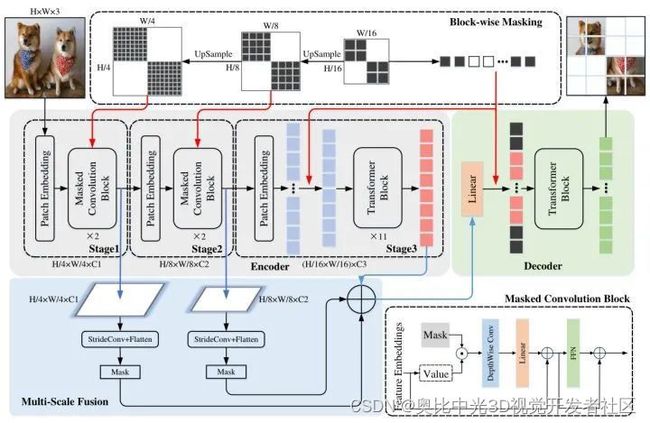
图5:ConvMAE 框架
4 ConvMAE mask 策略
MAE 对输入图片的 patch 采用随机 mask 策略,然而,同样的策略不能直接应用于 ConvMAE 的编码器。因为 ConvMAE 的特征是不同 stage 是逐渐下采样的,如果在  的特征这里进行了随机的 mask,就会导致 stage3 阶段的每个 tokens 都有一部分的可见信息。因此 ConvMAE 作者的做法是 mask 掉 stage3 p p p%的输出 (比如 75%) 之后,把这些 mask 分别上采样2倍和4倍得到前两个阶段的 mask。这些被 mask 掉的 token 在编码阶段被丢弃,并且希望经过 Decoder 之后能够重建出来。通过这种方式,ConvMAE 只需要保留至少 25% 的 token 用于训练。
的特征这里进行了随机的 mask,就会导致 stage3 阶段的每个 tokens 都有一部分的可见信息。因此 ConvMAE 作者的做法是 mask 掉 stage3 p p p%的输出 (比如 75%) 之后,把这些 mask 分别上采样2倍和4倍得到前两个阶段的 mask。这些被 mask 掉的 token 在编码阶段被丢弃,并且希望经过 Decoder 之后能够重建出来。通过这种方式,ConvMAE 只需要保留至少 25% 的 token 用于训练。
但是前两个阶段使用 5×5 的 Depthwise Convolution 的感受野可能大于一个 masked patch 的大小,因此作者为了确保预训练的质量,在前两个阶段采用了 masked convolution1 2,确保被 mask 掉的部分不会参与到编码的过程。
5 ConvMAE Decoder 架构
如图4所示,原始 MAE 的 Decoder 以 Encoder 的输出以及 masked token 为输入,通过一系列的 Transformer Block 得到最终的重建结果。
ConvMAE 的编码器获得了多尺度特征 E 1 , E 2 , E 3 E_1,E_2,E_3 E1,E2,E3,分别捕捉到了细粒度和粗粒度的图像信息。为了更好地进行预训练,作者将 E 1 E_1 E1和 E 2 E_2 E2分别进行 stride=2 和 stride=4 的下采样之后与 E 3 E_3 E3相加,进行多尺度特征的融合。融合得到的结果再通过 Linear Transformation 得到最终要输入给 Decoder 的 token。
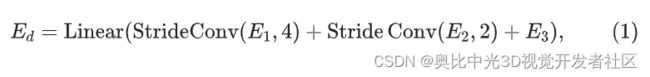
式中,  代表 stride=k 的卷积。
代表 stride=k 的卷积。
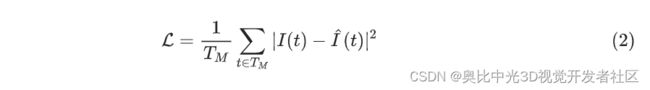
训练使用的目标函数与 MAE 保持一致,都是 mask 的部分的重建结果与原图的 L1 Loss。
式中, T M T_M TM代表 masked tokens 的集合。
6 ConvMAE 下游任务
ConvMAE 经过预训练之后,Encoder 能够输出多尺度的特征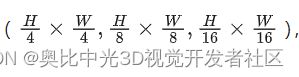 ,它们可以被用于后续的检测分割任务里面。
,它们可以被用于后续的检测分割任务里面。
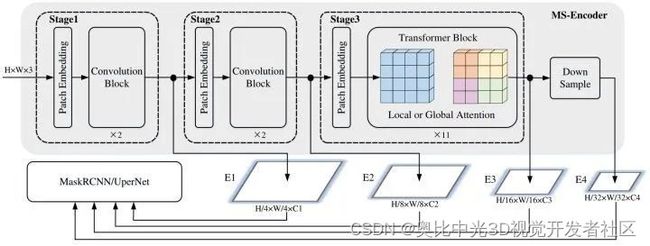
图6:ConvMAE 用于检测和分割的框架,输出的不同尺度的中间特征传入 FPN 模块
ConvMAE 用于检测任务的微调过程:先把 Encoder 的输出特征 E 3 E_3 E3进行 max-pooling 操作得到 E 4 E_4 E4。对于检测任务,因为 ConvMAE 的 stage3 有11个全局 Self-attention 层,计算成本过高,所以作者把 stage3 里面第1,4,7,11个 Self-attention 换成了 7×7 Window size 的 Swin Attention 层。通过这样的做法减少了计算量和 GPU 占用。最终得到的 E 1 , E 2 , E 3 , E 4 E_1,E_2,E_3,E_4 E1,E2,E3,E4被送入 Mask R-CNN 或者 UperNet 进行目标检测或者语义分割任务。对于分割任务,Stage3 的架构不变。
7 ConvMAE 实验结果
图像分类实验结果
作者首先使用 ImageNet 训练 ConvMAE 框架,mask 掉25%的 input token 进行训练,Decoder 的具体架构是一个8层的 Transformer,hidden dimension 是512,head 数是12。一共预训练1600 Epoch,使用 cosine 的学习率衰减策略以及40 Epoch 的学习率 warm up。使用 AdamW 作为优化器,使用1.5e-4的初始学习率,0.05的 weight decay,batch size 设置为1024。
预训练时使用 Random cropping 作为数据增强策略,预训练之后,使用 ImageNet-1K 进行监督学习100个 Epoch,依然使用 cosine 的学习率衰减策略。结果如下图6所示。
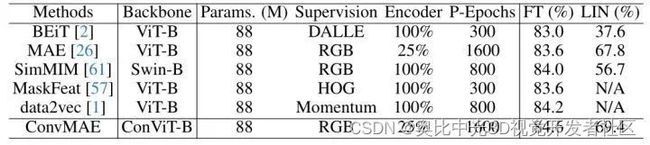
图7:ImageNet 实验结果
通过 300 Epoch 的预训练,BEiT 可以达到83.0%的 Finetuning Accuracy 以及 37.6% 的 Linear Probe Accuracy。与 BEiT 相比,ConvMAE 只使用了25%的图像和一个更加轻量化的 Decoder,可以达到89.6%的 Finetuning Accuracy 以及 69.4% 的 Linear Probe Accuracy。
目标检测实验结果
作者进一步将预训练好的 ConvMAE 替换 Mask R-CNN 的 Backbone 用于 COCO 数据集的目标检测任务中。初始学习率设为8e-5,weight decay 为0.1,训练25 Epoch,Batch size 设置为32。实验结果如下图8所示。图7比较了 Mask R-CNN 框架几种不同的 Backbone 的性能。Benchmarking ViT [16]在 COCO 数据集上面 Finetuning 了 100 Epoch,但是 ConvMAE 在只 Finetuning 了 25 Epoch 的前提下使得 AP box 和 AP mask 分别提升了2.2%和1.6%。ConvMAE 在 AP box 和 AP mask 上超过了 Swin 和 MViTv2 3.3%/3%和1.5%/0.7%。
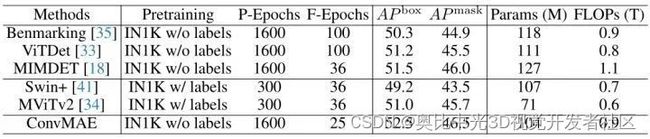
图8:目标检测实验结果
语义分割实验结果
作者进一步将预训练好的 ConvMAE 替换 UperNet 的 Backbone 用于 COCO 数据集的目标检测任务中。使用的 Backbone 是在 ImageNet-1K 上预训练了 1600 Epoch 的 ConvMAE 的 Backbone,学习率衰减策略使用 16k-iteration polynomial learning rate schedule,前 1500 iteration 学习率 warm up。
使用 AdamW 作为优化器,使用1e-4的初始学习率,0.05的 weight decay,batch size 设置为16。如下图所示比较了 UperNet 框架几种不同的 Backbone 的性能,使用了1600 Epoch 预训练的 ConvMAE 达到了50.7的 mIoU,得到了最佳的性能。与预训练1600 Epoch 的 MAE 相比,ConvMAE 高出2.6% 的 mIoU,表明 ConvMAE 的多尺度特征大大缩小了预训练 Backbone 和下游网络之间的传输差距。
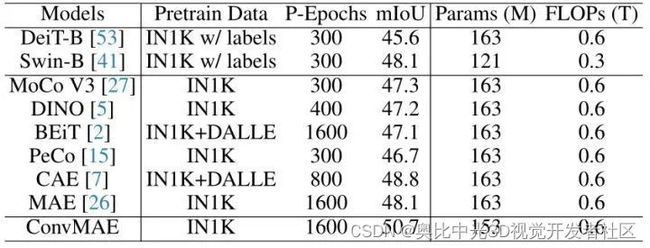
图9:语义分割实验结果
8 ConvMAE 消融实验
为了验证本文所提出方法的有效性,作者又进行了几组消融实验。
预训练 Epoch 数的影响
对于 MAE 而言,更长的预训练 Epoch 数可以显著提升模型的表征能力。作者对 ConvMAE-Base 进行预训练了200、400、800和1600个 Epoch ,以测试对 ConvMAE 的影响。结果如下图10所示,可以看到随着预训练 Epoch 数的增加,分类任务的 Finetuning Accuracy 以及 Linear Probe Accuracy 都在不断上升,同时 COCO 检测任务和 ADE20K 分割任务性能也在不断提升,证明了预训练 Epoch 数对于模型的性能有积极影响。
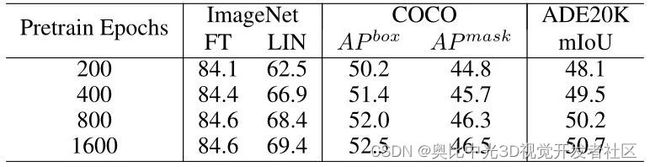 图10:预训练 Epoch 数的影响
图10:预训练 Epoch 数的影响
Mask 方式以及卷积核大小的影响
如下图11所示,作者把 block-wise 的 mask 策略换回到 MAE 中的 random mask 策略,发现 ImageNet 性能从84.6%降到了84.2%,证明了 block-wise 的 mask 策略的有效性。把卷积核大小从5×5增加到7×7或者9×9几乎不会影响 ConvMAE 在 ImageNet-1K 的精度。
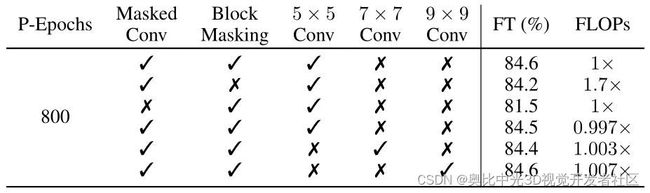
图11:Mask 方式以及卷积核大小的影响
多尺度 Decoder 特征融合的影响
如下图12所示,作者在训练 200 Epoch 和 1600 Epoch 这两种情况下测试了多尺度 Decoder 对于 Conv MAE 性能的影响,在预训练 200 Epoch 的情况下,ImageNet 分类性能,AP box,AP mask 和 mIoU 在用了多尺度 Decoder 之后分别提升了 0.3%, 0.6%, 0.6% 和 0.4%;在预训练 1600 Epoch 的情况下,分别提升了 0.4%, 0.7%, 0.6% 和 1.0%。这意味着融合多尺度特征进行 mask reconstruction 更容易得到好的图像表征。

图12:多尺度 Decoder 的影响
总结
ConvMAE 是基于 MAE 的一种自监督式学习框架,ConvMAE 希望通过把模型架构设置为多尺度的金字塔式架构,以及对于编码器使用 convolution+transformer 结合的模型,经过 MAE 的训练方式之后,进一步挖掘和提升 MAE 的性能。因为先前的工作已经证明了这二者对于学习图像表征能力的帮助。ConvMAE 的 block-wise 的掩码方式和多尺度的 Decoder 特征融合也能够更好地辅助自监督训练。实验验证了 ConvMAE 对于图像分类任务,目标检测和语义分割任务的有效性,也在各种任务上提高了收敛速度。
参考
1:An empirical study of training self-supervised vision transformers
2:Masked autoencoders are scalable vision learners
3:Beit: Bert pre-training of image transformers
4:Emerging properties in self-supervised vision transformer
5:Fast convergence of detr with spatially modulated co-attention
6:Accelerating detr convergence via semantic-aligned matching
7:Dab-detr: Dynamic anchor boxes are better queries for detr
8:Uniformer: Unifying convolution and self-attention for visual recognition
9:Coatnet: Marrying convolution and attention for all data sizes
10:Convit: Improving vision transformers with soft convolutional inductive biases
11:Early convolutions help transformers see better
12:Swin transformer: Hierarchical vision transformer using shifted windows
13:Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
14:Benchmarking detection transfer learning with vision transformers
版权声明:本文为奥比中光3D视觉开发者社区授权转载发布,仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
也可以移步微信关注官方公众号 3D视觉开发者社区 ,获取更多干货知识哦~
Submanifold sparse convolutional networks ↩︎
Sbnet: Sparse blocks network for fast inference ↩︎