人工智能如何 “学习“--监督学习、无监督学习、强化学习
随着Pepper和自动驾驶汽车的出现,"机器人 "对不是工程师的普通大众来说越来越熟悉。 机器人使用各种软件技术,特别是 "人工智能(AI)"。
监督式学习、无监督式学习
我们如何在机器学习中学习或训练?一种典型的学习方式是同时教机器一个问题和一个答案。 在下面的例子中,机器被要求分析一个狗的图像,正确答案是 "分类是狗"。 这被称为 "标记的数据"(有正确答案的数据)。
用标记的数据进行训练学习
那么,如果你知道正确的答案,机器会分析出什么?"为什么它被归类为狗? 换句话说,让机器自己去发现 "功能"。 换句话说,机器自己发现了一个 "特征"---它被归类为 "狗"---这个特征就是 "狗"。

作为训练数据,我们输入一张带有正确答案的图像(标记数据)。 由于已知正确答案是狗,机器就会学习分析的特征是 "狗 "的特征,通过学习大量的特征,积累应该归类为狗的特征,提高准确率。
然而,如果系统只通过分析一张图片来学习特征,它将无法识别同一类型的狗,除非向它展示其他非常相似的狗的图片。 如果该系统在1000万张有标签的狗的数据图像上进行训练,它将更有可能通过从大量的特征中进行匹配来识别一只狗。
这是研究神经网络的(一种)方法,也是它们需要大量大数据来学习的原因。 在这个狗的例子中,用标记的数据学习的方法被称为 "监督学习"。
机器学习有两种类型:监督式学习和无监督式学习。
监督学习使用的训练数据在输入数据和正确答案之间存在一对一的关系,例如,这张图片是一只狗,或者在这种情况下,一小时后的股票价格会是多少。
"无监督学习 "意味着输入图像是可用的,但正确答案却不是。 预测是关于未来的,所以没有正确的答案。 无监督学习是指从没有正确答案或正确答案未知的问题中学习的做法,如推理或分析。
有一些方法可以混合监督和非监督学习。 在这种方法中,首先通过监督学习让机器学习特征,然后通过无监督学习给它大量的训练数据,它自动计算出特征并反复学习。 这有时被称为 "半监督学习"。
最佳的学习方法将取决于机器学习的应用和使用,因此,使用有可能带来最佳性能的学习过程是很重要的。
监督学习的例子:判断手写的字母和数字
"监督学习",如前所述,是一种利用标记数据进行学习的方法。
前面提到的通过分析狗的图像学习特征的系统,其正确答案是 "分类是狗",这是一个典型的监督学习的例子。
同样,让我们以一个系统为例,让机器判断手写的字母和数字。
输入的是手写字母和数字的扫描图像。 输出(答案)是识别该图像的结果。 在监督式机器学习的情况下,输入是带有正确答案的手写字符图像。
以楷体书写的字母和数字很容易被机器正确识别,但以破体书写的字母,机器一开始就很难识别。 特别是字母 "2 "和 "7",它们的形状截然不同,但在现实世界中都是常用的。 如果有一个确定的正确答案,监督学习是提高答案正确性的一个好方法。

知道正确的答案并让计算机理解其特征比让计算机在没有任何信息的情况下了解到例子中的数字与 "2 "和 "7 "相同更有效率。 我们事先准备好几个带有破损字母和正确答案的训练数据模式(Labeled Data),并对它们进行训练。

计算机通过将正确答案(标签)附加到手写数字的训练数据上进行训练。 计算机将断裂的书写状态和特殊性作为特征来学习,正确识别任何手写数字的概率就会增加。
最终,你可以输入任意的手写数据,而计算机将能够识别这些数字。 下一阶段是尝试输入更多的手写图像,例如,在显示屏上一个接一个地显示计算机的判断,然后检查(评分)人类是否正确识别了数字。 如果它错了,我们就教它什么是正确答案,它就会重新学习这个特征。
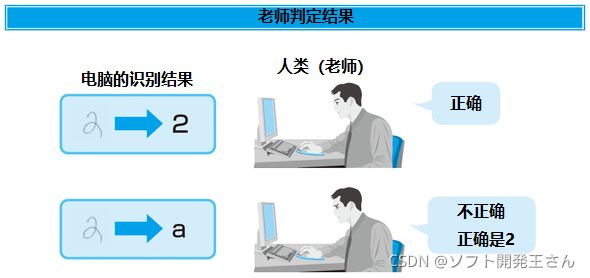
人看着机器给出的答案并决定它们是否正确。
有监督和无监督学习的使用
机器学习最著名的例子之一是 "谷歌的猫"。 在这个案例中,据说计算机通过对大量的图像数据(主要是来自YouTube的视频数据)进行为期一周的无监督学习,能够识别 "猫"。 一般来说,如果你想建立一个能够识别 "猫 "的系统,如上所述,你可以使用监督学习方法,展示大量有正确答案的 "猫 "的图像。 然而,谷歌的猫能够通过使用无监督学习来分析图像和视频来识别猫的存在。
然后他们在监督学习中训练神经网络,以提高其图像识别的准确性。 当他们建立一个分类器来评估该神经网络时,他们发现相对于以前的识别率,它提高了70%以上的准确性。 深度学习在图像和语音识别方面特别成功,现在正被应用于许多领域。 除了图像和语音识别,它还有望被用于对话式聊天机器人,以及各种数据分析和预测。
谷歌的AlphaGo被称为围棋中的世纪游戏,它首先通过阅读互联网上大量的围棋游戏数据进行训练,包括3000万步棋。 起初,它是 "监督下的学习",就像它是由人教的。 但这并不是足够的训练数据,所以AlphaGo团队随后让计算机自动进行围棋对弈。 他们使用无监督学习来学习和积累新的数据,这可以称为经验。 据说,所玩的游戏数量为3000万。 这就是 "强化学习",它作为一个关键词也引起了人们的关注。
谷歌DeepMind的DQN还帮助一台计算机自行学习了一个街区破坏游戏的规则,使其得分高于人类。 在这个例子中,从一开始就使用了无监督学习。 起初,计算机忽略了落下的球,不知道它意味着什么,但后来它了解到,只要不小心弹到球,撞到挡板,就能得分。 因此,在无监督学习中,机器不只是随机地重复分析,而是需要有一个目标,以获得正确的答案或加强。
这就是 "奖励 "变得重要的地方。 在视频游戏中,这将是一个分数,或 "明确的奖励",但在机器学习中,给一个分数很重要。
强化学习
"强化学习 "是机器学习的一种类型,它包含在无监督学习中(尽管有些人认为它既不是有监督的,也不是无监督的)。应用于日常学习,这有点像通过 "习惯 "来学习,或通过 "做中学 "来学习。
通过试错学习:强化学习
"强化学习 "类似于一种学习方法,它从试错训练开始,通过反复实现最近的目标并进入下一个层次来取得进展。
我们都知道,计算机非常善于执行人类制造的程序的确切内容。 大多数程序是用字母数字代码编写的,所以创建程序的过程被称为 "编码"。 一般来说,计算机要求程序员不仅要描述基本的处理步骤,而且要描述如何处理和处理各种可能的情况。 编码就像一本手册,这是计算机最需要遵循的东西。 换句话说,你不能处理任何没有写在手册中或程序中描述的东西。
人类学习的某些方面不能用手册来描述。 例如,考虑骑自行车。
即使手册告诉你如何骑自行车,而你也读了它,但这并不意味着你将能够骑自行车。 你可能无法骑它。 你需要很好地学习如何骑自行车,以便能够真正把它骑到目的地。 我们中的许多人都有过这样的经历:尽管摔了几次,但逐渐增加骑车的距离,从1米到5米、10米、50米等等,最终完美地掌握了骑车的技巧。
"'强化学习'需要一个'奖励'
这同样适用于 "强化学习"。 这是一种让机器通过试错,而不是通过编码,从错误和成功中学习的方法。 然而,如果你只是给机器大量的训练问题,它将不知道什么是成功,也就无法学习。 作为一个学习目标,我们需要给机器一些东西来判断成功。 所以我们给他们的成功或成就打分。 这被称为 "奖励 "或 "分数"。
在骑自行车的例子中,移动10米的分数会比跑1米摔倒的分数要高。如果你能在较长的时间内保持平衡而不摔倒,你就能得到较高的分数。 分数越高,计算机就越成功,它将能够自主地学习如何通过重复执行获得更高的分数和规则。
“强化学习”在开发上有很有效率的一面。 例如,如果你要开发一个可以骑自行车的机器人,你想通过编程和编码来控制它的姿势,你需要与许多传感器合作,分析诸如倾斜、速度、重心、开/关踏板力等信息,并考虑到所有的身体位置来调整平衡和踏板力。 它将需要进行编程,以考虑到所有的身体位置,并调整平衡和踏板力。 仅仅是想到这一点就令人生畏。 理想情况下,编程也应考虑到从雨后湿滑的道路到自行车略微向右转而不是直行的倾向。 你需要试一试,调整它,纠正它,然后重复。
如果这是用强化学习来完成的,而不是人类为每一种情况和环境进行编程,那么就有可能让机器人根据来自传感器等的信息,自主地学习如何以最佳方式平衡自己,以及如何在不摔倒的情况下向前移动(如果机器人每次摔倒都会崩溃,那就没有效率了。 (如果每次都把机器人摔坏,效率就会很低,所以必须有一种方法让它一直学习到摔倒的那一刻。即使机器需要很长的时间来掌握平衡控制,而机器也需要掌握平衡控制,如果机器人自主学习,只要让它独自一人,它就会自主学习,因此,人类的开发成本和精力可望大大降低。
强化学习例子
当你读到关于强化学习的解释时,你常常会有这样的印象:由于所有的表达方式都很难理解。为了更具体的理解,这里简要解释一下 "代理人"、"环境"、"行为 "和 "奖励 "的含义。 这些都是强化学习中的重要词汇。
例如,将一只老鼠放在一个带有机制的计量器中,当按下一个按钮时,诱饵从透明的诱饵盒中流出。 老鼠发现诱饵后很兴奋,但不能吃,因为它在透明的诱饵盒里。 因此,一开始,老鼠不知道该怎么做,会试图移动透明的诱饵盒,或者通过咬破它,以便以某种方式获得诱饵。 然后,有一天,在偶然的情况下,它们按下一个按钮,得到了食物。 在经历了几次之后,老鼠强化了这种行为模式,最终学会了按下按钮就能得到食物的规则。
鼠是 "代理人",带有陷阱的仪表是 "环境",咬人和移动是 "行为",而成功获得的食物是 "奖励"。 强化学习的要点是设置这四个要素,让计算机反复学习和体验。
在老鼠的例子中,奖励是被喂食和能够吃到食物,但有些行为可能是痛苦的。 然而,有些行为可能是痛苦的,比如爬到透明的喂食器上而滑倒,或者咬住喂食器而牙疼。 有些行动不仅没有实现其回报,而且还可能产生负面的后果。 无论是从自行车上摔下来,还是从喂食器上摔下来,这种经历最终会导致负面的分数,而孩子会学会在下一次避免。 这些经验重复得越多,有机体可能就越 "聪明"。 同样地,计算机接受的培训越多,它就有可能变得更有经验和更聪明。
另外,与生物体不同,计算机不会因为反复玩同样的游戏和尝试同样的事情而感到痛苦或厌倦。 虽然积累一些技能需要时间,但它的优点是可以随着时间的推移独自学习。
结束语
"AlphaGo "通过 "强化学习 "变得更加强大,这是一个自动玩游戏的过程。 事实上,AlphaGo在比人们隐约预测的更短的时间内学到了这么多东西,以至于它比预测的时间更早地击败了世界上领先的职业棋手。 这证明了机器学习的潜力。
然而,你可能会对 "人工智能已经超过人类 "的说法感到不舒服。 我们要对抗的不是人工智能,是 "通过机器学习变得更聪明的计算机",而不是人工智能。
有些人担心人工智能会很快超过人类的智慧。 有些人担心,人工智能会在眨眼间超过人类的智慧,但目前情况并非如此。 可以说,深度学习和强化训练在围棋中的应用比专家预测的要有效和实用得多,没有必要认为 "人工智能是值得恐惧的"。