【Datawhale 7月组队学习-python自动化办公】- task01
【重要提示】本文章内容为学习python自动化办公过程中整理的笔记和作业,教程源自Datawhale 7月组队学习-python自动化办公课程,链接为:GitHub - datawhalechina/office-automation: python自动化办公
一、文件处理与邮件自动化
1、文件处理
1.1.1文件名与文件路径
文件路径:文件在计算机上的储存位置。Windows使用“ / ”分隔文件夹,OS X 和 Linux 使用“ \ ”分隔。
文件名:文件在计算机上的名称
【常用的OS模块函数】
| 1 | os.path.join() | 组合多个路径,以字符中含有的第一个路径开始拼接 |
| 2 | os.path.dirname() | 获取路径名 |
| 3 | os.path.basename() | 获取文件名 |
| 4 | os.path.isfile() | 检验给出的路径是否是一个文件 |
| 5 | os.path.isdir() | 检验给出的路径是否是一个目录 |
| 6 | os.path.isabs() | 判断是否是绝对路径 |
| 7 | os.path.exists() | 检验给出的路径是否真地存 |
| 8 | os.path.split() | 返回一个路径的目录名和文件名 |
| 9 | os.path.splitext() | 分离扩展名 |
| 10 | os.path.getsize(filename) | 获取文件大小 |
| 11 | os.getcwd() | 获取当前工作目录 |
| 12 | os.getctime() |
返回文件或目录创建 |
| 13 | os.getatime | 返回访问时间 |
| 14 | os.getmtime | 返回修改时间 |
| 15 | os.mkdir(“test”) | 创建单个目录 |
| 16 | os.makedirs(r“c\python\test”) | 创建多级目录 |
| 17 | os.listdir() | 获取指定目录下的所有文件和目录名 |
| 18 | os.remove() | 删除指定文件 |
| 19 | os.removedirs() | 递归删除目录 |
| 20 | os.rename(old, new) | 重命名 |
| 21 | os.stat(file) | 获取文件属性 |
1.1.2 当前工作目录 os.getcwd()
获取当前工作目录:os.getcwd()
# 导入OS模块
import os
#获取当前工作目录
os.getcwd() ![]()
改变目录(前提是创建好目录):os.chdir()
#改变当前工作目录
os.chdir('D:\\python\\')
os.getcwd()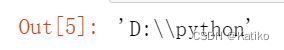
1.1.3 路径操作
1.1.3.1 绝对路径和相对路径
【如何区分】绝对路径从根文件夹开始,相对路径即当前工作目录,单个句点“.”表示当前目录的缩写,两个句点“..”表示父文件夹。
相对路径转绝对路径:os.path.abspath(path)
1.1.6 练习
1、如果已有的文件以写模式打开,会发生什么?
回答:以写模式打开,新增内容会覆盖掉原文内容,慎用写模式直接打开文件。
2、read()和readlines()方法之间的区别是什么?
read() 返回文件全部文本
readlines() 以列表的形式返回全部文本
3、
生成随机的测验试卷文件
假如你是一位地理老师, 班上有 35 名学生, 你希望进行美国各州首府的一个小测验。不妙的是,班里有几个坏蛋, 你无法确信学生不会作弊。你希望随机调整问题的次序, 这样每份试卷都是独一无二的, 这让任何人都不能从其他人那里抄袭答案。当然,手工完成这件事又费时又无聊。 好在, 你懂一些 Python。
下面是程序所做的事:
• 创建 35 份不同的测验试卷。
• 为每份试卷创建 50 个多重选择题,次序随机。
• 为每个问题提供一个正确答案和 3 个随机的错误答案,次序随机。
• 将测验试卷写到 35 个文本文件中。
• 将答案写到 35 个文本文件中。
这意味着代码需要做下面的事:
• 将州和它们的首府保存在一个字典中。
• 针对测验文本文件和答案文本文件,调用 open()、 write()和 close()。
• 利用 random.shuffle()随机调整问题和多重选项的次序。
以下是咨询男朋友获得的参考答案:
import random
import os
capitals = {'Alabama': 'Montgomery', 'Alaska': 'Juneau', 'Arizona': 'Phoenix',
'Arkansas': 'Little Rock', 'California': 'Sacramento', 'Colorado': 'Denver',
'Connecticut': 'Hartford', 'Delaware': 'Dover', 'Florida': 'Tallahassee',
'Georgia': 'Atlanta', 'Hawaii': 'Honolulu', 'Idaho': 'Boise', 'Illinois':
'Springfield', 'Indiana': 'Indianapolis', 'Iowa': 'Des Moines', 'Kansas':
'Topeka', 'Kentucky': 'Frankfort', 'Louisiana': 'Baton Rouge', 'Maine':
'Augusta', 'Maryland': 'Annapolis', 'Massachusetts': 'Boston', 'Michigan':
'Lansing', 'Minnesota': 'Saint Paul', 'Mississippi': 'Jackson', 'Missouri':
'Jefferson City', 'Montana': 'Helena', 'Nebraska': 'Lincoln', 'Nevada':
'Carson City', 'New Hampshire': 'Concord', 'New Jersey': 'Trenton', 'New Mexico': 'Santa Fe',
'New York': 'Albany', 'North Carolina': 'Raleigh',
'North Dakota': 'Bismarck', 'Ohio': 'Columbus', 'Oklahoma': 'Oklahoma City',
'Oregon': 'Salem', 'Pennsylvania': 'Harrisburg', 'Rhode Island': 'Providence',
'South Carolina': 'Columbia', 'South Dakota': 'Pierre', 'Tennessee':
'Nashville', 'Texas': 'Austin', 'Utah': 'Salt Lake City', 'Vermont':
'Montpelier', 'Virginia': 'Richmond', 'Washington': 'Olympia', 'West Virginia': 'Charleston',
'Wisconsin': 'Madison', 'Wyoming': 'Cheyenne'}
def create_question(question_number, states, paper_number):
"""
生成一道题
question_number: 题号
states: 打乱后的州名
paper_number: 试卷号
"""
# 获得题号对应的正确答案
question_state = states[question_number]
answers = list(capitals.values())
right_anwer = capitals.get(question_state)
# 接下来要生成三个错误的答案
# 首先要删除正确的答案
answers.remove(right_anwer)
# 随机抽取三个
wrong_answers = random.sample(answers, 3)
# 还要将这四个答案与ABCD相对应
options = list('ABCD')
random.shuffle(options)
# 生成字典:字典的key-ABCD 值-三个错误答案+一个正确答案
d = dict(zip(options, wrong_answers + [right_anwer]))
stem = f"{question_number + 1}. What's the capital of {question_state}?\nA.{d['A']} B.{d['B']} C.{d['C']} D.{d['D']}\n"
right_option = f'{question_number + 1}.{options[-1]}\n'
# 将题目写入到对应的试卷中
write_to_file(f'试卷/试卷{paper_number + 1}.txt', stem, question_number)
# 将答案写到对应的答案中
write_to_file(f'答案/答案{paper_number + 1}.txt', right_option, question_number)
def create_paper(paper_number):
"""
生成一套试卷
paper_number: 试卷编号
"""
states = list(capitals.keys())
for i in range(50):
random.shuffle(states)
create_question(i, states, paper_number)
print(f'第{i}题已生成')
def write_to_file(filename, s, number):
"""
写文件
如果是初次写试卷文件,则还需要添加抬头
"""
# 文件不存在,则创建抬头;否则,追加写入内容
with open(filename, 'a') as f:
title = "Name: \nScore: \n\n\n***********************start***********************\n"\
* (number == 0)
if "试卷" in filename:
f.write(title + s)
else:
f.write(s)
def gen():
for i in range(35):
create_paper(i)
gen()