解析深度学习中各类目标检测模型的发展沿革与功能特性
本文其实和笔者近期发表的其他文章同属robomaster学习过程中的经验分享,不过笔者希望主线里面的Ubuntu和ROS要素不被冲淡,所以并未归纳进去。这里主要介绍的是从13年开始逐渐兴起的目标检测模型到目前为止的发展历程以及其中一些关键模型的参数对比与优化分析。
发展沿革
从2013年11月R-CNN石破天惊横空出世以来,目标检测领域可谓是百家争鸣,各显神通,无论是先fast后faster不知什么时候会fastest的CNN家族,还是你写v4他写v5我写v6的YOLO大合唱,都在深度学习史上留下了浓墨重彩的一笔,这里有张图表能够清晰地反映出该发展过程,可惜作者只列出了到20年8月为止的目标检测模型,在后文中笔者会补充一些新兴的目标检测模型。

图像来源:deep_learning_object_detection_history.PNG (1227×621) (raw.githubusercontent.com)
模型特征
这里开始笔者会介绍各个模型的设计思路以及其优劣性,大家可以根据这些内容横向对比,选择自己心仪的模型。
开山鼻祖(R-CNN)
全称是Region-CNN,基于卷积神经网络(CNN),线性回归(LR)以及支持向量机(SVM)等算法从而目标检测技术。
数据处理
首先我们需要一些图片作为数据集,然后从这些图片身上提取出一系列的特征来训练模型。此前普遍通用的是滑动窗法,即在原始图片上进行不同尺度不同大小的滑窗选框,从而获取每个可能的位置。而这样做的缺点显而易见,繁杂并且产生了很多的冗余区域,而且由于无法兼顾每一个尺度,因此得到的目标位置精度也存在一定的问题。这里我们采用了一种更为科学先进的方法——选择性搜索。首先将图像分割为千数量级的小区域,之后计算所有邻近区域之间的相似性,包括颜色、纹理、尺度等,再将相似度比较高的区域合并到一起,之后计算新合并区域和临近区域的相似度继续合并,直到整张图片被合并为一个区域。在这个过程中,不同大小、经历过不同次数迭代的区域被统称为Region proposals,即候选区域,这些区域约有两千个,可以为模型提供图像特征。

具体代码实现可以参考如下链接http://t.csdn.cn/gPlou
之后我们通过卷积神经网络(CNN)对VOC测试集中每张输入图像上搜索到的2000个Region proposals提取特征,但是这些候选区域大小需要统一为AlexNet要求的227X227,所以需要对其进行resize操作来实现统一。这里为了特征突出和模型优化可以采取参数微调,微调方式可以参考如下链接http://t.csdn.cn/r4BsW
模型训练
CNN经过了预训练和微调后不再进行训练,就会单纯作为一个提取特征的工具而保持不变了。虽然我们训练了CNN对region proposal进行分类,但是实际中,这个CNN的作用只是提取每个region proposal的feature,之后的分类工作是依靠支持向量机(SVM)来完成的。之所以用到机器学习的SVM,而不用CNN,是因为VOC的数据样本较少,SVM在小样本训练中效果更为出众。
使用SVM进行分类时,对于每一类都会训练一个SVM分类器,所以分类器的数量取决于类别数量。在SVM分类过程中,参数IoU<0.3被作为负例,IoU>0.7时是正例,被认为是完全框住了物体,称之为ground truth,其余的数据全部丢弃。然后SVM分类器也会输出一个预测的labels,然后用labels和truth labels比较,计算出loss,然后训练SVM。
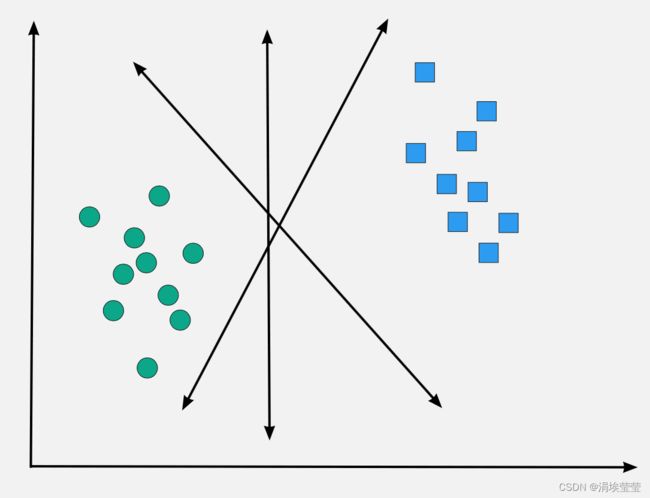
此处对交并比(IoU)做一个解释,这里用到了非极大值抑制(NMS)的一个概念,非极大值抑制也可说成是局部最大搜索,用于确保算法对每个对象只检测一次,避免冗余的检测框,而IoU是其中的一个参数,就是用来度量目标检测中预测框与真实框的重叠程度,数值上IoU=A∩B/A∪B,可以作为loss函数来使用。
有一点需要说明,SVM由于是小样本训练,所以可能会出现负样本远多于正样本的情况。针对这种情况,作者使用了难例挖掘(hard negative mining)的方法,即初始时用所有样本训练,经过一轮训练后将score最高(最容易被误判)的负样本加入新的样本训练集,进行训练,重复以上步骤至达到停止条件如分类器性能不再提升,使得SVM适用于小样本训练,这样在样本不平衡时依然可以保证可靠性而不会发生过拟合。
回归优化
下一步是边框回归(Bounding box regression),请看下图,红色的框是使用选择性搜索(SS算法)提取出的region proposal,绿色的框是ground truth。虽然图中红色的框被分类器识别为飞机,但是由于红色框的定位不准(IoU<0.5),还是相当于没有正确检测出飞机。所以为了使定位更准确,使得region proposal更接近于ground truth,我们需要对红色的框进行微调,方法就是边框回归。

下图中,绿色的窗口P为region proposal,黄色的窗口G为ground truth,bounding box regression的目标就是:找到一种映射关系,使P经过映射后会得到一个和G比较接近的 ![]() 。
。

具体代码可以参照这篇专栏【目标检测】Bounding box regression 知乎 https://zhuanlan.zhihu.com/p/60794316
优劣汇总
训练完成后,按照上述步骤将测试集放入训练好的模型即可进行测试。由于是第一代目标检测算法,不足之处还是有很多的。训练时间长且步骤繁琐,占用过多的硬盘容量,还有精度问题,数据样本问题等。但是不管怎样,他都开创了目标检测模型的先河,超越了传统的机器学习模型,值得我们每一个后继者发自内心的尊敬。
原本是想把近期学过的模型都说一说,但是篇幅可能太长了,之后的模型就暂且放在下一篇博客吧。感谢大家的阅读,希望能够有所帮助。