- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 番茄西红柿叶子病害分类数据集12882张11类别
futureflsl
数据集分类数据挖掘人工智能
数据集类型:图像分类用,不可用于目标检测无标注文件数据集格式:仅仅包含jpg图片,每个类别文件夹下面存放着对应图片图片数量(jpg文件个数):12882分类类别数:11类别名称:["Bacterial_Spot_Bacteria","Early_Blight_Fungus","Healthy","Late_Blight_Water_Mold","Leaf_Mold_Fungus","Powdery
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- xilinx vivado PULLMODE 设置思路
坚持每天写程序
fpga开发
1.xilinx引脚分类XilinxIO的分类:以XC7A100TFGG484为例,其引脚分类如下:1.UserIO(用户IO):用户使用的普通IO1.1专用(Dedicated)IO:命名为IO_LXXY_#、IO_XX_#的引脚,有固定的特定用途,多为底层特定功能的直接实现,如差分对信号、关键控制信号等,不能随意变更。1.2多功能(Multi-Function)IO:命名为IO_LXXY_ZZ
- Python实现简单的机器学习算法
master_chenchengg
pythonpython办公效率python开发IT
Python实现简单的机器学习算法开篇:初探机器学习的奇妙之旅搭建环境:一切从安装开始必备工具箱第一步:安装Anaconda和JupyterNotebook小贴士:如何配置Python环境变量算法初体验:从零开始的Python机器学习线性回归:让数据说话数据准备:从哪里找数据编码实战:Python实现线性回归模型评估:如何判断模型好坏逻辑回归:从分类开始理论入门:什么是逻辑回归代码实现:使用skl
- K近邻算法_分类鸢尾花数据集
_feivirus_
算法机器学习和数学分类机器学习K近邻
importnumpyasnpimportpandasaspdfromsklearn.datasetsimportload_irisfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportaccuracy_score1.数据预处理iris=load_iris()df=pd.DataFrame(data=ir
- 网络通信流程
记得开心一点啊
服务器网络运维
目录♫IP地址♫子网掩码♫MAC地址♫相关设备♫ARP寻址♫网络通信流程♫IP地址我们已经知道IP地址由网络号+主机号组成,根据IP地址的不同可以有5钟划分网络号和主机号的方案:其中,各类地址的表示范围是:分类范围适用网络网络数量主机最大连接数A类0.0.0.0~127.255.255.255大型网络12616777214【(2^24)-2】B类128.0.0.0~191.255.255.255中
- 5分钟说透AppStore审核原理,让你拥有上架新思路!
Q仔本人噢
在AppStore上架是越来越难了!相信非常多公司的技术人员都为此困扰,然而外包团队水平又层次不齐,容易遇坑,实在是内忧外患。是什么原因导致审核机制频繁调整?又是什么原因使得审核变得越发严格?那么接下来听小Q分解,马上给各位带来解答!首先看一下近一年的上下架的情况:近一年上架情况近一年下架情况通过数据我们发现越是马甲包产量权重高的分类里被下架的app数量越多,苹果此举可谓是上有政策,下有对策。通过
- 遥感影像的切片处理
sand&wich
计算机视觉python图像处理
在遥感影像分析中,经常需要将大尺寸的影像切分成小片段,以便于进行详细的分析和处理。这种方法特别适用于机器学习和图像处理任务,如对象检测、图像分类等。以下是如何使用Python和OpenCV库来实现这一过程,同时确保每个影像片段保留正确的地理信息。准备环境首先,确保安装了必要的Python库,包括numpy、opencv-python和xml.etree.ElementTree。这些库将用于图像处理
- 《转介绍方法论》学习笔记
小可乐的妈妈
一、高效转介绍的流程:价值观---执行----方案一)转介绍发生的背景:1、对象:谁向谁转介绍?全员营销,人人参与。①员工的激励政策、客户的转介绍诱因制作客户画像:a信任;支付能力;意愿度;便利度(根据家长具备四个特征的个数分为四类)B性格分类C职业分类D年龄性别②执行:套路,策略,方法,流程2、诱因:为什么要转介绍?认同信任;多方共赢;传递美好;零风险承诺打动人心,超越期待。选择做教育,就是选择
- JAVA学习笔记之23种设计模式学习
victorfreedom
Java技术设计模式androidjava常用设计模式
博主最近买了《设计模式》这本书来学习,无奈这本书是以C++语言为基础进行说明,整个学习流程下来效率不是很高,虽然有的设计模式通俗易懂,但感觉还是没有充分的掌握了所有的设计模式。于是博主百度了一番,发现有大神写过了这方面的问题,于是博主迅速拿来学习。一、设计模式的分类总体来说设计模式分为三大类:创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。结构型模式,共七种:适配器
- 推荐3家毕业AI论文可五分钟一键生成!文末附免费教程!
小猪包333
写论文人工智能AI写作深度学习计算机视觉
在当前的学术研究和写作领域,AI论文生成器已经成为许多研究人员和学生的重要工具。这些工具不仅能够帮助用户快速生成高质量的论文内容,还能进行内容优化、查重和排版等操作。以下是三款值得推荐的AI论文生成器:千笔-AIPassPaper、懒人论文以及AIPaperPass。千笔-AIPassPaper千笔-AIPassPaper是一款基于深度学习和自然语言处理技术的AI写作助手,旨在帮助用户快速生成高质
- 【自动化测试】UI自动化的分类、如何选择合适的自动化测试工具以及其中appium的设计理念、引擎和引擎如何工作
Lossya
ui自动化测试工具自动化测试appium
引言UI自动化测试主要针对软件的用户界面进行测试,以确保用户界面元素的交互和功能符合预期文章目录引言一、UI自动化的分类1.1基于代码的自动化测试1.2基于录制/回放的自动化测试1.3基于框架的自动化测试1.4按测试对象分类1.5按测试层次分类1.6按测试执行方式分类1.7按测试目的分类二、如何选择合适的自动化测试工具2.1项目需求分析2.2工具特性评估2.3成本考虑2.4团队技能2.5试用和评估
- AI大模型的架构演进与最新发展
季风泯灭的季节
AI大模型应用技术二人工智能架构
随着深度学习的发展,AI大模型(LargeLanguageModels,LLMs)在自然语言处理、计算机视觉等领域取得了革命性的进展。本文将详细探讨AI大模型的架构演进,包括从Transformer的提出到GPT、BERT、T5等模型的历史演变,并探讨这些模型的技术细节及其在现代人工智能中的核心作用。一、基础模型介绍:Transformer的核心原理Transformer架构的背景在Transfo
- ai绘画工具midjourney怎么下载?附作品管理教程
设计师早上好
Midjourney是一款功能强大的AI绘画工具,它使用机器学习技术和深度神经网络等算法,可以生成各种艺术风格的绘画作品。在创意设计、广告宣传等方面有着广泛的应用前景。那么,ai绘画工具midjourney怎么下载?本文将为您介绍Midjourney的下载以及作品的相关管理。一、Midjourney下载Midjourney的下载非常简单,只需打开Midjourney官网(点击“GetMidjour
- 性格小测试
熹大头
有些人非常肯定自己属于外向型,有些人则发现自己是绝对的内向型。然而,多数人却发现他们似乎介于两者之间,是两种性格的结合。现在我们就来看看你在这种分类中处在何种位置。阅读以下问题,从a、b、c中选出最适合自己的选项。你可能会发现三个选项都不合适,或者合适的不止一项,这种情况下,选出相对来说更适合自己的即可。1人们经常会用下列哪个词语描述你:a善于分析b遵守纪律c有创造力2一连几天参与社交活动(比如,
- 李克富 | 咨询师推荐阅读书目
李克富
最重要的书籍不是别人的推荐,而是自己学过的教材,不论当初使用的是哪个版本,它都是我们专业的底层代码,具有不可替代性。前不久,中国心理咨询师筹委会的一位老师邀请我罗列一个推荐书目清单作为咨询师工具包的内容,并要求“说明一下简单的分类或者作三言两语的说明”。斟酌后,我觉得自己推荐的书目大体可以分为普及类书籍、心理学书籍和心理咨询与治疗专业书籍,第三类又分为适合于咨询师新手的和有经验咨询师的。经过严格筛
- [实践应用] 深度学习之模型性能评估指标
YuanDaima2048
深度学习工具使用深度学习人工智能损失函数性能评估pytorchpython机器学习
文章总览:YuanDaiMa2048博客文章总览深度学习之模型性能评估指标分类任务回归任务排序任务聚类任务生成任务其他介绍在机器学习和深度学习领域,评估模型性能是一项至关重要的任务。不同的学习任务需要不同的性能指标来衡量模型的有效性。以下是对一些常见任务及其相应的性能评估指标的详细解释和总结。分类任务分类任务是指模型需要将输入数据分配到预定义的类别或标签中。以下是分类任务中常用的性能指标:准确率(
- [实践应用] 深度学习之优化器
YuanDaima2048
深度学习工具使用pytorch深度学习人工智能机器学习python优化器
文章总览:YuanDaiMa2048博客文章总览深度学习之优化器1.随机梯度下降(SGD)2.动量优化(Momentum)3.自适应梯度(Adagrad)4.自适应矩估计(Adam)5.RMSprop总结其他介绍在深度学习中,优化器用于更新模型的参数,以最小化损失函数。常见的优化函数有很多种,下面是几种主流的优化器及其特点、原理和PyTorch实现:1.随机梯度下降(SGD)原理:随机梯度下降通过
- 新能源汽车 BMS 学习笔记篇—BMS 基本定义及分类
WPG大大通
其他笔记汽车BMS经验分享新能源电池
一、BMS定义1、概念:BMS(BatteryManagementSystem)即电池管理系统,其管理对象是二次电池(充电电池或蓄电池),其主要目的是电池的利用率,防止电池出现过度充电和过度放电,可应用于电动汽车、电瓶车、机器人、无人机等图片来源:腾讯网https://new.qq.com《标准普尔警告,电动汽车电池生产面临供应链和地缘政治风险》2、四大功能①感知和测量:检测电池的电压、电流、温度
- 机器学习-聚类算法
不良人龍木木
机器学习机器学习算法聚类
机器学习-聚类算法1.AHC2.K-means3.SC4.MCL仅个人笔记,感谢点赞关注!1.AHC2.K-means3.SC传统谱聚类:个人对谱聚类算法的理解以及改进4.MCL目前仅专注于NLP的技术学习和分享感谢大家的关注与支持!
- 生成式地图制图
Bwywb_3
深度学习机器学习深度学习生成对抗网络
生成式地图制图(GenerativeCartography)是一种利用生成式算法和人工智能技术自动创建地图的技术。它结合了传统的地理信息系统(GIS)技术与现代生成模型(如深度学习、GANs等),能够根据输入的数据自动生成符合需求的地图。这种方法在城市规划、虚拟环境设计、游戏开发等多个领域具有应用前景。主要特点:自动化生成:通过算法和模型,系统能够根据输入的地理或空间数据自动生成地图,而无需人工逐
- 郭生白中药方论之二(破除温凉寒热的框框)
本能学堂a昨年
离病说药茫茫然,对症下药不着边。顺势利导一乘法,排异调节渡法船。无限整合非模糊,模糊病区得清楚。共性之外求个性,亲和不生抗药性。温凉寒热巧方便,君臣佐使筏喻焉。药包大小折中看,毒性有无一念间。导读破除温凉寒热的框框寒热温凉是基于中药共性的传统分类药无寒热人有寒热药无寒热病有寒热抛弃温凉不并用的错误观念寒热温凉是基于中药共性的传统分类寒热温凉是个共性,是说的共性。这个共性,知道什么叫共性吗?所有的药
- 未来软件市场是怎么样的?做开发的生存空间如何?
cesske
软件需求
目录前言一、未来软件市场的发展趋势二、软件开发人员的生存空间前言未来软件市场是怎么样的?做开发的生存空间如何?一、未来软件市场的发展趋势技术趋势:人工智能与机器学习:随着技术的不断成熟,人工智能将在更多领域得到应用,如智能客服、自动驾驶、智能制造等,这将极大地推动软件市场的增长。云计算与大数据:云计算服务将继续普及,大数据技术的应用也将更加广泛。企业将更加依赖云计算和大数据来优化运营、提升效率,并
- 2022-04-25
L是木子李呢
上门维修APP开发应具备哪些功能随着移动互联网的不断发展,上门维修在我们生活中已经是非常普遍的存在了,为了给用户更方便的找到上门维修的渠道,上门维修APP应运而生,那么上门维修APP开发应具备哪些功能呢?1、维修门店搜索为了更好地方便用户省时省力,上门维修APP会依据用户定位信息搜索线下实体店,促使用户更好的找到线下维修店面,省时又省力。2、维修服务分类包括管道洁具维修、强电弱电维修、木工维修、粉
- 吴恩达深度学习笔记(30)-正则化的解释
极客Array
正则化(Regularization)深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。如果你怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,这也是非常
- 个人学习笔记7-6:动手学深度学习pytorch版-李沐
浪子L
深度学习深度学习笔记计算机视觉python人工智能神经网络pytorch
#人工智能##深度学习##语义分割##计算机视觉##神经网络#计算机视觉13.11全卷积网络全卷积网络(fullyconvolutionalnetwork,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换。引入l转置卷积(transposedconvolution)实现的,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。13.11.1构造模型下
- 怎么样才能成为专业的程序员?
cocos2d-x小菜
编程PHP
如何要想成为一名专业的程序员?仅仅会写代码是不够的。从团队合作去解决问题到版本控制,你还得具备其他关键技能的工具包。当我们询问相关的专业开发人员,那些必备的关键技能都是什么的时候,下面是我们了解到的情况。
关于如何学习代码,各种声音很多,然后很多人就被误导为成为专业开发人员懂得一门编程语言就够了?!呵呵,就像其他工作一样,光会一个技能那是远远不够的。如果你想要成为
- java web开发 高并发处理
BreakingBad
javaWeb并发开发处理高
java处理高并发高负载类网站中数据库的设计方法(java教程,java处理大量数据,java高负载数据) 一:高并发高负载类网站关注点之数据库 没错,首先是数据库,这是大多数应用所面临的首个SPOF。尤其是Web2.0的应用,数据库的响应是首先要解决的。 一般来说MySQL是最常用的,可能最初是一个mysql主机,当数据增加到100万以上,那么,MySQL的效能急剧下降。常用的优化措施是M-S(
- mysql批量更新
ekian
mysql
mysql更新优化:
一版的更新的话都是采用update set的方式,但是如果需要批量更新的话,只能for循环的执行更新。或者采用executeBatch的方式,执行更新。无论哪种方式,性能都不见得多好。
三千多条的更新,需要3分多钟。
查询了批量更新的优化,有说replace into的方式,即:
replace into tableName(id,status) values
- 微软BI(3)
18289753290
微软BI SSIS
1)
Q:该列违反了完整性约束错误;已获得 OLE DB 记录。源:“Microsoft SQL Server Native Client 11.0” Hresult: 0x80004005 说明:“不能将值 NULL 插入列 'FZCHID',表 'JRB_EnterpriseCredit.dbo.QYFZCH';列不允许有 Null 值。INSERT 失败。”。
A:一般这类问题的存在是
- Java中的List
g21121
java
List是一个有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
与 set 不同,列表通常允许重复
- 读书笔记
永夜-极光
读书笔记
1. K是一家加工厂,需要采购原材料,有A,B,C,D 4家供应商,其中A给出的价格最低,性价比最高,那么假如你是这家企业的采购经理,你会如何决策?
传统决策: A:100%订单 B,C,D:0%
&nbs
- centos 安装 Codeblocks
随便小屋
codeblocks
1.安装gcc,需要c和c++两部分,默认安装下,CentOS不安装编译器的,在终端输入以下命令即可yum install gccyum install gcc-c++
2.安装gtk2-devel,因为默认已经安装了正式产品需要的支持库,但是没有安装开发所需要的文档.yum install gtk2*
3. 安装wxGTK
yum search w
- 23种设计模式的形象比喻
aijuans
设计模式
1、ABSTRACT FACTORY—追MM少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是MM爱吃的东西,虽然口味有所不同,但不管你带MM去麦当劳或肯德基,只管向服务员说“来四个鸡翅”就行了。麦当劳和肯德基就是生产鸡翅的Factory 工厂模式:客户类和工厂类分开。消费者任何时候需要某种产品,只需向工厂请求即可。消费者无须修改就可以接纳新产品。缺点是当产品修改时,工厂类也要做相应的修改。如:
- 开发管理 CheckLists
aoyouzi
开发管理 CheckLists
开发管理 CheckLists(23) -使项目组度过完整的生命周期
开发管理 CheckLists(22) -组织项目资源
开发管理 CheckLists(21) -控制项目的范围开发管理 CheckLists(20) -项目利益相关者责任开发管理 CheckLists(19) -选择合适的团队成员开发管理 CheckLists(18) -敏捷开发 Scrum Master 工作开发管理 C
- js实现切换
百合不是茶
JavaScript栏目切换
js主要功能之一就是实现页面的特效,窗体的切换可以减少页面的大小,被门户网站大量应用思路:
1,先将要显示的设置为display:bisible 否则设为none
2,设置栏目的id ,js获取栏目的id,如果id为Null就设置为显示
3,判断js获取的id名字;再设置是否显示
代码实现:
html代码:
<di
- 周鸿祎在360新员工入职培训上的讲话
bijian1013
感悟项目管理人生职场
这篇文章也是最近偶尔看到的,考虑到原博客发布者可能将其删除等原因,也更方便个人查找,特将原文拷贝再发布的。“学东西是为自己的,不要整天以混的姿态来跟公司博弈,就算是混,我觉得你要是能在混的时间里,收获一些别的有利于人生发展的东西,也是不错的,看你怎么把握了”,看了之后,对这句话记忆犹新。 &
- 前端Web开发的页面效果
Bill_chen
htmlWebMicrosoft
1.IE6下png图片的透明显示:
<img src="图片地址" border="0" style="Filter.Alpha(Opacity)=数值(100),style=数值(3)"/>
或在<head></head>间加一段JS代码让透明png图片正常显示。
2.<li>标
- 【JVM五】老年代垃圾回收:并发标记清理GC(CMS GC)
bit1129
垃圾回收
CMS概述
并发标记清理垃圾回收(Concurrent Mark and Sweep GC)算法的主要目标是在GC过程中,减少暂停用户线程的次数以及在不得不暂停用户线程的请夸功能,尽可能短的暂停用户线程的时间。这对于交互式应用,比如web应用来说,是非常重要的。
CMS垃圾回收针对新生代和老年代采用不同的策略。相比同吞吐量垃圾回收,它要复杂的多。吞吐量垃圾回收在执
- Struts2技术总结
白糖_
struts2
必备jar文件
早在struts2.0.*的时候,struts2的必备jar包需要如下几个:
commons-logging-*.jar Apache旗下commons项目的log日志包
freemarker-*.jar
- Jquery easyui layout应用注意事项
bozch
jquery浏览器easyuilayout
在jquery easyui中提供了easyui-layout布局,他的布局比较局限,类似java中GUI的border布局。下面对其使用注意事项作简要介绍:
如果在现有的工程中前台界面均应用了jquery easyui,那么在布局的时候最好应用jquery eaysui的layout布局,否则在表单页面(编辑、查看、添加等等)在不同的浏览器会出
- java-拷贝特殊链表:有一个特殊的链表,其中每个节点不但有指向下一个节点的指针pNext,还有一个指向链表中任意节点的指针pRand,如何拷贝这个特殊链表?
bylijinnan
java
public class CopySpecialLinkedList {
/**
* 题目:有一个特殊的链表,其中每个节点不但有指向下一个节点的指针pNext,还有一个指向链表中任意节点的指针pRand,如何拷贝这个特殊链表?
拷贝pNext指针非常容易,所以题目的难点是如何拷贝pRand指针。
假设原来链表为A1 -> A2 ->... -> An,新拷贝
- color
Chen.H
JavaScripthtmlcss
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <HTML> <HEAD>&nbs
- [信息与战争]移动通讯与网络
comsci
网络
两个坚持:手机的电池必须可以取下来
光纤不能够入户,只能够到楼宇
建议大家找这本书看看:<&
- oracle flashback query(闪回查询)
daizj
oracleflashback queryflashback table
在Oracle 10g中,Flash back家族分为以下成员:
Flashback Database
Flashback Drop
Flashback Table
Flashback Query(分Flashback Query,Flashback Version Query,Flashback Transaction Query)
下面介绍一下Flashback Drop 和Flas
- zeus持久层DAO单元测试
deng520159
单元测试
zeus代码测试正紧张进行中,但由于工作比较忙,但速度比较慢.现在已经完成读写分离单元测试了,现在把几种情况单元测试的例子发出来,希望有人能进出意见,让它走下去.
本文是zeus的dao单元测试:
1.单元测试直接上代码
package com.dengliang.zeus.webdemo.test;
import org.junit.Test;
import o
- C语言学习三printf函数和scanf函数学习
dcj3sjt126com
cprintfscanflanguage
printf函数
/*
2013年3月10日20:42:32
地点:北京潘家园
功能:
目的:
测试%x %X %#x %#X的用法
*/
# include <stdio.h>
int main(void)
{
printf("哈哈!\n"); // \n表示换行
int i = 10;
printf
- 那你为什么小时候不好好读书?
dcj3sjt126com
life
dady, 我今天捡到了十块钱, 不过我还给那个人了
good girl! 那个人有没有和你讲thank you啊
没有啦....他拉我的耳朵我才把钱还给他的, 他哪里会和我讲thank you
爸爸, 如果地上有一张5块一张10块你拿哪一张呢....
当然是拿十块的咯...
爸爸你很笨的, 你不会两张都拿
爸爸为什么上个月那个人来跟你讨钱, 你告诉他没
- iptables开放端口
Fanyucai
linuxiptables端口
1,找到配置文件
vi /etc/sysconfig/iptables
2,添加端口开放,增加一行,开放18081端口
-A INPUT -m state --state NEW -m tcp -p tcp --dport 18081 -j ACCEPT
3,保存
ESC
:wq!
4,重启服务
service iptables
- Ehcache(05)——缓存的查询
234390216
排序ehcache统计query
缓存的查询
目录
1. 使Cache可查询
1.1 基于Xml配置
1.2 基于代码的配置
2 指定可搜索的属性
2.1 可查询属性类型
2.2 &
- 通过hashset找到数组中重复的元素
jackyrong
hashset
如何在hashset中快速找到重复的元素呢?方法很多,下面是其中一个办法:
int[] array = {1,1,2,3,4,5,6,7,8,8};
Set<Integer> set = new HashSet<Integer>();
for(int i = 0
- 使用ajax和window.history.pushState无刷新改变页面内容和地址栏URL
lanrikey
history
后退时关闭当前页面
<script type="text/javascript">
jQuery(document).ready(function ($) {
if (window.history && window.history.pushState) {
- 应用程序的通信成本
netkiller.github.com
虚拟机应用服务器陈景峰netkillerneo
应用程序的通信成本
什么是通信
一个程序中两个以上功能相互传递信号或数据叫做通信。
什么是成本
这是是指时间成本与空间成本。 时间就是传递数据所花费的时间。空间是指传递过程耗费容量大小。
都有哪些通信方式
全局变量
线程间通信
共享内存
共享文件
管道
Socket
硬件(串口,USB) 等等
全局变量
全局变量是成本最低通信方法,通过设置
- 一维数组与二维数组的声明与定义
恋洁e生
二维数组一维数组定义声明初始化
/** * */ package test20111005; /** * @author FlyingFire * @date:2011-11-18 上午04:33:36 * @author :代码整理 * @introduce :一维数组与二维数组的初始化 *summary: */ public c
- Spring Mybatis独立事务配置
toknowme
mybatis
在项目中有很多地方会使用到独立事务,下面以获取主键为例
(1)修改配置文件spring-mybatis.xml <!-- 开启事务支持 --> <tx:annotation-driven transaction-manager="transactionManager" /> &n
- 更新Anadroid SDK Tooks之后,Eclipse提示No update were found
xp9802
eclipse
使用Android SDK Manager 更新了Anadroid SDK Tooks 之后,
打开eclipse提示 This Android SDK requires Android Developer Toolkit version 23.0.0 or above, 点击Check for Updates
检测一会后提示 No update were found
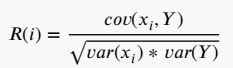
 为第i个特征,为类标签,()为协方差,()为方差。该准则只能检测变量与目标之间的线性依赖关系。
为第i个特征,为类标签,()为协方差,()为方差。该准则只能检测变量与目标之间的线性依赖关系。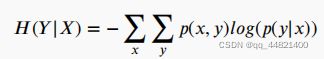
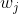 定义为
定义为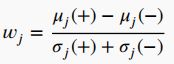
 和为(+)和(-)类样本的平均值和标准差。较大的正值表示与类(+)有很强的相关性,而较大的负值表示与类(-)有很强的相关性。
和为(+)和(-)类样本的平均值和标准差。较大的正值表示与类(+)有很强的相关性,而较大的负值表示与类(-)有很强的相关性。