使用YOLOX训练自己的数据集
文章目录
-
- 环境准备
- 数据集准备
- 安装YOLOX
- 修改配置文件
-
- 修改检测类别
- 修改训练参数
- 修改训练数据集路径
- 修改Voc.py文件中Annotations文件的读取格式
- 训练
-
- 修改train.py
- 查看实时训练情况
- 检测
环境准备
需要:pytorch>=1.7
去官网查看对应的CUDA版本号:https://pytorch.org/get-started/previous-versions/,我的CUDA是10.2的
conda create -n torch1.7.0 python=3.7 #创建新环境
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.2
在github下载模型权重到YOLOX 文件夹下(用chrome中的github加速插件可快速下载权重文件)
数据集准备
自定义数据集的目录结构
- datasets
- VOCdevkit
- VOC2021 (自定义)
- Annotations
- ImageSets
- Main
- test.py
- train.py
- val.py
- trainval.py
- JPEGImages
生成.txt文件内容的代码
import os
import random
random.seed(0)
xmlfilepath='VOC数据集Annotations文件夹路径'#xml文件存放地址,在训练自己数据集的时候,改成自己的数据路径
saveBasePath="VOC数据集ImageSets/Main文件夹路径"#存放test.txt,train.txt,trainval.txt,val.txt文件路径
#----------------------------------------------------------------------#
# 根据自己的需求更改trainval_percent和train_percent的比例
#----------------------------------------------------------------------#
trainval_percent=0.9
train_percent=1
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
安装YOLOX
git clone [email protected]:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -U pip && pip3 install -r requirements.txt
python3 setup.py develop
pip3 install cython; pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
修改配置文件
修改检测类别
YOLOX/yolox/data/datasets/voc_classes.py,各个类别之间必须用逗号隔开,最后一个类别后也必须加逗号
VOC_CLASSES = (
"fire",
)
修改训练参数
修改YOLOX/yolox/exp/yolox_base.py文件下的相关参数
- self.num_classes:检测类别个数
- self.depth:YOLOX/exps/default文件夹下,选择需要的.py文件中的self.depth
- self.width:YOLOX/exps/default文件夹下,选择需要的.py文件中的self.width

- self.max_epoch: epoch,改成了100
- self.print_interval、self.eval_interval:原来的代码是10个eopch做一个验证,可以修改为每迭代一个epoch做一个验证,以及时看到效果。

我的检测类别只有一类,self.depth 和 self.width 用的yolox.py中的数
class Exp(BaseExp):
def __init__(self):
super().__init__()
# ---------------- model config ---------------- #
self.num_classes = 1
self.depth = 1.33
self.width = 1.25
self.act = 'silu'
修改训练数据集路径
修改YOLOX/exps/example/yolox_voc/yolox_voc_s.py
- self.num_class:检测类别个数
- self.depth:YOLOX/exps/default文件夹下,选择需要的.py文件中的self.depth
- self.width:YOLOX/exps/default文件夹下,选择需要的.py文件中的self.width
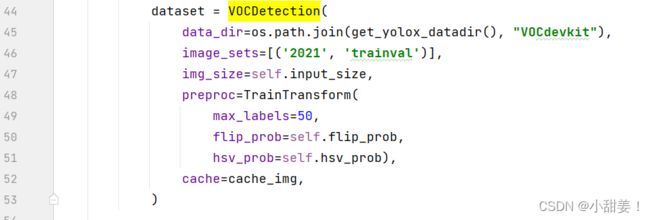
- get_data_loader方法中的VOCDetection的image_sets修改为
image_sets=[('2021', 'trainval')]
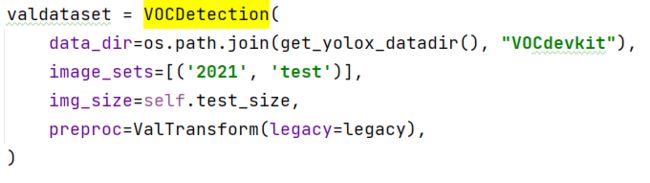
- get_eval_loader方法中的VOCDetection的image_sets修改为
image_sets=[('2021', 'test')]
修改Voc.py文件中Annotations文件的读取格式
修改YOLOX/yolox/data/datasets/voc.py
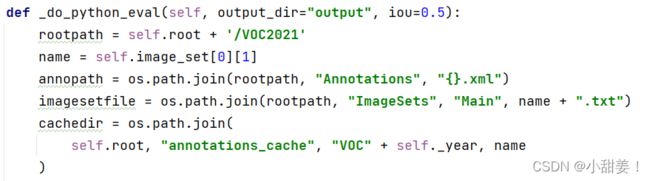
- _do_python_eval方法下的annopath修改为
annopath = os.path.join(rootpath, "Annotations", "{}.xml") - rootpath修改为
rootpath = self.root + '/VOC2021'
训练
修改train.py
YOLOX/tools/train.py
- 修改所使用的模型。要使用哪个模型,写哪个模型的名称
parser.add_argument("-n", "--name", type=str, default='yolox-x', help="model name")
- 修改batch_size
parser.add_argument("-b", "--batch-size", type=int, default=4, help="batch size")``` - 修改devices参数,只有一张显卡,所以设置为0,如过有多张卡,想指定用某张卡,比如1卡,则:
CUDA_VISIBLE_DEVICES=1 python train.pyparser.add_argument( "-d", "--devices", default=0, type=int, help="device for training" ) - 修改exp_file的default为yolox_voc_s.py的绝对路径
parser.add_argument( "-f", "--exp_file", default='YOLOX/exps/example/yolox_voc/yolox_voc_s.py', type=str, help="plz input your experiment description file", ) - 若使用预训练权重,将ckpt的default修改为模型权重的路径
开始训练:parser.add_argument("-c", "--ckpt", default='/YOLOX/yolox_x.pth', type=str, help="checkpoint file")python train.py查看实时训练情况
进入到YOLOX/tools/YOLOX_outputs/yolox_voc_s目录下,输入tensorboard --logdir=./ --host= 127.0.0.1(在本地训练时可用),如果是在服务器上进行训练的话:
Linux系统:
在登录远程服务器的时候使用命令:
ssh -L 16006:服务器ip地址:6006 [email protected]
(代替一般ssh远程登录命令:ssh [email protected])
训练完模型之后使用如下命令:
tensorboard --logdir /home/XX/YOLOX/tools/YOLOX_outputs/yolox_voc_s/ --bind_all
最后,在本地访问地址:http://127.0.0.1:16006/
原理:
建立ssh隧道,实现远程端口到本地端口的转发 具体来说就是将远程服务器的6006端口(tensorboard默认将数据放在6006端口)转发到本地的16006端口,在本地对16006端口的访问即是对远程6006端口的访问,当然,转发到本地某一端口不是限定的,可自由选择。
检测
修改 YOLOX/tools/demo.py
- 修改1:
from yolox.data.datasets import voc_classes # 引入voc文件对应的类 predictor = Predictor(model, exp, voc_classes.VOC_CLASSES, trt_file, decoder, args.device) cls_names=voc_classes.VOC_CLASSES - 选择测试的是图片还是视频
parser.add_argument( "demo", default="image", help="demo type, eg. image, video and webcam" ) - 输入需要测试的图片/视频的路径
parser.add_argument( "--path", default="YOLOX/datasets/VOCdevkit/VOC2021/JPEGImages/0ce61215-6d34-49f9-aa6d-5f0feed430f8.jpg", help="path to images or video" ) - 修改exp_file的default为yolox_voc_s.py的绝对路径
parser.add_argument( "-f", "--exp_file", default='YOLOX/exps/example/yolox_voc/yolox_voc_s.py', type=str, help="pls input your experiment description file", ) - 修改训练完成后模型的地址
parser.add_argument("-c", "--ckpt", default='YOLOX/tools/YOLOX_outputs/yolox_voc_s/latest_ckpt.pth', type=str, help="ckpt for eval") - 使用GPU加速
parser.add_argument( "--device", default="gpu", type=str, help="device to run our model, can either be cpu or gpu", )