Advanced CNN - Inception Module from GoogleNet - Pytorch
笔记来自课程《Pytorch深度学习实践》Lecture 11
GoogleNet示意图
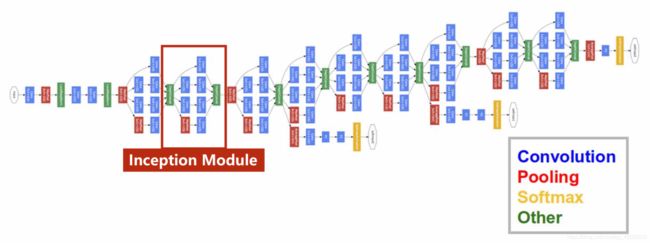
可以看到其中有许多重复的部分,叫做Inception module
Inception Module
在构造网络的时候我们有许多超参数不知道该怎么选择,比如kernel_size,然后这个inception模块就每个大小都用一用,看哪个效果好,比如说,如果3*3的效果很好的话,那么下图中3*3那条路线的权重肯定就大一些。
相当于它是提供了几条候选的神经网络的机制,然后择优录取。
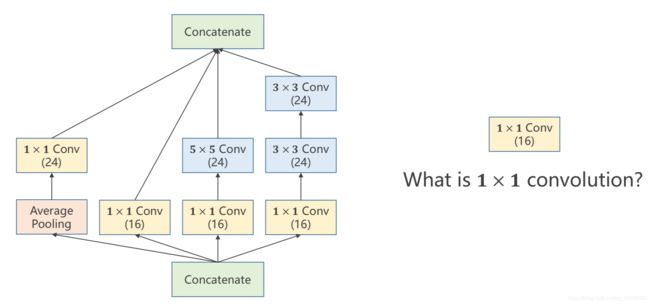
注意,做concatenate操作的话,必须得保证4条路径的宽度w和高度h是一致的,所以设置有padding。
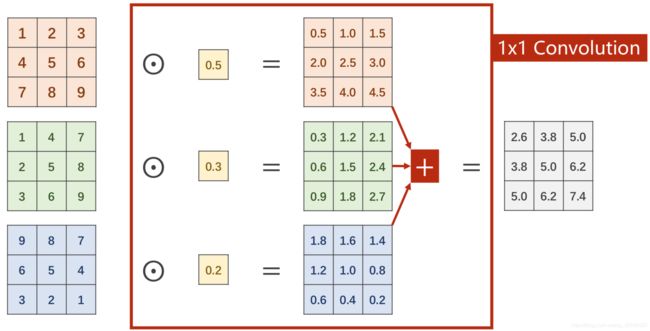
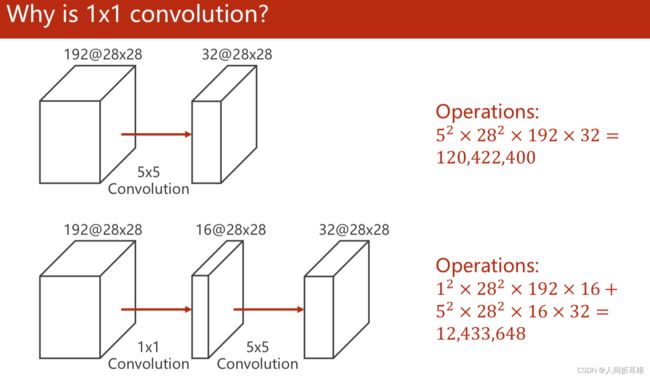
1X1的卷积可以起到信息融合的作用,还可以降低计算量,看上去网络变复杂了,其实运算量降低了:
Inception Module 的实现
上一行写在__init__()里,是定义;下两行写在forward()里
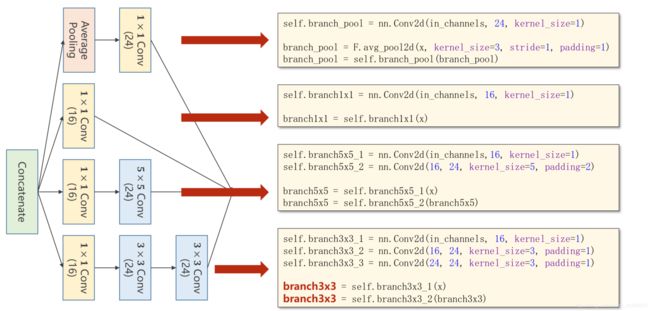
 拼接是按照通道的维度进行,最终的输出通道数为24+16+24+24=88
拼接是按照通道的维度进行,最终的输出通道数为24+16+24+24=88
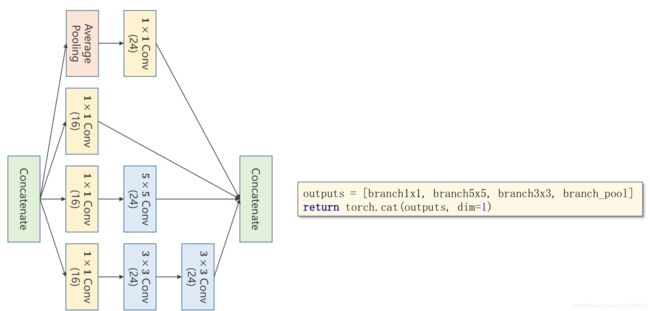
dim=1,意味着按照第一个维度,也就是channel进行拼接,因为输出shape为(B, C, W, H).
整合之后的代码:
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels,16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)in_channels没有写死,作为参数传入,但是输出的channels个数是一定的,24+16+24+24 = 88个
Inception Module的使用
class Net(nn.Module): def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x))) x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x))) x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x这个1408是最终元素个数,是依据MINST数据集算出来的,可以先不写这一行,让程序输出一下个数
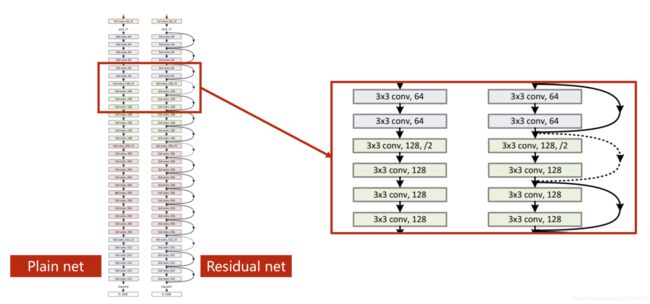
可以一直堆积层数吗?

No!可能会出现梯度消失的情况!
20层的卷积比50层的效果要好!
Residual Net 解决梯度消失
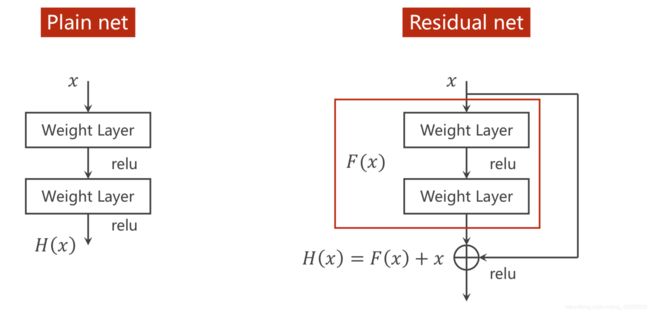
Residual net增加了一个跳连接,先和x相加,再激活。H对x求导,后面会+1,因此前面F对x的导数再小,也会后面有个1,因此若干个这样的数相乘,也不会趋近于0
要求:上面两层的输出,也就是F(x)必须和x的形状一摸一样,通道、宽度、高度都要一样
简单Residual Net的实现

Residual Block的输入与输出形状一样
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)完整的网络:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x