【目标检测 Object Detection】从YOLO v1 到 YOLO v3 算法总结
文章目录
-
- 0. 前言
- 1. YOLO v1
-
- 1.1 整体算法
- 1.2 特点
- 1.3 总结
- 2. YOLO v2
-
- 2.1 整体算法
- 2.2 特点
- 2.3 总结
- 3. YOLO v3
-
- 3.1 整体算法
- 3.2 特点
- 3.3 总结
0. 前言
YOLO系列算法是目标检测领域中单阶段算法的经典/代表之作,同时具备了较高的速度和不错的精度,因此在很多边缘计算、实时性要求较高的任务中备受青睐。因此此文的主要目的是在阅读现有优秀博客和视频讲解的基础上,对YOLO系列算法进行总结及思考,一个方便自己以后查阅,其次也可以给大家提供一些参考。
本系列主要包括以
Joseph Redmon为第一作者的YOLOv1~v3系列,剩下的v4以及vx后续会以单独的文章呈现。
1. YOLO v1
YOLO v1发布于CVPR 2016,作者团队包括了Joseph Redmon和Ross Girshick等大佬,其精度虽然没有Faster RCNN和同年的SSD高,但是v1思路简单、清晰,是目标检测入门必读论文之一。
本节内容参考了优质博客和讲解视频,参考链接如下:
[1] 知乎yolo v1解读
[2] bilibili视频讲解
1.1 整体算法
yolo v1把目标检测问题完全视为一个端到端的回归问题,如下图所示,输入图像只通过单个网络就可以直接得到预测框,再执行NMS去除多余的框,就能得到最终结果。

算法流程:输入一幅图像,得到维度为SxSx(Bx5+C)的特征图,其中SxS表示将图像分为sxs个网格(grid cell),B为预测框的个数,C为物体类别数。其中5表示每个预测框的(x, y, w, h, conf)【中心坐标、长、宽和置信度】。
例如,在
PASCAL VOC 07数据集上,S=7,B=2,C=20,输入448x448的图像后得到7x7x30的输出。网络结构可参照原文,由24个卷积层 + 2个全连接层构成,backbone事先在ImageNet数据集上以224x224进行了预训练。
损失函数: 采用误差平方和作为损失函数,主要分为三部分:
- 对于选中预测框的中心坐标
(x,y)直接与gt计算loss,而为了减少大目标和小目标之间尺度差异导致得loss不对等,对于w,h采开根号。例如,20个像素点的偏差,对于800x600的预测框几乎没有影响,此时的IOU数值还是很大,但是对于30x40的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异; - 对于选中预测框的置信度
Ci,采用GT与预测框的iou作为目标 C i ^ \hat{C_i} Ci^,而不包含物体中心的网格输出置信度则以0为目标; - 对于类别损失,也只是针对包含目标中心的网格计算损失。
其中, 1 i o b j 1_{i}^{obj} 1iobj表示对应的
grid cell包含了物体中心时才为1,否则为0; 1 i j o b j 1_{ij}^{obj} 1ijobj表示只有对应的grid cell即包含了物体中心,置信度又为B个预测中最大时才为1,否则为0;两个 λ \lambda λ用于加权损失和前背景不平衡的问题。

一些细节:① 每个grid cell只会得到一个类别的一种检测结果;② (x,y)为grid cell的相对坐标,而(w,h)为绝对坐标;③ 测试时,由下式计算得到每个预测框的置信度【类别概率 * 预测框和GT之间的IoU】;
![]()
1.2 特点
- 速度快:这也是其最大的优点,在titan x GPU上,在保证检测准确率的前提下(63.4% mAP,VOC 2007 test set),可以达到45fps的检测速度。
- 误检率低:相较于两阶段的算法,v1在进行类别预测时会考虑到整幅图像上下文信息,而不只是某个局部区域。
误检:将背景预测为某个物体类
- 通用性较强:作者在其他域的数据(艺术品 / 绘画作品)上进行实验,其精度要远高于DPM和RCNN等模型。

- 召回率低、定位精度低、尺度敏感、:由于每个
grid cell只预测某个类别的一个预测框(置信度最大的那个),这很容易导致漏检。由于网络直接预测回归框的(x, y, w, h),因此定位精度低,并且对尺度的泛化能力较弱。
1.3 总结
yolo v1是单阶段目标检测算法的典型代表,并且没有涉及到anchor的概念,因此也是anchor-free的算法。其思想简单,完全把目标检测问题视为一个端到端的回归问题,速度快,并且精度还不低。但其精度较低,并且框架存在一个明显缺陷:每个grid cell只能预测一个目标,这会导致如果检测场景中出现大量密集的小物体,就会存在大量漏检。
2. YOLO v2
YOLO v2发表于CVPR 2017,一作仍是Joseph Redmon。论文全名为《YOLO9000: Better, Faster, Stronger》,为什么叫YOLO 9000呢,因为这篇论文的最大亮点并不是基于v1的改进,而是探索了级联学习分类数据集+检测数据集,从而扩展YOLO检测器的检测能力(检测超过9000个类且保持实时,效果并没有太好)。但是其对于模型和训练流程的改进和探索,融合了当时的先进技术,并针对YOLO本身进行特定的改进,这是非常值得我们开发者去学习的。
本节内容参考资料:
[1] https://blog.csdn.net/u014380165/article/details/77961414
[2] https://zhuanlan.zhihu.com/p/74540100
2.1 整体算法
v2主要从三个方面进行探索与改进,如论文题目所示:Better(检测精度),Faster(检测速度),Stronger(级联训练)。
better: 相比于Fast RCNN等算法,YOLO v1的主要误差在于定位不准确,导致召回率低,因此作者探索了很多方法来改善这个问题。
- 引入BatchNorm:在每个卷积层之后增加
batch norm层,提高性能以及正则化模型(可以移除dropout); - 高分辨率预训练:v1的backbone以
224x224分辨率在ImageNet上进行模型预训练,而检测时直接输入448x448大小的图片。v2在预训练是,最后10epoch提升分辨率对模型进行fine-tune。 - anchor box和全卷积网络:不像Faster RCNN预测目标相对于预设框(
anchor box)的偏移,YOLO v1是直接预测检测框的坐标,但预测相对位置会使得网络的学习变得更容易。所以v2引入了anchor机制,并且将位置预测和类别预测解耦,每个点不止预测一个类,而是让网络预测每个anchor box的类别。置信度的预测方式仍和v1一样,为iou。使用anchor box之后,虽然整体mAP小幅下降,但召回率得到了大幅提升,这也提升了模型的改进空间。此外,作者在v2移除了网络的全连接层【变为全卷积网络】,并将网络输入改为了416x416的输入尺寸,并消除了一个池化层,最终得到13x13的输出。 - 聚类生成anchor预设尺寸 / 维度聚类:faster rcnn在RPN阶段会人为指定候选框的尺寸(三种不同面积+三种长宽比
1:1,1:2,2:1共9个框),依靠网络去对这些框进行调整,但这没有考虑到数据特点,如果一开始就能选择到合适尺寸的anchor box,就可以帮助网络越好地学习。因此YOLO v2采用K-Means对训练集的标签进行聚类,同样为了避免大的box产生的误差值更大导致优化方向偏向大box,忽略小box,作者不采用欧式距离作为度量函数,而是自定义了一个函数,用iou差值来表示box与中心的距离:
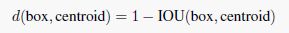
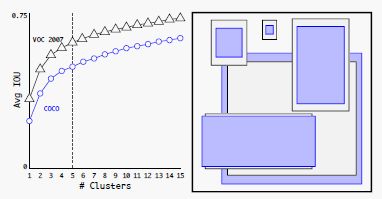
聚类主要目的得到不同大小框的最优先验(与gt的iou);使用K-Means采用5个anchor就可以和预设9个anchor达到相同的效果
- 限制位置预测:在faster rcnn中关于box的相对位置预测中,会采用下式进行坐标的回归预测,这在YOLO训练初期会导致不稳定。因为整个公式没有任何限制,导致box可以偏移的范围非常大,因此需要很长的一段训练时间才能稳定下来。
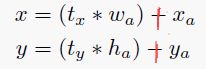
因此作者由根据YOLO的特性进行了一些修改,不去优化gt与预测框之间的偏差,而是以网格cell为参照进行优化【YOLO只对包含物体中心的网格进行回归优化,因此可以直接针对网格优化】,具体如下式所示:
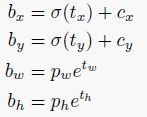
其中 ( c x , c y ) (c_x,c_y) (cx,cy)表示当前cell grid距离图像左上角的横向/纵向偏移值(可以理解为坐标点); σ \sigma σ表示logistic激活,将 t x , t y t_x,ty tx,ty(中心点偏移量)限制在(0,1)之间; p w , p h p_w,p_h pw,ph表示预设框的宽度与高度值, t w , t h t_w,t_h tw,th表示预测的长宽偏移量,具体参照下图。
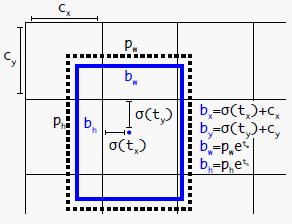
通过限制预测的范围,使得模型参数更容易学习,整个训练过程也更稳定。与直接使用Anchor相比,使用维度聚类以及直接预测边界框中心位置可将 YOLO 提高近 5%。
这种方式巧妙地利用上了YOLO的特点(每个grid cell负责检测对应位置的目标),同时也解决了训练不稳定的问题。那么为什么在YOLO训练中不稳定呢?作者分析原因是对anchor没有限制,导致每个预测框在初期会出现大尺度偏移。
为什么会出现大尺度偏移呢?我个人认为是因为在YOLO,最后的特征图上的每个grid cell都有非常大的感受野,而Faster RCNN只是根据对应anchor那部分的特征进行偏移量预测的,所以不会出现这个问题。
- 引入精细特征:YOLO最后输出的特征图分辨率为
13x13,对于一些小目标的检测会比较困难。因此YOLO v2采用了一个passthrough layer来融合底层特征:具体做法是从之前的阶段选取了一个26x26x512的特征图,将其转换成13x13x2048的特征图,然后与特征图进行深度上的拼接。
paththrough layer本质上是一个特征重排,可以这么理解:按行和列进行隔点采样,就可以得到四个结果,然后将采样结果concat起来即可,如下图所示(和现在的vision transformer处理图像块很类似)。
https://www.bilibili.com/video/BV1yi4y1g7ro?p=2&spm_id_from=pageDriver
https://www.zhihu.com/question/58903330
关于为什么要额外构造出这个layer,而不是直接进行普通的下采样呢?这是因为maxpooling和avgpool会损失一些特征信息,而这个不会丢失原本的特征信息,对精细预测任务更有益,其代价就是参数量会增加。
Faster RCNN和SSD通过获取不同层级的特征图(FPN操作)来解决这个问题
- 多尺度训练:每隔10个batch,从预设集合中{320,352,…,608}随机地选择一个图像尺寸进行
resize,这样在训练过程中可以强迫网络去捕获到不同目标尺寸的特征。小的输入尺寸网络的计算会很快,大的会比较慢,但精度高,所以这个方法也算是同时权衡了速度和精度。
因为采用全卷积网络,所以图像的输入尺寸没有关系
最后不同方法的增益如下所示:

下图表示了YOLO v2的性能,不同的点代表不同的测试分辨率。
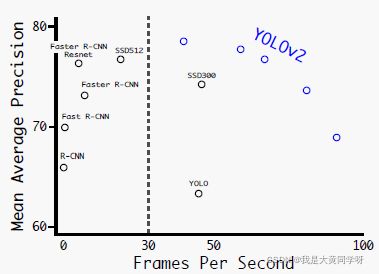
faster:为了提升速度,YOLO v2提出了一个新的backbone,称为DarkNet-19,其由卷积+Maxpool组成,在后面每个block中会用到1x1conv(类似于ResNet中的bottleneck),同时兼备精度和速度。该架构的网络参数较VGG-16更少,在ImageNet上,仍然可以达到top-1 72.9%以及top-5 91.2%的精度。作者将DarkNet在ImageNet上进行预训练后(和上文提到的方法一致,先224再448),去掉最后的卷积层和avgpool层,然后新增了一些3x3卷积层,最后输出SxSx(Bx(5+C))的特征图。
值得注意的是,这里和YOLOV1不一样,v1的通道数是(B*5+C),每个
grid cell只预测一个目标,而这里进行了解耦,可以同时预测5个框。
stronger:这一章节主要是介绍全文最大的创新点,如何级联训练分类数据集和检测数据集。首先为什么要级联训练呢?这个任务的意义在哪?这是因为分类数据集的标注更简单,因此可获取的数据集体量也就更大(标签类别更多),因此可以使用分类数据集来扩展器可检测类别的种类。其核心思想在于:对于检测数据使用检测loss优化,对于分类数据仅使用分类loss优化。
- 挑战:但这种策略存在一些问题,因为对于检测数据[coco]来说,通常只有常见的类别数;而分类数据[ImageNet]的类别标签更细粒度,如果要级联训练的话,肯定要找到一种方法使得类别标签连贯起来。比如coco里面只有
狗这一个类别,而ImageNet中包含了各种犬种的标签。
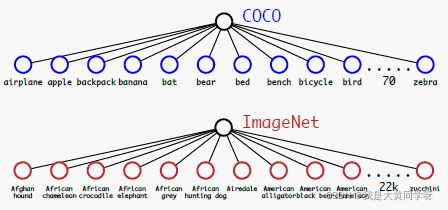
不能直接使用softmax,因为softmax默认各个类之间是互斥的;可以使用多标签的方式[
sigmoid]来进行训练,但是多标签的形式忽略了数据结构【比如coco数据集中各类是互斥的】
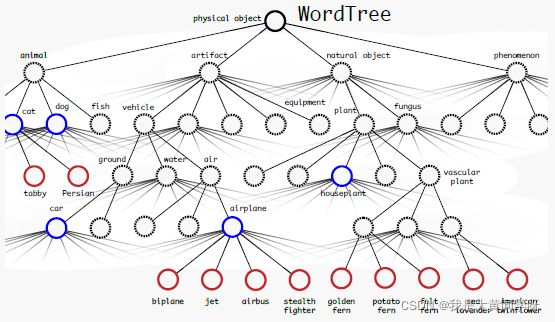
- WordTree:作者根据WordNet的思想,构造了
WordTree(由有向图变成了树),如下所示[蓝色来自coco,红色来自ImageNet]。
- 细节:跟WordTree,现在的分类任务变成了变成了预测每一个节点相对于其父节点的条件概率,比如下图1。如果要计算某个节点的绝对概率,那么直接根据概率论求得其联合概率即可,如下图2所示。并且基于
WordTree,作者事先用DarkNet在ImageNet上进行了一个分类预实验,如下图3所示。


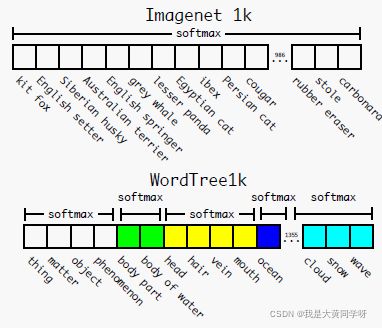
联合训练:按照wordtree的方法将COCO和ImageNet前9000个类别进行合并训练,然后在ImageNet detection数据集上进行测试,有9418个节点,因此模型最后的输出通道变为(3x(5+9418))。
这一章节有很多细节和新知识点,并且最后的效果其实也非常一般,所以我只大概介绍了具体的技术要点,更多细节和解读可以参照以下视频:https://www.bilibili.com/video/BV1Q64y1s74K?p=2
2.2 特点
- 性能高速度更快:相比于v1,v2引入了当时很多先进的技术,大幅度提升了检测性能,并做了一些创新。比如对于anchor的使用,v2不是像faster rcnn那样直接输出偏移量,而是做了一定的限制;创建了多尺度训练,anchor尺寸聚类等经典提点技术,在后续的算法中也得以应用。而速度快主要收益于提出的DarkNet模型,轻量且速度快。
- 探索半监督学习:开创性地进行了分类数据+检测数据的联合训练尝试,提升了模型的类别检测能力(初步尝试,效果一般)。
2.3 总结
总得来说,v2相比于v1,其在整体的训练流程和训练策略上做了不少尝试与改进,速度更快,性能也更好。我个人觉得,最大的改进就是引入anchor这一概念,相比于v1直接输出预测框的中心点和长宽,v2输出的是预设anchor的相对偏移量,这大幅提升了召回率和yolo的上限,也将yolo搬到了anchor-based的主战线上。
3. YOLO v3
YOLOv3的原"论文"写得非常潦草,李沐老师也曾吐槽说是他读过最烂的论文。其实这篇文章只是Joseph Redmon的一个技术报告/总结,里面写了一些提升性能的策略以及做过的一些不work的方法,并与当时SOTA方案进行了比较。因此本节的方法介绍顺序与论文中的顺序不太一致,主要参考资料[1]进行介绍。
参考资料:
[1] B站视频资料
[2] yolo论文解读
[3] 资料1对应的文档资源
3.1 整体算法
网络结构:从v2开始,作者就开始搭建自己的backbone(DarkNet-19),在v3中又进一步提升了模型的深度,并参考ResNet中的残差结构,抛弃了池化层,构造了Darknet-53,如下所示:
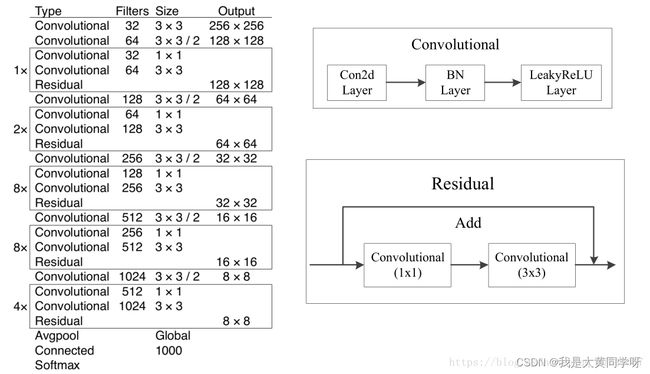
其中每个框中都为一个残差结构,其整体结构其实与resnet很像,区别主要在于
bottleneck block的构造方式不一样(1x1 conv + 3x3 conv)。其在ImageNet上与ResNet-152精度持平,且速度快了两倍多。
图片来自参考资料3
并且作者参照了FPN的思想,输出三种不同尺寸的特征图,分别在其上进行检测框的预测。如下图所示,作者输出了52x52,26x26,13x13等三种尺度。并且在v2中也提到对anchor框进行了K-Means聚类,v3聚类得到9中不同的尺寸,分别分发到三种尺度特征图上预测,正好每个特征图包含三种尺度: N × N × [ 3 ∗ ( 4 + 1 + 80 ) ] N\times N \times [3 * (4+1+80)] N×N×[3∗(4+1+80)].
KMeans聚类相关代码:https://blog.csdn.net/qq_37541097/article/details/119647026
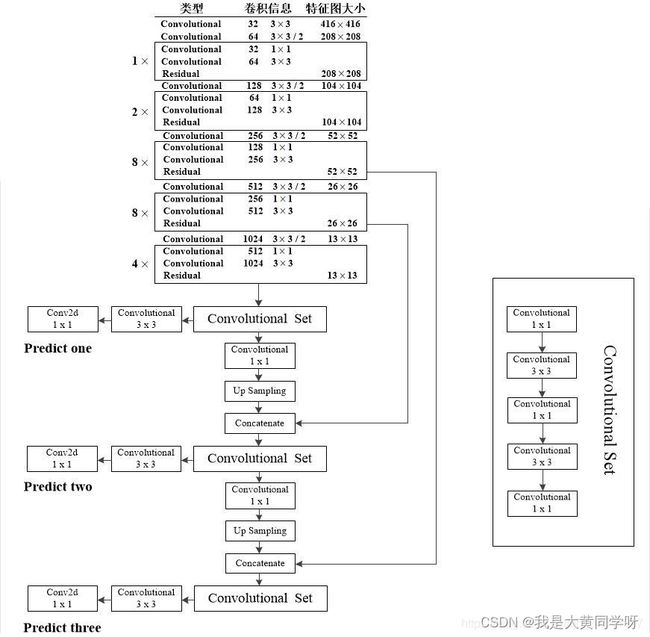
与FPN的不同在于其与浅层特征的结合是concat,而不是相加;
图片来自参考资料3
检测框的预测:与v2的机制一模一样,采用特殊的anchor机制:1. 增加sigmoid限制;2. 边界框的中心偏移量是相对于girder cell左上角坐标的偏移。
正负样本的匹配:1. 有几个gt就有几个正样本;2. 与gt重合程度最大的box作为正样本;3. 对于不是iou最高但大于某个阈值的box,直接丢弃,不计算loss;4. 剩下的所有box均为负样本。对于负样本的loss计算仅考虑置信度损失(无法考虑坐标损失和类别损失)
但这样会出现一个问题,在训练时正样本的数量会非常少,因此在一些其他版本的v3实现中,会将与gt的iou大于某个阈值的anchor都视为正样本(左上角对齐计算iou)。
损失计算:v3的损失主要由三个损失组成,置信度损失+分类损失+定位损失 。其中置信度和分类损失使用BCE loss,定位损失还是SSE(sum of squared error loss)。这里与v1,v2不太一样的是真实置信度不再是iou值而是1 or 0,其中1表示正样本,0为负样本。
![]()
来自资料3
一些失败的尝试:作者还进行了一些尝试,但效果不好,最终没有采用:① 正常的anchor预测机制;② 线性映射代替logistic;③ focal loss;④ 双重iou(大于某个值为正样本,小于某个值为负样本)。
资料1中还介绍了u版的yolov3,相比于原始的v3性能提升了不少。主要提点策略:
- Mosaic图像增强:数据多样性+增加目标个数+BN层的统计参数更好-相当于增加batch size) ;
- SPP模块:参照SPP模块,进行不同尺寸的Maxpool,然后进行concat;
- CIoULoss:参照我的另一篇博客https://blog.csdn.net/qq_36560894/article/details/123172176
关于实现上的更多细节,参照这篇文章:https://zhuanlan.zhihu.com/p/76802514
3.2 特点

- 速度快,准确率高:相比于前两个版本,v3仍然继承了速度快的优势,并且在传统指标上(mAP_50)表现亮眼,如上图所示;
- 定位精度不够:在mAP_75等对定位要求更高的指标上,v3的表现性能不够好,整体性能比RetinaNet低了不少;
- 小目标检测能力较差:对于小目标的检测,仍然不够好。
3.3 总结
yolo v3整体的结构基本上没有太大的改变,主要是从网络结构上进行一些改变,以及对网络训练过程中的细节进行了一些详细解释。