技术博客|第12期:多模态多兴趣多场景技术在Disney流媒体推荐召回中的应用
2022年第012篇


随着网络基础设施的发展,YouTube、Facebook、TikTok、Netflix 等内容平台上每天都会为大量用户提供服务。作为内容平台的重要组成部分,端上流媒体平台(如 Netflix、Hulu、Disney+)通常通过订阅的方式为客户提供在线视频点播 (VOD) 以及直播内容 (Live),以满足用户对于高质量视频内容的需求。为了帮助订阅用户找到感兴趣的内容,流媒体服务通常会构建页面级别的推荐系统,以展现个性化内容。推荐系统的好坏决定了用户满意度,并直接影响平台的商业指标。
现代推荐系统通常遵循“召回-(粗排)-精排-重排”的多阶段级联范式 [1,2]。作为推荐系统的最底层,召回阶段会从候选集合中检索相对少量的相关内容提供给后续阶段进行更细粒度的排序。因此,召回阶段决定了总体候选视频集合的质量,通常成为整个推荐系统的瓶颈。
早期的推荐系统通过采用协同过滤的方式进行召回 [3,4]。随着深度学习的发展,最近的工业级推荐系统多数倾向于利用双塔模型进行召回 [1,5,6]。双塔模型分别生成用户(user)和视频(item)的 embedding 向量,并通过内积等方式计算用户对视频的偏好。在线上推理阶段,工业界通常采用最近邻检索 [7-10] 等方法根据 user embedding 从视频库中检索最相似的视频。双塔模型可以有效利用用户和视频中的丰富特征捕获复杂的特征交互提升个性化,且允许高效的检索,因此在工业场景下广受青睐。
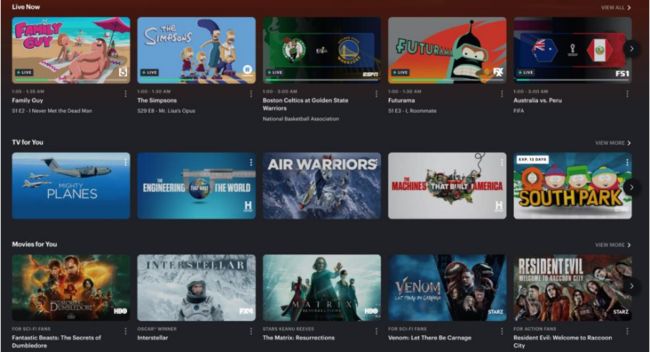
图 1:矩阵式布局的流媒体平台的个性化页面展示。
尽管双塔模型在各种工业应用中被使用,但以往的方法并没有充分考虑 Disney 流媒体平台的如下特点(尤其是元信息的利用,以及多场景的特点),因而直接将这些方法照搬到我们的平台上并不能得到最理想的推荐结果:
丰富的元信息。流媒体平台中的视频通常包含异构的元信息,包括视频 id、题材、系列、品牌、演员信息、视频特征、文本特征等。虽然已有方法使用多模态融合的方式进行元信息聚合,或者利用元信息训练出 graph embedding 进行单独一路召回 [11,12],但如何更有效地利用这些特征仍然是一个有挑战性的问题。
用户的多兴趣。Disney 流媒体服务的节目大致可以分为点播剧集、电影和直播内容。不同类别的用户行为反映了用户在平台上粗粒度的多兴趣。用户在同一类别中也会表现出细粒度的多兴趣。例如,某个订阅用户可能同时观看过点播的纪录片、喜剧和悲剧。为了更好地理解用户,召回模型应该有能力建模用户多样化的兴趣。
平台的多场景。流媒体推荐天然面临着多场景的问题。从订阅用户的角度,推荐系统需要为选择不同订阅套餐(导致可观看的内容不同)、来自不同地区和国家的用户提供服务。从产品的角度,流媒体平台通常采用一种矩阵式的页面布局(如图1)呈现符合不同主题的推荐结果。由于用户行为在不同场景之间的行为普遍存在差异,采用单一模型不能够区分场景的差异,而构建多个召回模型也会由于不能捕捉场景间的共同特征而导致次优的推荐结果。
视频数量的有限性。与电商和短视频场景不同,Disney 流媒体平台仅向订阅者提供数量有限的高质量和原创内容。受益于有限的视频集合,召回模型可以精确地为每个候选视频打分,且不需要使用任何近似方法进行检索。这种灵活性允许了比双塔结构更复杂的模型构建方式。
基于上述提到的 Disney 流媒体平台的特点,我们提出了基于多模态多兴趣多场景技术的召回模型M5(Multi-Modal Multi-Interest Multi-Scenario Matching),以向订阅用户提供更好的推荐服务。

Disney 流媒体服务主要向用户呈现感兴趣的视频,包括点播剧集、点播电影和直播节目。作为推荐系统的最底层,召回阶段的目标是从候选集合中 I 为给定用户 u 找出 N 个最符合其兴趣的视频。这个过程可以被形式化地表示为:
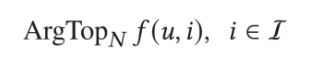
其中 f(u,i) 是模型预测的用户对目标视频的偏好打分。

为了给出准确的预测,我们在 Disney 流媒体召回中使用了丰富的特征,主要分为以下几个类别:
用户特征:包含年龄、性别、用户统计类特征(如用户观看某种类别视频的次数);
行为特征:行为特征是最重要的一种用户画像,包括高频的隐式用户观看行为以及低频的喜欢、不喜欢等用户主动操作。每个行为序列被聚合到 剧集 级别,以对同一剧集的重复消费进行去重(例如,“辛普森一家” 和 NBA 的内容在每个行为特征中只出现一次);否则,这些重复性和周期性的内容消费将会主导行为序列的构成。除此之外,每个行为的细粒度描述也被加到每个行为当中,以弥补在聚合过程中的信息损失,在后文中我们将具体介绍。为了简单起见,我们只在后文考虑用户的历史观看行为,其他的行为(诸如喜欢、不喜欢等)都遵循相似的处理方式;
上下文特征:包含设备、小时、日期等特征。同时还有类似于“用户最后一个行为至今的时间”捕捉行为的新鲜度;
目标特征:与行为特征中的每个视频相同。

如下图所示,M5 的整体架构遵循双通道双塔的模式。M5 在最底层通过多模态 embedding 层将每个 剧集 id 编码成基于 id 和基于内容关系图 (content graph, cg)的 embedding,以充分挖掘 Disney 流媒体中丰富的元数据。为了在保留多模态语义的同时有效地召回,M5 扩展了以往常见的双塔架构,以双通道的形式分别计算基于 id 和 cg 的用户-视频偏好。其中,user embedding 通过并行的多兴趣抽取层和多场景融合层生成,item embedding 通过对候选视频集合在 id 和 cg 的 embedding table 查找得到。最终 M5 利用动态加权层合并多模态预测结果并生成统一的召回打分。
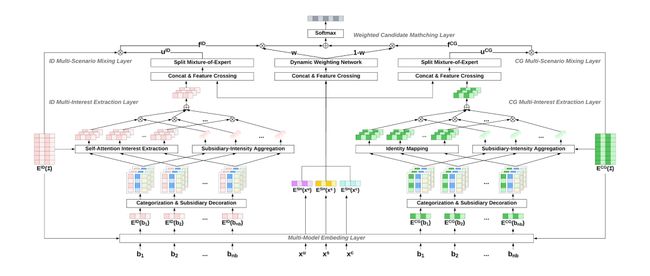
图 2:M5 的整体模型结构。其中 b1, b2, … 代表用户的观看行为特征。xu, xs, xc 分别表示用户、场景和上下文特征。EID 和 ECG 表示 ID 和 CG 的 embedding table。

embedding 层主要将稀疏特征转换为低维稠密向量。与大多数的召回系统不同,M5 利用 Disney 流媒体服务中丰富的元信息为每个视频生成了对应的 cg embedding,作为对仅从用户行为日志训练的普通 id embedding 的补充。
多模态 embedding:多模态 embedding 作用于行为特征和目标特征,它将每个剧集id 映射到 id embedding 和 cg embedding。id embedding 是通过随机初始化或者从先前的增量结果生成的,这种方法在工业界使用广泛。与之相比,cg embedding 由一个预训练的基于内容增量更新的 内容关系图初始化。图节点包含 id、标签、演员信息、视觉信息和文本信息,每个节点表示特定的模态,且 id 节点会和对应的元信息节点连接。为了更好地利用视觉信息和文本信息,我们使用预训练的模型生成视觉和文本表示 [13,14]。M5 采用经典的 word2vec [15] 以及 GraphSAGE [16] 训练关系图的 embedding。我们也尝试了一些新方法 [17],但没能带来进一步的效果提升。
共享 embedding:共享 embedding 负责处理除 剧集 id 之外的特征,它和普通的 embedding 操作没有任何区别。

多兴趣抽取层根据用户的行为特征生成聚合的表示。为了明确地描述用户粗粒度和细粒度的偏好,M5 将用户的行为分类,并在每个行为上面附加辅助特征进行更精确地刻画。M5使用 self-attention以及subsidiary-intensity (SIN)模块处理 id embedding。为了保留 content graph 中的元信息,M5 只使用 SIN 模块对 cg embedding 聚合。
行为分类和辅助特征:Disney 流媒体平台会为用户提供点播剧集,点播电影以及直播内容。根据离线的数据分析,我们发现用户对这些类别的兴趣是完全不同的。例如,经常观看 NCAA 和 NBA 直播的用户并不会经常观看 点播 的体育剧集或电影。因此,M5 显式地将用户行为按照类别分桶以刻画用户的粗粒度兴趣。除此之外,M5 还在每个行为上添加辅助特征,以捕捉用户的细粒度兴趣。具体来说,M5 记录剧集 级别的“剧集观看次数”、“播放时长”辨别每个用户行为的强度,同时抽取“上次观看到现在的时长”描绘行为的序列信息以及新鲜度。
Self-Attention 多兴趣抽取:M5 在 id embedding 的行为序列上采用多层双向 Transformer [18] 提取用户的多样化兴趣并捕获序列内的复杂关系。由于 Transformer 在业界被广泛使用,我们在这里不描述它的模型结构,具体细节可以参考原论文 [18]。我们在这里想探讨的是 self-attention 在推荐模型中正确的使用姿势。在刚开始尝试 self-attention 模型的时候,我们发现效果并没有想象中的明显。之后,我们试图通过 scaling 提升模型效果,结果发现模型变宽变深反而导致性能下降。熟悉 CV 和 NLP 的读者应该对这种情况非常意外,因为将模型变大(尤其是 Transformer)在 CV 和 NLP 领域是提升性能的一种通用范式。通过对比推荐模型和其它领域的模型结构,我们猜测是 self-attention 部分没有得到充分的训练才导致了上述的反常现象。因此,我们在 self-attention 的输出上添加了一个 Masked-language-Modeling (MLM) [14] 的辅助 loss 增加训练信号。更准确的说,在每个输入序列上,我们随机 mask 掉一部分的用户行为,并在 self-attention 模块的输出端对这些 mask 的位置进行重建。使用这个技巧之后,我们发现 self-attention 的性能得到了显著的提升,且 scaling 策略也能为模型带来持续的优化。
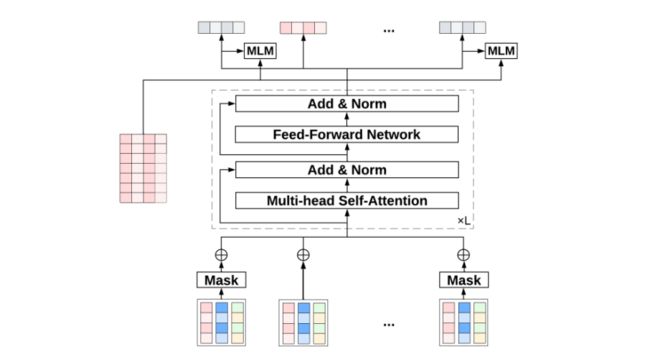
图 3:Self-Attention 多兴趣抽取模块
Subsidiary-Intensity 兴趣聚合:SIN 模块参考了 DIN 的 local activation unit [19],使用 point-wise 的注意力机制为每个行为打分。SIN 对每一个行为的剧集 embedding 和辅助特征的 embedding 做特征交叉,并和原始特征一起放入 MLP 生成兴趣打分。其中,MLP 的最后一层使用指数激活层,以保证打分语义上的非负性。同时,SIN 使用全0初始化 MLP 的最后一层,这样在初始时所有的打分结果都等于1,从而允许网络在训练过程中逐渐地学习到每个行为的重要性。对于 id 通道,SIN 模块作用于 self-attention 基于 id embedding 的输出结果;对于 cg 通道,SIN 的结果会直接作用在原始的 cg embedding 上面,这样可以保留足够的元信息。

图 4:Subsidiary-Intensity 兴趣聚合模块
为了更好地适应 Disney 流媒体中天然的多场景属性,M5 在多场景融合层使用 SMoE 以及场景id辨别场景之间的异同,并通过 disagreement loss 鼓励专家的多样性。SMoE 是 MMoE 模型[20]的一种拓展。为了更好地学习不同场景的区别,我们直接将场景 id 作为特征加入到网络的输入,并通过内积的形式将其和其他特征做交叉以捕捉高阶的语义。根据得到的输入特征,我们利用 MoE 的专家网络学习场景之间的通用知识,并通过门控单元控制专家结果的使用。SMoE 为每个场景保留不同的门控子网络以及后处理子网络,以更好地区分场景之间的差别。同时,为避免专家网络学习相同或者相似的语义特征,M5 还借鉴了 disagreement loss 对专家进行约束[21]。多场景融合并行地作用在双通道的行为序列上,最终得到基于id和cg的 user embedding。

图 5:SMoE 模型结构

为了充分利用目标测的多模态信息,我们使用动态加权层计算最终的用户对视频的偏好。对于 id 和 cg 的 user embedding 以及候选集合的 id 和 cg 的 item embedding,M5 分别计算基于 id 和 cg 的用户-视频打分:
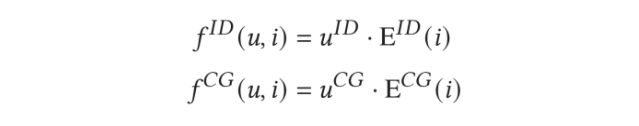
之后,M5 会根据用户相关特征计算 id, cg 打分的权重,并对结果进行加权平均:
![]()
M5 从形式上可以被看作是一种特殊的多路(通道)召回。但是与普通的多路召回不同,M5 并行地建模多模态(多通道)预测结果,并基于动态加权得到唯一的混合打分进行检索。这种做法比普通的多路召回更平滑且准确,且能够在不同通道间共享知识和参数。值得注意的是,M5 也能够作用于大规模候选集合的场景。一种最简单的做法是把计算出来的动态权重直接乘到对应的 user embedding 上面,然后基于 ANN 或者 MIPS 对 item 进行检索。可以证明,这种检索方式和直接计算每一个 item 的打分是等价的。

我们在 Disney+ 和 Hulu 平台分别收集了一个月的数据做训练和评估。对于 Hulu,它的多场景表现在用户的订阅类型(点播、直播)以及样本的来源上(优化场景内部样本和优化场景外部样本)。对于 Disney+,它的多场景表现在来自不同国家和地区的用户上。
我们比较了一些业界常用的方法 [1,22-25],并使用 Hit Ratio (HR) 评估模型的离线结果。显然,M5 大幅超过了所有的对比方法,在 Hulu/Disney+ 的所有场景下都实现了超过 10%/5% 的HR 提升,证明了多模态多兴趣多场景技术对 Disney 流媒体召回的重要性。此外,多模态、多兴趣和多场景建模的设计都能够改进推荐性能,并提供近乎正交的提升。
更具体地,由于平台中的用户行为刻画了最精准的用户信息,多兴趣抽取对两个场景都很关键。多场景技术能够为 Hulu 场景带来很大的指标提升( Scenario 2 和 4),这是因为 Hulu 的点播和直播订阅用户行为差异很大。与之相比,在给定特征下,Disney+ 不同地区的用户意图并没有很明显的差异。此外,尽管 id embedding 能够在大规模流媒体平台得到充分的训练,多模态 embedding 所带来的元信息仍然稳定地提升模型的召回能力。
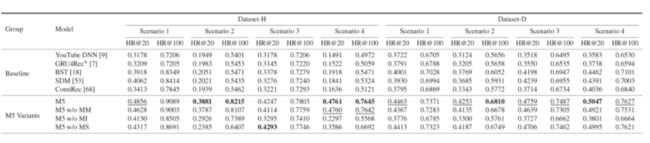
表 1:M5 在 Hulu 和 Disney+ 的离线实验结果

我们通过Disney流媒体的在线实验平台将 M5 部署到Hulu和Disney+最热门的For You集合上面进行在线 A/B 实验。我们使用 HPV (hours per visitor,平均用户观看时长) 衡量模型的在线性能,因为它与我们最终的商业目标息息相关。在Hulu场景下,线上的 baseline 是一个基于大量特征工程的 Youtube DNN;在Disney+场景下,线上的 baseline是一个基于变分自动编码器的模型。可以看到,M5在各种场景下都显著超越了 baseline 方法。M5 已经在Hulu和 Disney+ 全量上线,为业务增长持续地做出贡献。
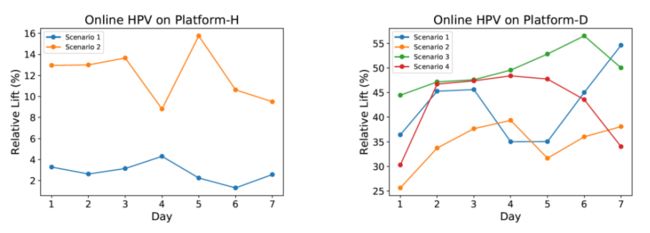
图 6:M5 在 Hulu 和 Disney+ 的在线实验结果。

Pengyu Zhao,内容发现部门高级算法工程师
内容发现部门(Content Discovery Org.)是迪士尼流媒体核心研发部门,主攻Hulu、Disney+、Star+等迪士尼流媒体产品线的三大业务方向:搜索、个性化推荐、内容推广。在每个业务方向上都和人工智能技术深度融合,涉及AI平台的搭建、前沿算法的研究、以及工程系统的集成,致力于为迪士尼流媒体用户提供最佳的视频观看体验。
自成立伊始,该部门始终将内容的精准传递作为首要业务目标,深入结合工程、算法和数据,利用人才优势与人工智能基础解决业务问题。

职位信息: 职位列表链接
感兴趣的同学发送简历至:[email protected]
(烦请标注申请职位+姓名)


[1] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems. 191–198
[2] Zhe Wang, Liqin Zhao, Biye Jiang, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2020. COLD: Towards the Next Generation of Pre-Ranking System. arXiv preprint arXiv:2007.16122 (2020).
[3] James Davidson, Benjamin Liebald, Junning Liu, Palash Nandy, Taylor Van Vleet, Ullas Gargi, Sujoy Gupta, Yu He, Mike Lambert, Blake Livingston, et al. 2010. The YouTube video recommendation system. In Proceedings of the fourth ACM conference on Recommender systems. 293–296.
[4] Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web. 285–295.
[5] Chao Li, Zhiyuan Liu, MengmengWu, Yuchi Xu, Huan Zhao, Pipei Huang, Guoliang Kang, Qiwei Chen,Wei Li, and Dik Lun Lee. 2019. Multi-interest network with dynamic routing for recommendation at Tmall. In Proceedings of the 28th ACM international conference on information and knowledge management. 2615–2623.
[6] Xinyang Yi, Ji Yang, Lichan Hong, Derek Zhiyuan Cheng, Lukasz Heldt, Aditee Kumthekar, Zhe Zhao, Li Wei, and Ed Chi. 2019. Sampling bias-corrected neural modeling for large corpus item recommendations. In Proceedings of the 13th ACM Conference on Recommender Systems. 269–277.
[7] Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence 33, 1 (2010), 117–128.
[8] Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with gpus. IEEE Transactions on Big Data 7, 3 (2019), 535–547.
[9] Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE transactions on pattern analysis and machine intelligence 42, 4 (2018), 824–836.
[10] Marius Muja and David G Lowe. 2014. Scalable nearest neighbor algorithms for high dimensional data. IEEE transactions on pattern analysis and machine intelligence 36, 11 (2014), 2227–2240.
[11] Jizhe Wang, Pipei Huang, Huan Zhao, Zhibo Zhang, Binqiang Zhao, and Dik Lun Lee. 2018. Billion-scale commodity embedding for e-commerce recommendation in alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 839–848.
[12] Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. 2019. MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. In Proceedings of the 27th ACM International Conference on Multimedia. 1437–1445.
[13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
[14] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 4171–4186.
[15] Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space." arXiv preprint arXiv:1301.3781 (2013).
[16] Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. Advances in neural information processing systems 30 (2017).
[17] Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. 2018. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 974–983.
[18] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 6000–6010.
[19] Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence. 5941–5948.
[20] Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1930–1939.
[21] Jian Li, Zhaopeng Tu, Baosong Yang, Michael R Lyu, and Tong Zhang. 2018. Multi-head attention with disagreement regularization. arXiv preprint arXiv:1810.10183 (2018).
[22] Balázs Hidasi and Alexandros Karatzoglou. 2018. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM international conference on information and knowledge management. 843–852.
[23] Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. 2019. Behavior sequence transformer for e-commerce recommendation in Alibaba. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data. 1–4.
[24] Fuyu Lv, Taiwei Jin, Changlong Yu, Fei Sun, Quan Lin, Keping Yang, and Wilfred Ng. 2019. SDM: Sequential deep matching model for online large-scale recommender system. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2635–2643.
[25] Yukuo Cen, Jianwei Zhang, Xu Zou, Chang Zhou, Hongxia Yang, and Jie Tang. 2020. Controllable multi-interest framework for recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2942–2951.