【学习打卡】可解释机器学习之导论
可解释机器学习之导论
文章目录
- 可解释机器学习之导论
-
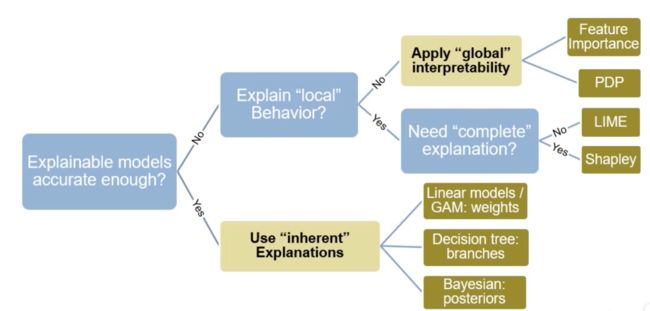
- 可解释学习
- 为什么我们需要可解释机器学习
- 前沿的AI方向
- 可解释性好的机器学习算法
- 深度学习的可解释性分析
-
- 可视化卷积核
- 遮挡Mask、缩放、平移、旋转
- 找到能使某个神经元激活的原图像素,或者小图
- 基于类激活热力图(CAM)的可视化
- 语义编码降维可视化
- 生成符合要求的图像
- 扩展阅读
- 思考题
- 总结
首先非常感谢同济子豪兄拍摄的可解释机器学习公开课,并且免费分享,这门课程,包含人工智能可解释性、显著性分析领域的导论、算法综述、经典论文精读、代码实战、前沿讲座。由B站知名人工智能科普UP主“同济子豪兄”主讲。 课程主页:
https://github.com/TommyZihao/zihao_course/blob/main/XAI 一起打开AI的黑盒子,洞悉AI的脑回路和注意力,解释它、了解它、改进它,进而信赖它。知其然,也知其所以然。这里给出链接,倡导大家一起学习,别忘了给子豪兄点个关注哦。
学习GitHub 内容链接:
https://github.com/TommyZihao/zihao_course/tree/main/XAI
B站视频合集链接:
https://space.bilibili.com/1900783/channel/collectiondetail?sid=713364
可解释学习
在机器学习逐渐黑盒化的情况下,人们对模型的可解释性也提出了要求。可解释人工智能(XAI)被列为数据和分析技术领域的top10重要趋势之一。在2017年,美国国防部开展了XAI计划;在2018年,欧洲强调对可解释机器学习的需求。此外,谷歌微软等公司也开展对可解释机器学习相关技术的研究。

为什么我们需要可解释机器学习
从多个方面可知,我们需要可解释机器学习:
- 社会对AI的依赖性(无人驾驶、安全、金融)。这是因为我们的社会比起以往任何时候都更依赖人工智能,这促使我们很需要了解模型。比如说,如果无人驾驶过程中出现事故,那我们应该能过瞄准哪些部件出错,或者哪些部门应该为这次事故买单。
- 用户需要可解释性增强信任。从用户的角度来说,用户需要明白这些决策的后果,如果说数据会用用户的私人信息,那对用户而言这是一件很恐惧的事情。
- 监管机构需要可解释性。对于可能会违反规则的公司,比如说泄漏内幕信息,我们应该能够发现。
- 模型设计者需要解释去调试模型。
- 解释方法有助于科学知识发现,在医学、生态学等诸多领域中可解释性发挥重要作用。
在可解释机器学习和可解释性的领域中,还有一些经典案例,有助于理解可解释性和可解释机器学习的重要性:
- 哮喘和肺炎的案例。由于神经网络的错误无法解释,导致神经网络模型无法用于临床试验。
- 在狼和狗的图像分类中,解释发现模型使用背景中的雪作为区分的特征,而不是动物本身。
- 金融部门发现将id作为最重要的特征。
从以上的介绍我们可以看出,我们其实是很需要可解释机器学习的,他能给我们带来安心,可以给我们带来很多的东西,这也是一个非常重要的领域,可信AI也就在做相关的事情,所以我们也需要打开黑盒子去学习。
除了以上说的有关于社会的来说,作为学生在学习的时候,我们其实很喜欢问为什么,我们不希望在学习的过程中,即使自己跑出一个代码,但是别人问你怎么做的,为什么这样做却一句话也说不出来,只能说一句我用库的,或者说是神经网络可解释性太差了,或者说我不会解释,在顶会论文中,我们时常会发现,有些时候会讲故事,会解释,你就很有机会被选上,所以我们为什么要学习可解释性机器学习呢,子豪兄给我们列了以下几点,我觉得是非常有道理的。
- 研究AI的脑回路,就是研究AI的本质
- 可解释分析是机器学习和数据挖掘的通用研究方法
- 和所有AI方向交叉融合: 数据挖掘、计算机视觉、自然语言处理、强化学习、知识图谱、联邦学习。
- 包括但不限于:大模型、弱监督、缺陷异常检测、细粒度分类、决策AI和强化学习、图神经网络、AI纠偏、A14Science、MachineTeaching、对抗样本、可信计算、联邦学习。
前沿的AI方向
子豪兄说了几个,第一个其实就是我们的chatGPT,其实chatGPT我也玩过,确实很聪明,并且他能够给我们写代码甚至可以教我们写代码,是非常非常聪明的,但同样,他的可解释性分析也是值得讨论的,我觉得这个也是非常make sense的一件事情
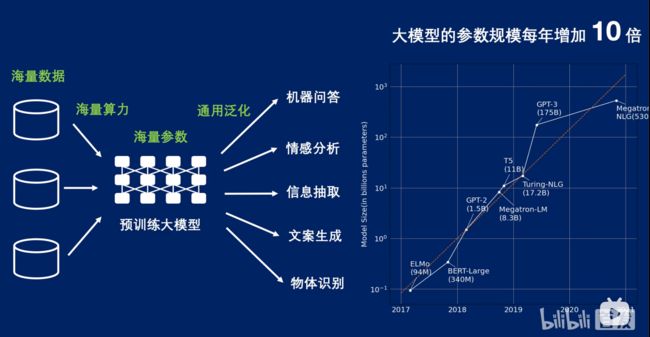
除此之外,以及还有AI画图,也就是发展飞快的stable diffusion模型,也是大放光彩,同时近年来,我们会发现,大模型的参数规模每年增加10倍,比摩尔定律还快,这可能也是未来的一个趋势,海量数据利用海量算力预训练大模型,在某一方面,我们很难像大厂一样有这么多的资源,所以有时候我们更加需要学习到一些知识,可以尝试对其进行可解释分析和学习。
可解释性好的机器学习算法
实际上,在当下来说,解释性最好的就是机器学习算法,因为他们是直观且可以用数学公式表达的,比如KNN来说,理论上我们更近,说明很有可能在同一类别。
在决策树中,他的思想实际上很类似于一个人类的思想,通过if elif elif的思想,并且我们可以可视化出决策树,我们可以看到每一个特征的意思,比如小于多少岁的容易或乳腺癌等等,这样的方法是非常有意义的,也是有迹可循的。
- KNN
- Logistics Regression
- 线性回归
- 决策树
- 朴素贝叶斯
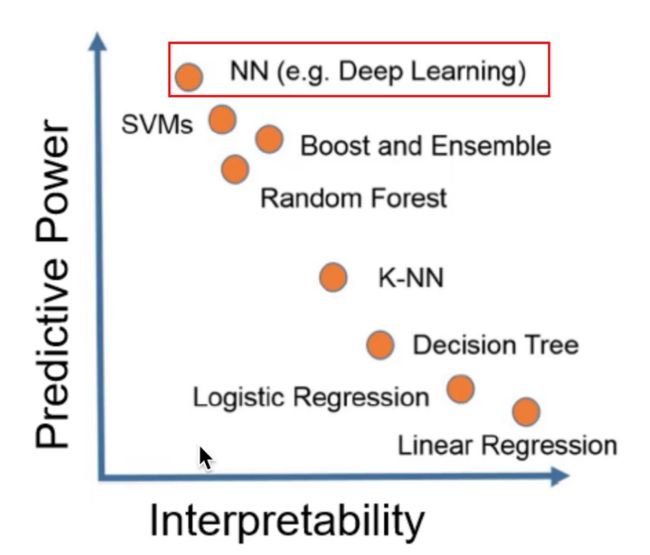
从下图我们也可以看出,虽然说神经网络的拟合能力是最好的,但是可解释性是最差的,而其他像线性回归,虽然拟合能力很差,但是可解释性是最好的,所以我认为对于神经网络去研究可解释性是非常有意义的
在进行可解释分析的时候,我们也可以根据以下流程进行,具体的方法,可以看视频的最后一部分的综述方法。
深度学习的可解释性分析
比如对于卷积神经网络来说,有几种可解释性的方法,这些是非常有趣和有前景的
- 可视化卷积核、特征图
- 遮挡Mask、缩放、平移、旋转
- 找到能使某个神经元激活的原图像素,或者小图
- 基于类激活热力图(CAM) 的可视化
- 语义编码降维可视化
- 由语义编码倒推输入的原图
- 生成满足某些要求的图像 (某类别预测概率最大)
可视化卷积核
每个卷积核提取不同的特征每个卷积核对输入进行卷积,生成一个feature map这个feature map即提现了该卷积核从输入中提取的特征
不同的feature map显示了图像中不同的特征
- 浅层卷积核提取: 边缘、颜色、斑块等底层像素特征
- 中层卷积核提取:条纹、纹路、形状等中层纹理特征
- 高层卷积核提取:眼睛、轮胎、文字等高层语义特征
- 最后的分类输出层输出最抽象的分类结果
其实在早早的AlexNet的论文中,也有可视化出卷积核,不过由于卷积核不好理解,并且通道数很多,所以就比较麻烦,后续的层其实已经不是人类所理解的,所以一般可视化的是浅层的卷积核,类似于下面的Gabor滤波器的结果和方法。
遮挡Mask、缩放、平移、旋转
在2013年的ZFNet中就用了这样的方法,以下的图片和方法,都在子豪兄的ZFNet的精读中有介绍和详细解释。
比如说遮挡,其实思想很简单,类似于在机器学习中去掉一列特征后查看结果一样,在图像中可以mask掉一块,然后查看预测的结果是否有改变,如果改变的较大,说明这一部分的信息是非常重要的,神经网络查看的主要就是这一部分的信息。
同理,我们也可以通过缩放,平移,旋转等方法。
找到能使某个神经元激活的原图像素,或者小图
其实思想还是蛮简单的,这里面用到了反卷积的方式,利用反卷积进行从卷积核得到我们的小图,从中查看神经元激活的原图像素,这样我们就可以看到神经网络关注的特征,比如浅层关注的是一些颜色的特征,这样我们就可以很容易可以看得出来了
基于类激活热力图(CAM)的可视化
对于热力图的可视化来说,是非常有趣的,我们可以看到神经网络眼中的图像,比如对于下图的牧羊犬来说,我们可以看到神经网络主要关注的是牧羊犬的主体,而不是关注周围的环境,这样就给了我们一个比较好的解释。
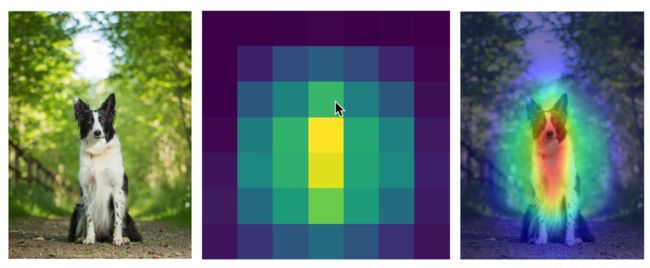
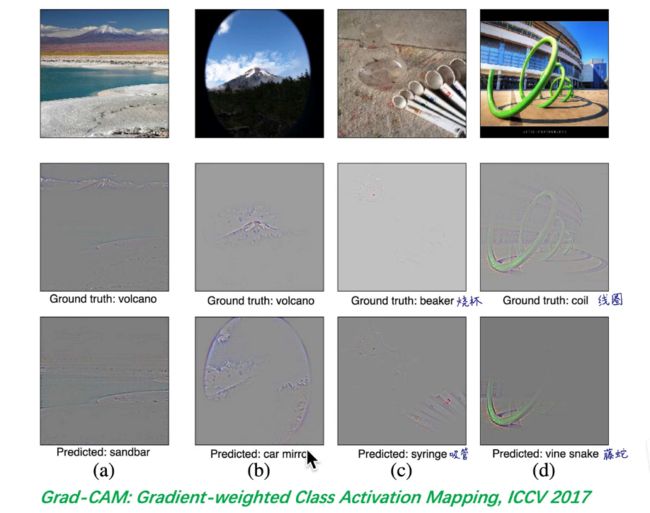
经过2016的GAM开始,现在也有很多比如Grad-CAM,Grad-CAM++等等,这类可解释的出现是非常有意义,我认为是make sense的,因为他不仅可以解释正确分类的任务,他同时也可以解释错误分类的原因,在视频中,子豪兄给出了一个样例。
在下图我们可以看到,正确的类别和错误类别的图是不同的,比如在第四张图线圈中,正确的图中是对整一块进行判断,而预测出来的图只对一部分进行了判断,这一部分类似与蟒蛇,所以就认为是蟒蛇;除此之外,第三张图也是,为什么会预测成吸管,是因为他关注了勺子中的下半部分,所以很像吸管,最后预测成吸管了,我觉得还是非常有意思的。
语义编码降维可视化
我觉得这是非常有意义的,这个是做什么呢,实际上就是将语义信息降维,降维到二维或者三维空间上可视化,从中我们可以发现他们的关系,比如同一种水果的语义是相近的,以及不同的类别,并且子豪兄也在后续给出了这个代码,可以根据这个代码在自己的图像分类任务中进行可视化。
https://github.com/TommyZihao/Train_Custom_Dataset/图像分类
生成符合要求的图像
这里讲解到了一个对抗样本的问题,我在之前也做过这个对抗样本的实验,是利用mnist数据集和LeNet进行的,有兴趣的可以看看,
GAN 系列的探索与pytorch实现 (数字对抗样本生成)。
在深度学习中,有许多类型的对抗性攻击,每一类攻击都有不同的目标和对攻击者知识的假设。然而,总的目标是在输入数据中添加最少的扰动,以导致所需的错误分类。攻击者的知识有几种假设,其中两种是:白盒和黑盒。
白盒攻击假定攻击者具有对模型的全部知识和访问权,包括体系结构、输入、输出和权重。黑盒攻击假设攻击者只访问模型的输入和输出,对底层架构或权重一无所知。目标也有几种类型,包括错误分类和源/目标错误分类。错误分类的目标意味着对手只希望输出分类是错误的,而不关心新的分类是什么。源/目标错误分类意味着对手想要更改原来属于特定源类的图像,以便将其分类为特定的目标类。
下面的图片就是一种快速梯度符号攻击,加了一部分噪声后,我们会发现,虽然人的判断还是正确的,但是人工智能的判断已经把pandas分类为gibbon长臂猿了。
当讲到这个的时候,我就联想到可信AI了,可信AI也是要做这种对抗的信息安全的问题,比如可信AI-稳定性:人工智能系统抵抗恶意攻击或者环境噪声并且能够做出正确决策的能力,这个就是类似于上面的噪声攻击,即使遇到这种噪声,可信AI希望还是能够得到不错的结果或者说正确的结果,而不是在被攻击后,这个网络就完全失效,完全不安全了,因为后续还涉及到有关于一些用户隐私的问题,所以我们需要保证他的安全。

扩展阅读
首先是子豪兄出品的一个代码,从中可以学习到很多东西
https://github.com/TommyZihao/Train_Custom_Dataset/图像分类
其次还有pytorch的一个库,里面包含了很多很多可解释性分析
https://github.com/utkuozbulak/pytorch-cnn-visualizations
以及最后还有子豪兄做的一个论文的收集,在他的Readpaper里面都有给出来
https://readpaper.com/user/collect/638623946528292864
还有就是推广一下openmml的一个类激活热力图的可视化工具,方便我们进行可视化
这个可以在公众号 OpenMMLab 回复 CAM
思考题
- 为什么要对机器学习、深度学习模型做可解释性分析和显著性分析 ?
- 如何回答“人工智能黑箱子灵魂之问” ?
- 人工智能的可解释性分析有哪些应用场景?
- 哪些机器学习算法本身可解释性就好?为什么?
- 对计算机视觉、自然语言处理、知识图谱、强化学习,分别如何做可解释性分析?
- 在你自己的研究领域和行业,如何使用可解释性分析?
- 可以从哪几个角度实现可解释性分析 ?
- Machine Teaching有哪些应用场景 ?
总结
学习了一部分可解释机器学习的导论内容,感觉是非常不错的,顺便也回答一下思考题的几个问题和自己的理解吧
首先为什么要进行可解释性分析,这个问题实际上上面已经写了,我觉得往大了说,实际上这对整个社会都是有意义的,往小了说,这是一个很好的方法和一个很好的解释性的方法,可以帮助我们发论文和进行研究。我所了解的可信AI就有一部分人在做这样的事情,并且近几年,我认为可信AI的发展也是一个热点,所以这也回答了第三个问题哈哈哈,可解释分析也可以用于可信AI中,并且在很多领域,可解释性好的算法更容易让其他人进行接受。
我认为第五个问题和第六个问题是非常有意义的,在视频中,我们大多数看到的实际上是对计算机视觉进行可解释分析的,但是如果对NLP领域以及RL领域,甚至是推荐算法领域做可解释性分析呢,甚至在自己的研究领域和行业,我觉得这是一个值得思索的原因,我希望的方向是这样的,多问为什么,然后尝试解决他,知其然还要知其所以然,这样子,我们的论文也会越来越好,看问题和领域也会越来越通透了,这样也更助于我们将可解释性好的算法真正应用在比如医疗领域,金融领域中去,这样可以让AI真正的贴近生活,真正的走进我们的生活,并且能够让我们相信他。