继 Swin Transformer 之后,MSRA 开源 Video Swin Transformer,在视频数据集上SOTA
关注公众号,发现CV技术之美
继上半年分享的『基于Transformer的通用视觉架构:Swin-Transformer带来多任务大范围性能提升』、『Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源』,Swin Transformer 惊艳所有人之后,MSRA 开源 〖Video Swin Transformer〗,效果如何?
详细信息如下:

论文链接:https://arxiv.org/abs/2106.13230
项目链接:https://github.com/SwinTransformer/Video-Swin-Transformer
导言:
由于Transformer强大的建模能力,视觉任务的主流Backbone逐渐从CNN变成了Transformer,其中纯Transformer的结构也在各个视频任务的数据集上也达到了SOTA的性能。这些视频模型都是基于Transformer结构来捕获patch之间全局的时间和空间维度上的关系。
在本文中,作者提出了video Transformer中的局部性假设偏置,这能使Transformer在速度和精度上达到更好的trade-off,这在以前的那些基于捕获时空域上全局关系的Transformer上是做不到的。在本文中,视频结构中的局部性是通过Swin Transformer实现的。
另外,由于视频和图片本身就存在很大的联系,而且本文也在用了Swin Transformer结构,所以作者采用了在图片数据集上预训练好的模型模型来初始化,以提高视频模型的泛化能力。本文提出的方法在广泛的视频识别基准数据集上实现了SOTA的准确性,包括动作识别(action recognition)和时间建模(temporal modeling)。
01
Motivation
基于卷积的主干网络长期以来一直主导着计算机视觉中的视觉建模任务。然而,目前图像分类的主干网络,正在进行从卷积神经网络(CNN)到Transformer的转变。这一趋势始于Vision Transformer(ViT)的引入,ViT成功之处主要在于捕获了不重叠Patch之间的全局关系。ViT在图像上的巨大成功导致了基于Transformer结构的视频识别任务的研究。
对于以前的卷积模型,视频任务的Backbone主要就是增加了一个卷积维度用于捕获时间上的关系。由于联合时空(时间-空间)建模比较费计算资源并且不容易优化,一些研究工作者也提出了分解时空建模,来达到更好的速度-精度权衡。在Transformer中,也有类似的工作,同样起到了比较好的速度-精度权衡作用。
在本文中,作者提出了一种基于Transformer的视频识别主干网络结构,并且它在效率上超过了以前的分解时空建模的模型。因为视频数据在时间和空间上存在局部性(也就是说:在时空距离上更接近的像素更有可能相关 ),所以作者在网络结构中利用了这个假设偏置,所以达到了更高的建模效率。由于这一特性,全局的时空Self-Attention可以近似为多个局部Self-Attention的计算,从而大大节省计算和模型规模。
作者通过Swin Transformer[1]来实现这一点,因为Swin Transformer也考虑了空间局部性、层次结构和平移等变性等假设偏置。
作者在本文提出的Video Swin Transformer,严格遵循原始Swin Transformer的层次结构,但将局部注意力计算的范围从空间域扩展到时空域。由于局部注意力是在非重叠窗口上计算的,因此原始Swin Transformer的滑动窗口机制也被重新定义了,以适应时间和空间两个域的信息。
由于Video Swin Transformer改编于Swin Transformer,因此Video Swin Transformer可以用在大型图像数据集上预训练的模型进行初始化。通过用在ImageNet-21K上预训练的模型初始化,作者发现,主干网络的学习速率需要比head更小(head是随机初始化的)。因为主干网络在拟合新的视频输入时,需要慢慢地忘记了预训练的参数和数据,从而得到更好的泛化性能。这一现象为进一步研究如何更好地利用预训练过的权值提供了新的方向。
02
方法
2.1 Overall Architecture
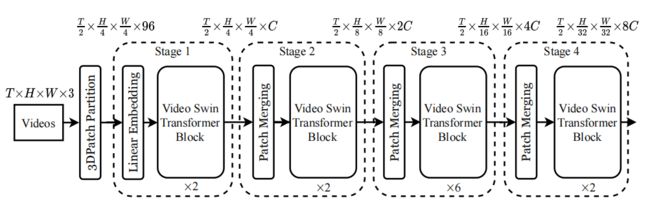
Video Swin Transformer的总体结构如上图所示。输入的视频数据为
的张量,由T帧的H×W×3的图片组成。在Video Swin Transformer中,作者用的3D patch的大小为 2×4×4×3,因此就可以得到 个 3D Patch,然后用线性embedding层将特征映射到维度为 C的 token embedding。
为了能够严格遵循Swin Transformer的层次结构,作者在时间维度上没有进行降采样,每个stage只在空间维度上进行了2×2的降采样。Patch合并层连接每组2×2个空间相邻patch的特征,并应用一个线性层将连接的特征投影到原来通道尺寸的一半。例如,第二阶段中的线性层将每个通道维度为4C的token映射为2C。
该体系结构的主要组件是 Video Swin Transformer block,这个模块就是将Transformer中 multi-head self-attention (MSA)替换成了基于3D滑动窗口的MSA模块。具体地说,一个 video Transformer block由一个基于3D滑动窗口的MSA模块和一个前馈网络(FFN)组成,其中FFN由两层的MLP和激活函数GELU组成。Layer Normalization(LN)被用在每个MSA和FFN模块之前,残差连接被用在了每个模块之后。
2.2 3D Shifted Window based MSA Module
与图像相比,视频需要更多的输入token来表示它们,因为视频另外有一个时间维度。因此,一个全局的自注意模块将不适合视频任务,因为这将导致巨大的计算和内存成本。在这里,作者遵循Swin Transformer的方法,在自注意模块中引入了一个局部感应偏置。
2.2.1 在不重叠的三维窗口上的MSA

在每个不重叠的二维窗口上的MSA机制已被证明对图像识别是有效并且高效的。在这里,作者直接扩展了这种设计到处理视频输入中。给定一个由 个3D token组成的视频,3D窗口大小为 ,这些窗口以不重叠的方式均匀地分割视频输入。这些token被分成了多个不重叠的3D窗口。
如上图(中)所示,对于输入大小为8×8×8的token和窗口大小为4×4×4,第 层中的窗口数将为2×2×2=8。
2.2.2. 3D Shifted Windows
由于在每个不重叠的三维窗口中都应用了多头自注意机制,因此缺乏跨不同窗口的关系建模,这可能会限制特征的表示能力。因此,作者将Swin Transformer的移位二维窗口(shifted 2D window)机制扩展到三维窗口,以引入跨窗口连接,同时保持基于非重叠自注意的高效窗口计算。对于Self-Attention模块的第一层,就如上面所示采用均匀分块的方式。对于第二层,窗口分区配置沿着来自上一层自注意模块的时间、高度和宽度方向分别移动
、 、 个token的距离。
如上图(右)所示,输入大小为8×8×8,窗口大小为4×4×4。由于 层采用常规的窗口划分, 层中的窗口数为2×2×2=8。对于第 层,当窗口会在三个方向上分别移动 ( ) 个token的距离,因此窗口数量为3×3×3=27。
采用滑动窗口划分的方法,两个连续的Video Swin Transformer块计算如下所示:


2.2.3. 3D Relative Position Bias
先前的工作已经表明,在自注意计算中包含相对位置编码对于performance的提升是有用的。因此作者在Video Swin Transformer也引入了3D相对位置编码,计算方式如下:

2.3 Architecture Variants
基于上面的设计,作者提出了下面四种不同参数量和计算量的网络结构:

2.4 Initialization from Pre-trained Model
由于Video Swin Transformer改编于Swin Transformer,因此Video Swin Transformer可以用在大型图像数据集上预训练的模型参数进行初始化。与Swin Transformer相比,Video Swin Transformer中只有两个模块具有不同的形状,分别为:线性embedding层和相对位置编码。
输入token在时间维度上变成了2,因此线性embedding层的形状从Swin Transformer的48×C变为96×C。在这里,作者直接复制预训练过的模型中的参数两次,然后将整个矩阵乘以0.5,以保持输出的均值和方差不变。
相对位置编码矩阵的形状为 ,而原始Swin Transformer中的形状为 。为了使相对位置编码的矩阵一样,作者将原来的 相对位置编码矩阵复制了 次。
03
实验
3.1 Comparison to state-of-the-art
3.1.1. Kinetics-400

上表展示了与SOTA的主干网络进行了比较的结果,包括基于卷积和基于Transformer的网络在Kinetics-400的结果。
3.1.2. Kinetics-600

上表展示了与SOTA的主干网络进行了比较的结果,包括基于卷积和基于Transformer的网络在Kinetics-600的结果。
3.1.3. Something-Something v2

上表将本文的方法与SSv2上的SOTA方法进行了比较。
3.2. Ablation Study
3.2.1. Different designs for spatiotemporal attention
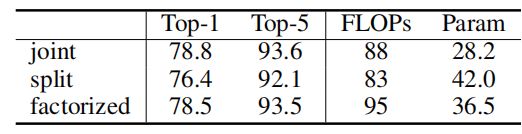
我们可以观察到,joint版本达到了最佳的速度-精度的权衡。这主要是因为在joint版本中,空间域中的局部性在保持了有效性的同时减少了的计算。
3.2.2. Temporal dimension of 3D tokens

可以看出,更大的时间维度会达到更高的Top-1名精度,但也会具有更高的计算成本、较长的推断时间。
3.2.3. Temporal window size

可以看出,时间局部性可以提高视频识别的速度-精度权衡。
3.2.4. 3D shifted windows
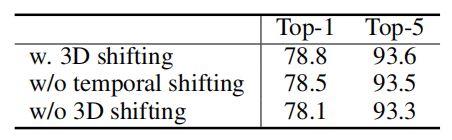
结果表明,3D shifted windows方案在非重叠窗口之间建立连接是有效的。
3.2.5. Ratio of backbone/head learning rate

可以看出,Backbone上更小的学习率可以达到更好的性能。
04
总结
在本文中,作者提出了一种基于时空局部感应偏置的视频识别纯Transformer的结构。该模型从用于图像识别的Swin Transformer改变而来,因此它可以利用预训练的Swin Transformer模型进行参数的初始化。该方法在三个广泛使用的视频基准数据集上(Kinetics-400, Kinetics-600, Something-Something v2)测试,并且实现了SOTA的性能。
参考文献
[1]. Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." arXiv preprint arXiv:2103.14030 (2021).
作者介绍
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV
END,入群????备注:TFM
