数据科学基础复习2
数据科学基础复习2
文章目录
- 数据科学基础复习2
-
- 统计学基本概念
-
- 4.1 总体与样本
- 4.2 参数估计
- 4.3 假设检验
- 4.4 方差分析*
- 4.5 回归分析*
- 凸优化
- 智能优化算法
-
- 遗传算法
- pso粒子群优化算法
- 机器学习初探
- 分类模型评估
-
- K折叠交叉验证(K-fold cross validation)
- 二分类问题
- 特征工程
-
- 数据预处理
- 特征提取
- 特征选择
- 特征降维
- 简答题
-
- (1)简述梯度下降法的关键步骤。
- (2)简述遗传算法中轮盘赌选择种群的方法。
- (3)简述粒子群算法中粒子更新关键步骤。
- (4)简述阶方阵的所有特征值与方阵的行列式和迹之间的关系。
- (5)简述极大似然估计算法
- (6)给出方阵的特征多项式定义
- (7)简述PCA关键计算步骤
- (8)简述C4.5算法中选取根节点的特征属性及处理连续属性值的关键步骤
- (9)请给出凸函数的定义。
- (10)简述K折交叉验证。
- (9)请给出凸函数的定义。
- (10)简述K折交叉验证。
统计学基本概念
4.1 总体与样本
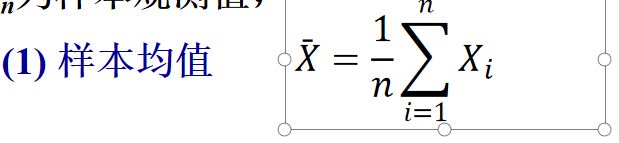

4.2 参数估计
矩估计
最大似然估计
步骤:(一)写出似然函数

(二)取对数


4.3 假设检验
4.4 方差分析*
4.5 回归分析*
凸优化
凸集:集合C内任意两点间的线段均在集合C内,则称集合C为凸集。
仿射集:
凸函数:



无约束优化
梯度下降法


优点:计算简单,需记忆的容量小;对初始点要求低,稳定性高;远离极小点时收敛快,常作为其它方法的第一步。
缺点:收敛速度较慢(线性或不高于线性)。原因是最速下降方向只有在该点附近有意义。
最速下降方向只是局部下降最快的方向,在全局来看,下降速度是比较慢的,尤其当函数等值面为很扁的椭圆、椭球。
智能优化算法
遗传算法

主要步骤:
1、对优化问题的解进行二进制编码,随机产生一个种群。一个解的编码称为一个染色体,组成编码的元素称为基因。
2、适应函数的构造和应用。自然选择规律是以适应函数值的大小决定的概率分布来确定哪些染色体适应生存,哪些被淘汰。
3、染色体的结合。通过复制和交叉实现。
4、变异。新解产生过程中可能发生基因变异,变异使某些解的编码发生变化,使解有更大的遍历性。
5、迭代若干代后得到适应值最大的个体即最优解。
 轮盘赌选择算法
轮盘赌选择算法


(1)群体搜索,易于并行化处理;
(2)不是盲目穷举,而是启发式搜索;
(3)适应度函数不受连续、可微等条件的约束,适用范围很广。
pso粒子群优化算法
每个寻优的问题解都被想像成一只鸟,称为“粒子”。所有粒子都在一个D维空间进行搜索。
所有的粒子都由一个fitness function 确定适应值以判断目前的位置好坏。
每一个粒子必须赋予记忆功能,能记住所搜寻到的最佳位置。
每一个粒子还有一个速度,以决定飞行的距离和方向。这个速度根据它本身的飞行经验以及同伴的飞行经验进行动态调整。
基本变量:
解空间为D维向量,表示粒子的位置,种群设定为N个粒子xi(i=1,2,…,N)。
粒子i位置:xi=(x_i1,x_i2,…,x_iD) ,将xi代入适应函数f(xi)计算适应值;
粒子i速度: v_i=(v_i1,v_i2,…,v_iD)
粒子i自身经历过的最好位置:pbesti=(p_i1,p_i2,…,p_iD)
种群全体粒子所经历过的最好位置:gbest=(g1,g2,…,g_D)

w=1,基本粒子群算法;w=0,失去对粒子本身的速度的记忆
c_1=0,无私型粒子群算法,“只有社会,没有自我”,迅速丧失群体多样性,易陷入局优而无法跳出.
c_2=0,自我认知型粒子群算法,“只有自我,没有社会”,完全没有信息的社会共享,导致算法收敛速度缓慢
c_1, c_2都不为0,称为 完全型粒子群算法
完全型粒子群算法更容易保持收敛速度和搜索效果的均衡,是较好的选择.
第1步: 设置相关参数, 在初始化范围内, 对粒子群进行随机初始化, 包括随机位置和速度
第2步: 计算每个粒子的适应值
第3步: 更新粒子的个体历史最好值和最好解以及整个群体的历史最好值和最好解
第4步: 对粒子的速度和位置进行更新.
机器学习初探
数据挖掘的三大基本任务:分类预测、聚类分析、关联规则
决策树算法
ID3:采用信息增益
掌握信息熵概念
能够计算信息增益
C4.5:采用信息增益比,能处理连续值属性
CART:采用Gini指数,包括分类树和回归树
信息熵:I(a_i)=p(a_i)log_21/p(a_i)
当数据变得越加纯净时,熵变得越小。事实可以证明,当正例(0.5)与 负例(0.5)相当时,熵取最大值。当D 中所有数据都只属于一个类时,熵取最小值,为0。
二元熵函数: H§=I(p,1−p)= −plogp−(1−p)log(1−p)
熵的最值:logC, 其中C为数据集D中类标号数目

Gain(A)越大,说明选择测试属性对分类提供的信息越多
D3算法只能处理离散值的属性。
信息增益度量存在一个内在偏置,它偏袒具有较多值的属性。
例如,如果有一个属性为日期,那么将有大量取值,这个属性可能会有非常高的信息增益。
假如它被选作树的根结点的决策属性则可能形成一颗非常宽的树,这棵树可以理想地分类训练数据,但是对于测试数据的分类性能可能会相当差。


分类模型评估
K折叠交叉验证(K-fold cross validation)
将初始采样分割成K个子样本(S1,S2,…,Sk),取K-1个做训练集,另外一个做测试集。交叉验证重复K次,每个子样本都作为测试集一次,平均K次的结果,最终得到一个单一估测。
当K=n(样本总量),即为留一验证(Leave-one-out Cross Validation)
二分类问题
真阳性(True Positive, TP): 实际为阳性 预测为阳性
真阴性(True Negative, TN):实际为阴性 预测为阴性
假阳性(False Positive, FP): 实际为阴性 预测为阳性
假阴性(False Negative, FN):实际为阳性 预测为阴性
混淆矩阵

性能指标
灵敏度(Sensitivity)也称查全率(Recall): TP/(TP+FN)
特异度(Specificity): TN/(TN+FP)
精度(Precision): TP/(TP+FP)
准确率(Accuracy): (TP+TN)/(TP+TN+FN+FP)

特征工程
数据预处理
数据清洗:格式内容清洗、逻辑错误清洗、异常值清洗以及缺失值清洗。
数据集成
数据变换
数据归约
特征归一化
类别型特征的处理方式
在对数据进行预处理时,处理类别型特征常用的方式为:
序号编码(Ordinal Encoding)
独热编码(One-hot Encoding)
二进制编码(Binary Encoding)
特征提取
特征提取和特征选择的相似点在于,二者达到的目标一致,即试图去减少特征的数目。但二者采取的方式却不同。
特征选择是从原始特征集中选择出子集,没有更改原始的特征空间;
而特征提取主要是通过属性间的关系,如组合不同的属性得到新的属性,这样会改变原有的特征空间。
特征提取与降维有关。降维的意义在于克服维数灾难、获取本质特征、节省存储空间以及去除无用噪声等。
特征提取的常用方法主要包含:
主成分分析(PCA)
PCA的思想
主成分,顾名思义,就是找出数据里最为主要的方面(或方向),用数据里这些最为主要的方面代替原始数据
线性判别分析(LDA)
潜在语义索引(LSI)
特征选择
Filter(过滤法):按照发散性或相关性对各个特征进行评分,设定阈值或者待选择特征的个数进行筛选
Pearson相关系数
卡方检验
利用卡方分布进行假设检验,用于特征与分类目标的独立性检验。如果检验结果为某个特征与标签独立,则可以删除该特征
信息增益比、Gini指数
互信息
最大信息系数(maximum information coefficient,MIC)
Wrapper(包装法):结合学习算法,根据目标函数(往往是预测效果评分),每次选择若干特征,或者排除若干特征
Embedded(嵌入法):先使用某些机器学习的模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征(类似于Filter,只不过系数是通过训练得来的)
特征降维
PCA降维
主成分,顾名思义,就是找出数据里最为主要的方面(或方向),用数据里这些最为主要的方面代替原始数据
步骤:

去中心化(把坐标远点放在数据中心)
找坐标系(找到方差最大的方向)
数据线性变化:

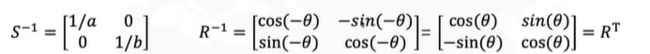
现有数据协方差矩阵的特征向量就是R

![]()

协方差的特征向量

 R矩阵
R矩阵
简答题
(1)简述梯度下降法的关键步骤。

(2)简述遗传算法中轮盘赌选择种群的方法。
1、计算出群体中每个个体的适应度f(i=1,2,…,M),M为群体大小;
(2)计算出每个个体被遗传到下一代群体中的概率;

(3)计算出每个个体的累积概率;
 (q[i]称为染色体x[i] (i=1, 2, …, n)的积累概率)
(q[i]称为染色体x[i] (i=1, 2, …, n)的积累概率)

(4)在[0,1]区间内产生一个均匀分布的伪随机数r;
(5)若r
(3)简述粒子群算法中粒子更新关键步骤。

根据适应度更新pbest、gbest,更新粒子位置速度
(4)简述阶方阵的所有特征值与方阵的行列式和迹之间的关系。

(5)简述极大似然估计算法
(一)写出似然函数
(6)给出方阵的特征多项式定义

它是λ的n次多项式,称为矩阵A的特征多项式。
(7)简述PCA关键计算步骤
(1) 标准化样本:x=x−x ̅,( x) ̅=1/n∑▒x, n为样本数量,样本特征向量x 的维度为 m
(2) 特征值分解:计算样本协方差阵S=Cov(x)= 1/n∑▒(x−x ̅)(x−x ̅)^T的全部非负特征值,并降序排列λ_1>λ_2>…>λ_m, 对应特征向量w1,w2,…,w^m
(3) 变换矩阵Case 1: 无损压缩 W=(w1,w2,…,w^m)Case 2: 有损压缩 一般地,选取满足λ_1+λ_2+…+λ_k/λ_1+λ_2+…+λ_m≥α=95%或90%的最小整数k,取W=(w1,w2,…,w^k),其中k
(8)简述C4.5算法中选取根节点的特征属性及处理连续属性值的关键步骤

处理连续值步骤
根据属性的值,对数据集排序;
用不同的阈值将数据集动态的进行划分;
取两个实际值中的中点作为一个阈值;
取两个划分,所有样本都在这两个划分中;
得到所有可能的阈值、增益及增益比;
在每一个属性会变为取两个取值,即小于阈值或大于等于阈值
(9)请给出凸函数的定义。
若函数f:R^m→R的定义域domf为凸集,且满足

则称f为凸函数(convex function)
(10)简述K折交叉验证。
将初始采样分割成K个子样本(S1,S2,…,Sk),取K-1个做训练集,另外一个做测试集。交叉验证重复K次,每个子样本都作为测试集一次,平均K次的结果,最终得到一个单一估测。
当K=n(样本总量),即为留一验证(Leave-one-out Cross Validation)
分,所有样本都在这两个划分中;
得到所有可能的阈值、增益及增益比;
在每一个属性会变为取两个取值,即小于阈值或大于等于阈值
(9)请给出凸函数的定义。
若函数f:R^m→R的定义域domf为凸集,且满足
[外链图片转存中…(img-2PIOsfRv-1624259614074)]
则称f为凸函数(convex function)
(10)简述K折交叉验证。
将初始采样分割成K个子样本(S1,S2,…,Sk),取K-1个做训练集,另外一个做测试集。交叉验证重复K次,每个子样本都作为测试集一次,平均K次的结果,最终得到一个单一估测。
当K=n(样本总量),即为留一验证(Leave-one-out Cross Validation)