重新定义弱光增强的质量、效率和价值的峰值点,CVPR2022 Oral :Toward Fast, Flexible, and Robust Low-Light Image Enhancement
Toward Fast, Flexible, and Robust Low-Light Image Enhancement
Long Ma†, Tengyu Ma†, Risheng Liu‡*, Xin Fan‡, Zhongxuan Luo†
†School of Software Technology, Dalian University of Technology
‡International School of Information Science & Engineering, Dalian University of Technology
[paper] [github]
先睹为快,看看本文和先前的 SOTAs 的比较:
Figure 1. Comparison among recent state-of-the-art methods and our method. KinD [34] is a representative paired supervised method.EnGAN [11] considers the unpaired supervised learning. ZeroDCE [7] and RUAS [14] introduce unsupervised learning. Our method(just contains three convolutions with the size of3×3) also belongs to unsupervised learning. As shown in the zoomed-in regions, thesecompared methods appear incorrect exposure, color distortion, and insufficient structure to degrade visual quality. In contrast, our resultpresents a vivid color and sharp outline. Further, we report the computational efficiency (SIZE, FLOPs, and TIME) in (b) and numericalscores for five types of measurement metrics among three tasks including enhancement (PSNR, SSIM, and EME), detection (mAP), andsegmentation (mIoU) in (c), it can be easily observed that our method is remarkably superior to others.

下面是正文。全文的讨论和研究思路逻辑性强,调理清晰且较严密。
目录
Abstract
Introduction
Method
1. Illumination Learning with Weight Sharing
2. Self-Calibrated Module
3. Unsupervised Training Loss
Algorithmic Properties
1. Operation-Insensitive Adaptability
2. Model-Irrelevant Generality
官方代码
Abstract
Existing low-light image enhancement techniques are mostly not only difficult to deal with both visual quality and computational efficiency but also commonly invalid in unknown complex scenarios.
In this paper, we develop a new Self-Calibrated Illumination (SCI) learning framework for fast, flexible, and robust brightening images in real-world low-light scenarios.
To be specific, we establish a cascaded illumination learning process with weight sharing to handle this task. Considering the computational burden of the cascaded pattern, we construct the self-calibrated module which realizes the convergence between results of each stage, producing the gains that only use the single basic block for inference (yet has not been exploited in previous works), which drastically diminishes computation cost.
We then define the unsupervised training loss to elevate the model capability that can adapt general scenes.
Further, we make comprehensive explorations to excavate SCI’s inherent properties (lacking in existing works) including operation-insensitive adaptability (acquiring stable performance under the settings of different simple operations) and model-irrelevant generality (can be applied to illumination-based existing works to improve performance).
Finally, plenty of experiments and ablation studies fully indicate our superiority in both quality and efficiency.
Applications on low-light face detection and nighttime semantic segmentation fully reveal the latent practical values for SCI.
现有方法的问题:视觉效果、计算效率和面对未知场景的无奈。
本文提出:自校准照明 (Self-Calibrated Illumination, SCI) 学习框架,快速、灵活、鲁棒性好。
首先,建立了一个具有权值共享的级联照明学习过程来处理这个任务。考虑到级联模式的计算负担,本文构建了自校准模块(self-calibrated module),实现了各阶段结果之间的收敛,产生了只使用单个基本块进行推理的增益 (在以前的工作中还没有利用),大大降低了计算成本。
然后,定义了无监督训练损失,以提高模型适应一般场景的能力。
进一步,对 SCI 的内在特性 (现有著作所缺乏的) 进行了综合探索,包括操作不敏感的适应性 (在不同的简单操作设置下获得稳定的性能) 和与模型无关的通用性 (可以应用于基于光照的现有著作以提高性能)。
最后,大量的实验和消溶研究充分表明了本文方法在质量和效率方面的优势。
在弱光人脸检测和夜间语义分割方面的应用充分揭示了 SCI 潜在的实用价值。
Introduction
Contributions:
To settle the above issues, we develop a novel Self-Calibrated Illumination (SCI) learning framework for fast, flexible and robust low-light image enhancement. By redeveloping the intermediate output of the illumination learning process, we construct a self-calibrated module to endow the stronger representation to the single basic block and convergence between results of each stage to realize acceleration. More concretely, our main contributions can be concluded as:
• We develop a self-calibrated module for the illumination learning with weight sharing to confer the convergence between results of each stage, improving the exposure stability and reduce the computational burden by a wide margin. To the best of our knowledge, it is the first work to accelerate the low-light image enhancement algorithm by exploiting learning process.
• We define the unsupervised training loss to constrain the output of each stage under the effects of selfcalibrated module, endowing the adaptation ability towards diverse scenes. The attribute analysis shows that SCI possesses the operation-insensitive adaptability and model-irrelevant generality, which have not been found in existing works.
• Extensive experiments are conducted to illustrate our superiority against other state-of-the-art methods. Applications on dark face detection and nighttime semantic segmentation are further performed to reveal our practical values. In nutshell, SCI redefines the peak-point in visual quality, computational efficiency, and performance on downstream tasks in the field of network-based low-light image enhancement.
为了解决上述问题(现有方法的不稳定性,特别是在未知的现实场景中,不清楚的细节和不适当的曝光是普遍存在的),本文开发了一种新的自校准照明 (SCI) 学习框架,用于快速、灵活和鲁棒的微光图像增强。通过重新开发照明学习过程的中间输出,构建了一个自校准模块,赋予单个基本块更强的表示性和每个阶段的结果之间的收敛性,以实现加速。主要贡献可以总结为:
开发了一个具有权重共享的自校准照明学习模块,以协调每个阶段的结果之间的收敛,提高曝光稳定性,并大幅度减少计算负担。这是第一个利用学习过程来加速微光图像增强算法的工作。
定义了无监督训练损失来约束各阶段在自校准模块作用下的输出,赋予对不同场景的适应能力。属性分析表明,SCI 具有操作不敏感的适应性和模型无关的通用性,这是现有研究中没有的。
大量的实验,以说明我们相对于其他先进方法的优越性。并在黑脸检测和夜间语义分割方面进行了应用,显示了本文的实用价值。简而言之,SCI 在基于网络的微光图像增强领域重新定义了视觉质量、计算效率和下游任务性能的峰值点。
Method
1. Illumination Learning with Weight Sharing
根据 Retinex 理论,弱光观测的图像 y 与想要得到的清晰图像 z 之间存在关联:y = z ⊗ x,其中 x代表光照分量。照明通常被视为核心成份,在弱光图像增强中需要主要进行优化。根据 Retinex 理论,通过去除估计的光照,进一步获得增强的输出。
在这里,受 [8,14] 中提出的照明阶段优化过程的启发,通过引入一个带参数 θ 的映射 H_θ 来学习照明,本文提供了一个渐进的视角来建模这个任务,基本单元写为

其中 u^t 和 x^t 表示第 t 阶段的残差项(residual term)和光照(illumination) (t = 0,…), T−1)。需要注意的是,本文没有在 中标记阶段数,因为本文采用了权值共享机制,即在每个阶段使用相同的结构 H 和权值 θ。
H_θ 是通过网络实现的。见最后附的代码。
[8] Lime: Low-light im-age enhancement via illumination map estimation (2017 TIP).
[14] Retinex-inspired unrolling with cooperative priorarchitecture search for low-light image enhancement (2021 CVPR).
事实上,参数化算子 H_θ 学习了光照和弱光观测之间的一个简单的残差表示 u^t。这一过程的灵感来自于一个共识 (consensus),即光照和弱光观测在大多数地区是相似的或存在线性联系。与采用弱光观测和光照之间的直接映射相比,学习残差表示大大降低了保证性能(guarantee performance)和提高稳定性(steadiness)的计算难度,特别是曝光控制。
事实上,可以在给定训练损失和数据的情况下,直接利用上述构建的过程来获得增强模型。但值得注意的是,具有多个权值共享块的级联机制(cascaded mechanism)不可避免地会带来可预见的推理代价(gives a rise to foreseeable inference cost)。
回顾这个共享过程,每个共享块期望输出一个尽可能接近预期目标的结果。
进一步说(Going a step further),理想的情况是第一个块可以输出所需的结果,满足任务需求。同时,后一个块输出与第一个块类似,甚至完全相同的结果。这样,在测试阶段,只需要一个单独的块来加速推理速度。
接下来,将探讨如何实现它。
2. Self-Calibrated Module
根据上述分析,现在的目标是定义一个模块,使每个阶段的结果收敛到同一状态。
我们知道,每一阶段的输入都源于前一阶段,第一阶段的输入肯定被定义为弱光观测。
一个直观的想法是,是否可以将各阶段 (除了第一阶段) 的输入与弱光观测 (即第一阶段的输入) 连接起来,间接探索各阶段之间的收敛行为。
为此,引入了一种自校准的 map s,并将其添加到弱光观测中,以显示每个阶段的输入与第一阶段的差异。即,自校准模块可以表示为

其中 t≥1, v^t 是每个阶段转换后的输入, 是引入的参数化操作符, ϑ 参数可学习。则第 t 阶段 (t≥1) 的基本单位换算为
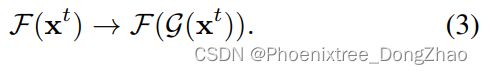
图 2 显示 SCI 框架 总体流程图。
K_ϑ 网络结构参考最后附的代码。
实际上,构建的自校准模块通过整合物理原理,逐步校正各级的输入,间接影响各级的输出。为了评估自校准模块对收敛的影响,在图 3 中绘制了各阶段结果之间的 t-SNE 分布,可以很容易地看到,每个阶段的结果确实收敛到相同的值。但是这种现象在没有自校准模块的情况下是无法实现的。
此外,上述结论也反映了此设计确实实现了上节最后一段所述的意图,即使用权值共享模式训练多个级联块,但只使用单个块进行测试。
Figure 2. The entire framework of SCI. In the training phase, our SCI is composed of the illumination estimation and self-calibrated module. The self-calibrated module map is added to the original low-light input as the input of the illumination estimation at the next stage. Note that these two modules are respectively shared parameters in the whole training procedure. In the testing phase, we just utilize a single illumination estimation module.
Figure 3. Comparing t-SNE [21] distributions in terms of the results of each stage on whether using self-calibrated module. It exhibits why we can use a single stage for testing, that is, the results of each stage in SCI can rapidly converge to the same value, but w/o self-calibrated module cannot realize it all the time.


3. Unsupervised Training Loss
考虑到已有配对数据的不准确性,本文采用无监督学习来扩大网络的能力。
定义总损失为 Ltotal = αLf + βLs,其中 Lf 和 Ls 分别表示保真和平滑损失。α 和 β 是两个正的平衡参数。
保真度损失是为了保证估计光照与各阶段输入之间的像素级一致性,公式为

其中 T 为总阶段数。实际上,该函数利用重新定义的输入 y + s^{t−1} 来约束输出光照 x^t
,而不是 hand-crafted 的 ground truth 或普通的低光输入。
光照的平滑性在这个任务中是一个广泛的共识 [7,34]。这里采用具有空间变量的1范数 [4] 的平滑项,表示为

其中 N 为像素总数。i 是第 i 个像素。
N (i) 表示 i 在其 5 × 5 窗口中的相邻像素。Wi,j 表示权重,其公式形式为 
其中 c 为 YUV 颜色空间中的图像通道。σ = 0.1 是高斯核的标准差。
本质上,自校准模块在学习更好的基本块 (本工作中的照明估计块) 时起到辅助作用,通过权值共享机制,将基本块级联生成整体照明学习过程。更重要的是,自校准模块使各个阶段的结果趋于一致,这在现有的工作中还没有进行过探索。
此外,SCI 的核心思想实际上是引入额外的网络模块来辅助训练,而不是在测试中。
改进模型表征,实现只使用单个块进行测试。也就是说, “权重分担+任务相关自校准模块” 的机理可能被调去处理其他加速任务。
Algorithmic Properties
1. Operation-Insensitive Adaptability
一般来说,基于网络的方法所使用的操作是固定的,不能随意更改,因为这些操作是在大量实验的支持下获得的。幸运的是,本文提出的算法对 H_θ 的不同非常简单甚至幼稚的设置具有惊人的适应性(adaptability)。
如表 1 所示,可以很容易地观察到,本文的方法在不同的设置 (block 3x3 convolution+ReLU 的数量) 中获得了稳定的性能。

Table 1. Quantitative comparison among different settings for Hθ on MIT testing dataset. In which, the basic block contains a convolutional layer with the size of 3×3 and a ReLU layer. “Blocks” and “Channels” represent the numbers of the basic block and the variation of channels in the basic block, respectively.
此外,在图 4 中展示了视觉对比,可以很容易地观察到,SCI 在不同的设置下都使弱光观测变亮,显示出非常相似的增强结果。
Figure 4. Visual comparison among different cases in Table 1.

重新审视本文设计的框架,拥有这一特性的原因在于,SCI 不仅转换了照明的共识 (即残差学习),而且集成了物理原理 (即像素级除法操作)。
2. Model-Irrelevant Generality
SCI 实际上是一个广义的学习范式,如果不限制与任务相关的自校准模块,所以理想情况下,它可以直接应用于现有的工作。
这里,以最近提出的代表性工作 RUAS[14] 为例进行探讨。
表 2 和图 5 展示了使用 SCI 训练 RUAS 前后的定量和定性比较。
Table 2. SCI can be applied to improve the performance for existing works, e.g., RUAS [14]. In which RUAS (d) represents adopting d iterative blocks for the unrolling process appeared in RUAS. Here we adopt the LSRW [9] dataset for testing.
Figure 5. Visual comparison among different cases in Table 2.


结果显示,虽然只是利用了 RUAS 展开过程中使用的单个块 (即 RUAS(1)) 来评估本文的训练过程,但性能仍然得到了显著的提高。
更重要的是,本文的方法可以显著抑制原始 RUAS 中出现的过度曝光。
这个实验反映了本文学习框架确实足够灵活,具有很强的与模型无关的通用性。
这也表明,本文的方法也许可以应用到任意光照下的微光图像增强工作中。
官方代码
https://github.com/vis-opt-group/SCI/blob/main/model.py
import torch
import torch.nn as nn
from loss import LossFunction
class EnhanceNetwork(nn.Module):
def __init__(self, layers, channels):
super(EnhanceNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.ReLU()
)
self.conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.conv)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
illu = fea + input
illu = torch.clamp(illu, 0.0001, 1)
return illu
class CalibrateNetwork(nn.Module):
def __init__(self, layers, channels):
super(CalibrateNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.layers = layers
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.convs = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.convs)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
delta = input - fea
return delta
class Network(nn.Module):
def __init__(self, stage=3):
super(Network, self).__init__()
self.stage = stage
self.enhance = EnhanceNetwork(layers=1, channels=3)
self.calibrate = CalibrateNetwork(layers=3, channels=16)
self._criterion = LossFunction()
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
ilist, rlist, inlist, attlist = [], [], [], []
input_op = input
for i in range(self.stage):
inlist.append(input_op)
i = self.enhance(input_op)
r = input / i
r = torch.clamp(r, 0, 1)
att = self.calibrate(r)
input_op = input + att
ilist.append(i)
rlist.append(r)
attlist.append(torch.abs(att))
return ilist, rlist, inlist, attlist
def _loss(self, input):
i_list, en_list, in_list, _ = self(input)
loss = 0
for i in range(self.stage):
loss += self._criterion(in_list[i], i_list[i])
return loss
class Finetunemodel(nn.Module):
def __init__(self, weights):
super(Finetunemodel, self).__init__()
self.enhance = EnhanceNetwork(layers=1, channels=3)
self._criterion = LossFunction()
base_weights = torch.load(weights)
pretrained_dict = base_weights
model_dict = self.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
self.load_state_dict(model_dict)
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
i = self.enhance(input)
r = input / i
r = torch.clamp(r, 0, 1)
return i, r
def _loss(self, input):
i, r = self(input)
loss = self._criterion(input, i)
return loss