tensorflow2实现手写数字识别
GPU的设置
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
导入数据集并且显示
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
import cv2
import numpy as np
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
print('训练集',train_images.shape)
##图片的显示
#数据可视化
num = 40
col = 8
row = int(num / 8)
index = np.random.randint(1, len(train_images), num)
for i in range(num):
for j in range(8):
# plt.figure()
plt.subplot(row, col, i + 1)
plt.xticks([]) # 去掉x轴的刻度
plt.yticks([]) # 去掉y轴的刻度
image=train_images[index[i]]
image=cv2.resize(image,(48,48))
plt.imshow(image, cmap='gray')
plt.show()
归一化
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
- 加快学习算法的收敛速度。
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0搭建模型
model = models.Sequential([
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 打印网络结构
model.summary()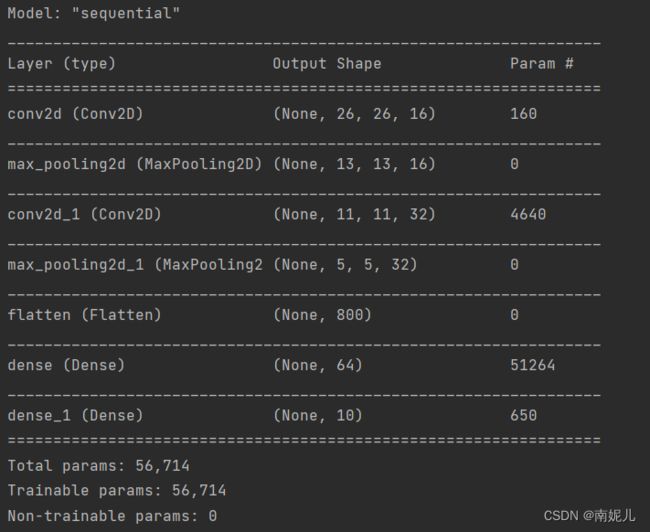
编译模型
# model.compile() 优化器、损失函数和准确率评测标准
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])模型的训练
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
import cv2
import numpy as np
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
print('训练集',train_images.shape)
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
model = models.Sequential([
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 打印网络结构
model.summary()
# model.compile() 优化器、损失函数和准确率评测标准
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
history = model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels))
model.save('model.h5')
 绘制损失函数曲线
绘制损失函数曲线
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
import cv2
import numpy as np
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
print('训练集',train_images.shape)
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
model = models.Sequential([
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 打印网络结构
model.summary()
# model.compile() 优化器、损失函数和准确率评测标准
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
history = model.fit(train_images, train_labels, epochs=50, validation_data=(test_images, test_labels))
print(history)
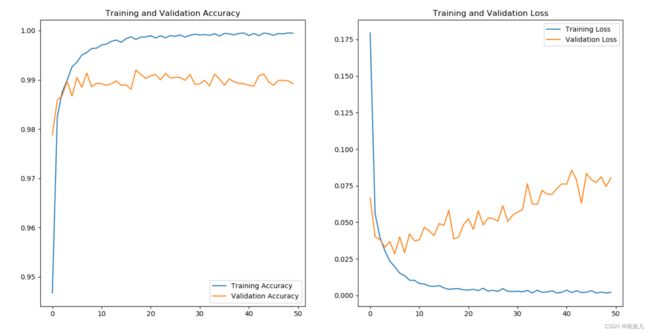
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
model.save('model.h5')

模型的评估
错误的示范
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
import cv2
import numpy as np
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
print('训练集',train_images.shape)
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
model = tf.keras.models.load_model(r'./model.h5')
loss,accuracy = model.evaluate(test_images,test_labels,verbose=1)
print('误差',loss)
print('准确率',accuracy)

跑了很多次,才发现这个在定义模型的时候必须经过编译。
正确的版本
import tensorflow as tf
from tensorflow.keras import datasets
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
print('训练集',train_images.shape)
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
model = tf.keras.models.load_model(r'./model.h5')
##这里必须经过编译,指出评价指标
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
loss,accuracy = model.evaluate(test_images,test_labels,verbose=2)
print('误差',loss)
print('准确率',accuracy) 
模型的预测
import tensorflow as tf
from tensorflow.keras import datasets
import matplotlib.pyplot as plt
import numpy as np
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
print('训练集',train_images.shape)
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
model = tf.keras.models.load_model(r'./model.h5')
# loss,accuracy = model.evaluate(test_images,test_labels,verbose=1)
# model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
# print('误差',loss)
# print('准确率',accuracy)
y_pred=model.predict(test_images,batch_size=1)
print('预测概率',y_pred[0])
# hh=np.argsort(y_pred[0])
# print('预测结果',hh[-1])
print('预测结果',y_pred[0].argmax())
image=test_images[0].reshape(28,28)
image=image*255.0
image=np.clip(image,0,255).astype('uint32')
plt.imshow(image)
plt.show()
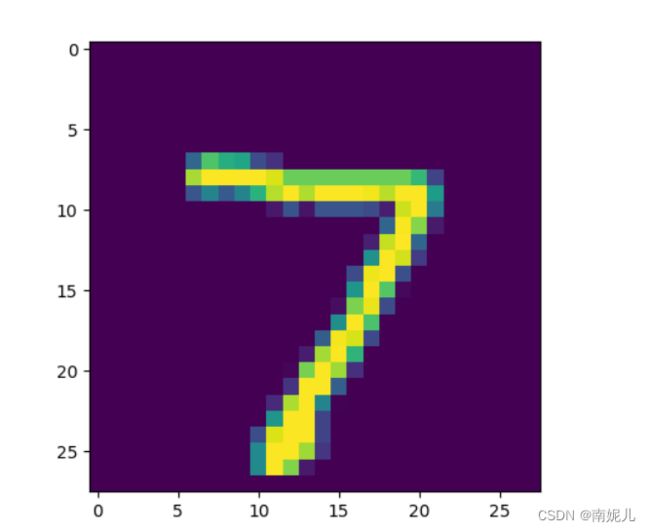
可以看到概率之和不为1,下次记得加入sigmoid激活函数。
混淆矩阵
import tensorflow as tf
from tensorflow.keras import datasets
import matplotlib.pyplot as plt
import numpy as np
import itertools
from sklearn.metrics import confusion_matrix
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
print('训练集',train_images.shape)
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
model = tf.keras.models.load_model(r'./model.h5')
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
loss,accuracy = model.evaluate(test_images,test_labels,verbose=1)
print('误差',loss)
print('准确率',accuracy)
# y_pred=model.predict(test_images,batch_size=1)
# print('预测概率',y_pred[0])
# hh=np.argsort(y_pred[0])
# print('预测结果',hh[-1])
# image=test_images[0].reshape(28,28)
# image=image*255.0
# image=np.clip(image,0,255).astype('uint32')
# plt.imshow(image)
# plt.show()
#参数 y_true为测试数据集的真实标签,y_pred为网络对测试数据集的预测结果
def plot_confusion_matrix(y_true, y_pred, title = "Confusion matrix",
cmap = plt.cm.Blues, save_flg = False):
classes = [str(i) for i in range(10)]#参数i的取值范围根据你自己数据集的划分类别来修改,我这儿为7代表数据集共有7类
labels = range(10)#数据集的标签类别,跟上面I对应
cm = confusion_matrix(y_true, y_pred, labels=labels)
plt.figure(figsize=(14, 12))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title, fontsize=40)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, fontsize=20)
plt.yticks(tick_marks, classes, fontsize=20)
print('Confusion matrix, without normalization')
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label', fontsize=30)
plt.xlabel('Predicted label', fontsize=30)
if save_flg:
plt.savefig("./confusion_matrix.png")
plt.show()
y_pred=model.predict(test_images,batch_size=1)
# hh=[]
# for i in y_pred:
# i=np.argsort(i)[-1]
# hh.append(i)
y_pred=np.argsort(y_pred,axis=1)[:,-1]
plot_confusion_matrix(test_labels,y_pred,save_flg=True) 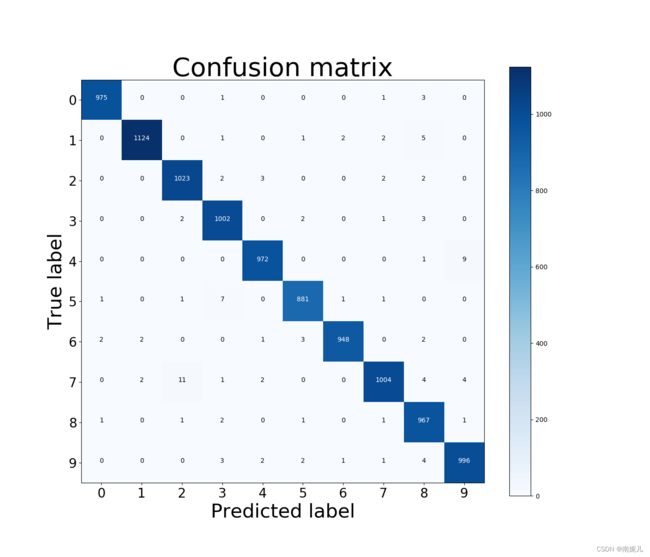
参考文献
tensorflow2.0自制神经网络数据集及预测结果(混淆矩阵)可视化_为人名日益增长的美好生活需要读书的博客-CSDN博客_tensorflow2.0 在cnn上 绘制 混淆矩阵
tensorflow实现手写数字识别_非著名奶茶爱好者的博客-CSDN博客_tensorflow手写体数字识别
Tensorflow2.0对不平衡数据的分类(含混淆矩阵与ROC图)_cofisher的博客-CSDN博客