Torch_5_LSTM 探究一下模型定义与输入数据的参数设置
CNN跳了
数据流

在传统RNN的基础之上,通过设置cell对以往状态的遗忘程度,使模型更好的拟合数据。
在数据流中,定义了 I 、 F 、 O I、F、O I、F、O和 C ~ \tilde{\mathbf{C}} C~,有
I t = σ ( X t W x i + H t − 1 W h i + b i ) , F t = σ ( X t W x f + H t − 1 W h f + b f ) , O t = σ ( X t W x o + H t − 1 W h o + b o ) , C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) , \begin{aligned} \mathbf{I}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i),\\ \mathbf{F}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f),\\ \mathbf{O}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o),\\ \tilde{\mathbf{C}}_t &= \text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1} \mathbf{W}_{hc} + \mathbf{b}_c),\\ \end{aligned} ItFtOtC~t=σ(XtWxi+Ht−1Whi+bi),=σ(XtWxf+Ht−1Whf+bf),=σ(XtWxo+Ht−1Who+bo),=tanh(XtWxc+Ht−1Whc+bc),
通过 I I I控制当前输入对状态的影响,通过 F F F控制之前状态的影响, O O O来控制隐藏状态 H t H_t Ht。表示为
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t . H t = O t ⊙ tanh ( C t ) . \mathbf{C}_t = \mathbf{F}_t \odot \mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t.\\ \mathbf{H}_t = \mathbf{O}_t \odot \tanh(\mathbf{C}_t). Ct=Ft⊙Ct−1+It⊙C~t.Ht=Ot⊙tanh(Ct).
模型定义
import torch
lstm = torch.nn.LSTM(input_size=28, hidden_size=256, num_layers=1)
其中
input_size为输入 x t x_t xt中的那个 t t t,表示输入层的 c e l l cell cell数量hidden_size为隐藏层的大小,表示单个 c e l l cell cell内 H t H_t Ht的复杂程度num_layers为网络层数,用于构建深层LSTM
模型输入
输入有两个部分,inputs和(h_0, c_0)
inputs 的形状应为 ( s e q u e n c e _ l e n g t h , b a t c h _ s i z e , i n p u t _ s i z e ) (sequence\_length, batch\_size, input\_size) (sequence_length,batch_size,input_size), 分别为
sequence_length,一次输入的序列长度,输入的大小。不需要和其他部分匹配,就是说可以随意修改而不会引起模型报错。batch_sizeinput_size,与模型定义中相同
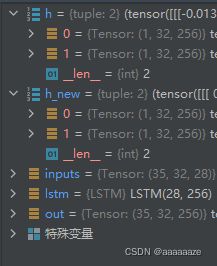
inputs = torch.randn(35, 32, 28)
(h_0, c_0)表示模型 H 0 H_0 H0和 C 0 C_0 C0的初始化参数,元组,省略时以 0 0 0替代。
它们的形状都应是 ( D ∗ n u m _ l a y e r s , b a t c h _ s i z e , h i d d e n _ s i z e ) (D∗num\_layers,batch\_size,hidden\_size) (D∗num_layers,batch_size,hidden_size)
D表示方向,双向LSTM为2,单向为1num_layers,batch_size,hidden_size与上述定义相同
h = (torch.randn(1, 32, 256),
torch.randn(1, 32, 256))
模型输出
输出也是两部分,output和(h_n, c_n)
output形状为 ( s e q u e n c e _ l e n g t h , b a t c h _ s i z e , D ∗ h i d d e n _ s i z e ) (sequence\_length,batch\_size,D∗hidden\_size ) (sequence_length,batch_size,D∗hidden_size)
上面都定义过了
(h_n, c_n)状态与(h_0, c_0)相同,只是表示计算结束后的隐藏状态
out, h_new = lstm(inputs)
可通过设置
lstm=nn.LSTM(*args, batch_first=True), 改变输入输出的形状顺序,将batch_size的位置从shape[1]改为shape[0]
真的绕腾