神经网络学习小记录23——MobileNet模型的复现详解
神经网络学习小记录23——MobileNet模型的复现详解
- 学习前言
- 什么是MobileNet模型
- MobileNet网络部分实现代码
- 图片预测
学习前言
MobileNet是一种轻量级网络,相比于其它结构网络,它不一定是最准的,但是它真的很轻!

什么是MobileNet模型
MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution。
对于一个卷积点而言:
假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。
可以看出来depthwise separable convolution可以减少模型的参数。
如下这张图就是depthwise separable convolution的结构
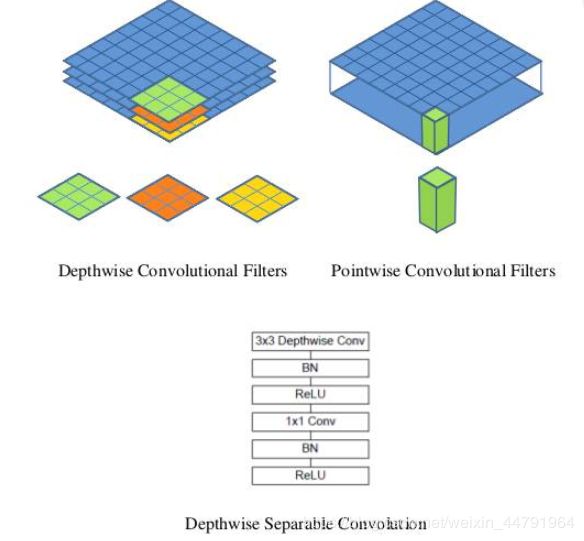
在建立模型的时候,可以使用Keras中的DepthwiseConv2D层实现深度可分离卷积,然后再利用1x1卷积调整channels数。
通俗地理解就是3x3的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,在利用1x1的卷积调整厚度。
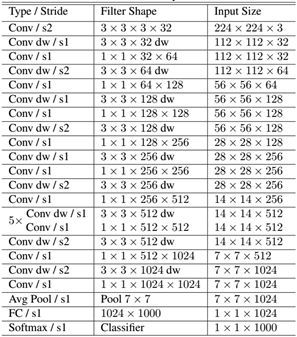
如下就是MobileNet的结构,其中Conv dw就是分层卷积,在其之后都会接一个1x1的卷积进行通道处理,
MobileNet网络部分实现代码
#-------------------------------------------------------------#
# MobileNet的网络部分
#-------------------------------------------------------------#
import warnings
import numpy as np
from keras.preprocessing import image
from keras.models import Model
from keras.layers import DepthwiseConv2D,Input,Activation,Dropout,Reshape,BatchNormalization,GlobalAveragePooling2D,GlobalMaxPooling2D,Conv2D
from keras.applications.imagenet_utils import decode_predictions
from keras import backend as K
def MobileNet(input_shape=[224,224,3],
depth_multiplier=1,
dropout=1e-3,
classes=1000):
img_input = Input(shape=input_shape)
# 224,224,3 -> 112,112,32
x = _conv_block(img_input, 32, strides=(2, 2))
# 112,112,32 -> 112,112,64
x = _depthwise_conv_block(x, 64, depth_multiplier, block_id=1)
# 112,112,64 -> 56,56,128
x = _depthwise_conv_block(x, 128, depth_multiplier,
strides=(2, 2), block_id=2)
# 56,56,128 -> 56,56,128
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=3)
# 56,56,128 -> 28,28,256
x = _depthwise_conv_block(x, 256, depth_multiplier,
strides=(2, 2), block_id=4)
# 28,28,256 -> 28,28,256
x = _depthwise_conv_block(x, 256, depth_multiplier, block_id=5)
# 28,28,256 -> 14,14,512
x = _depthwise_conv_block(x, 512, depth_multiplier,
strides=(2, 2), block_id=6)
# 14,14,512 -> 14,14,512
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=7)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=8)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=9)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=10)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=11)
# 14,14,512 -> 7,7,1024
x = _depthwise_conv_block(x, 1024, depth_multiplier,
strides=(2, 2), block_id=12)
x = _depthwise_conv_block(x, 1024, depth_multiplier, block_id=13)
# 7,7,1024 -> 1,1,1024
x = GlobalAveragePooling2D()(x)
x = Reshape((1, 1, 1024), name='reshape_1')(x)
x = Dropout(dropout, name='dropout')(x)
x = Conv2D(classes, (1, 1),padding='same', name='conv_preds')(x)
x = Activation('softmax', name='act_softmax')(x)
x = Reshape((classes,), name='reshape_2')(x)
inputs = img_input
model = Model(inputs, x, name='mobilenet_1_0_224_tf')
model_name = 'mobilenet_1_0_224_tf.h5'
model.load_weights(model_name)
return model
def _conv_block(inputs, filters, kernel=(3, 3), strides=(1, 1)):
x = Conv2D(filters, kernel,
padding='same',
use_bias=False,
strides=strides,
name='conv1')(inputs)
x = BatchNormalization(name='conv1_bn')(x)
return Activation(relu6, name='conv1_relu')(x)
def _depthwise_conv_block(inputs, pointwise_conv_filters,
depth_multiplier=1, strides=(1, 1), block_id=1):
x = DepthwiseConv2D((3, 3),
padding='same',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(inputs)
x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x)
x = Activation(relu6, name='conv_dw_%d_relu' % block_id)(x)
x = Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x)
return Activation(relu6, name='conv_pw_%d_relu' % block_id)(x)
def relu6(x):
return K.relu(x, max_value=6)
图片预测
建立网络后,可以用以下的代码进行预测。
def preprocess_input(x):
x /= 255.
x -= 0.5
x *= 2.
return x
if __name__ == '__main__':
model = MobileNet(input_shape=(224, 224, 3))
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
print('Input image shape:', x.shape)
preds = model.predict(x)
print(np.argmax(preds))
print('Predicted:', decode_predictions(preds, 1))
预测所需的已经训练好的Xception模型可以在https://github.com/fchollet/deep-learning-models/releases下载。非常方便。
预测结果为:
Predicted: [[('n02504458', 'African_elephant', 0.7590296)]]