从局部到全局的多模式电影场景分割
从局部到全局的多模式电影场景分割 CVPR2020
- 个人总结
-
- 1.研究现状:
- 2.研究的意义:
- 3.提出的解决方案(局部到全局的场景分割模型):
- 4.电影场景数据集:
- 5.结论:
- 全文翻译
- 从局部到全局的多模式电影场景分割方法
-
- 摘要
- 1.介绍
- 2.相关工作
- 3.电影场景数据集
-
- 3.1场景定义
- 3.2注释工具和步骤
- 3.3批注统计
- 4.局部到全局的场景分割
-
- 4.1带有语义元素的镜头表示
- 4.2clip级别的镜头边界表示
- 4.3segment级别的粗略预测
- 4.4movie级别的全局最佳分组
- 实验
-
- 5.1实验建立
- 5.2定量结果
- 5.3消融研究
- 5.4定性结果
- 5.5跨数据集传输
- 6.结论
个人总结
1.研究现状:
对于电影场景分割,最早的作品采用的是无监督的方法。例如,根据镜头相似度对镜头进行聚类;绘制低级视觉特征的镜头响应曲线进行阈值分割;使用快速全局k均值算法的光谱聚类进行镜头分组;缺点是,方法不灵活,严重依赖手动设置的不同视频的参数。
有监督的方法,建立新的数据集。IBM OVSD、BBC Planet Earth,缺点是,数据集中的视频缺少丰富的情节或故事情节,测试视频的数量如此少,不能反应出各种场景方法的有效性。以镜头为分析单元,没有考虑场景中的语义信息。
图像和短视频中的场景理解。缺少周围的上下文信息,并且短视频没有足够的时间和地点的变化。重要的是,这些作品假定了一系列可区分的预定义类别。但是,对于电影场景分割,不可能有这样的类别列表。
较长视频中的场景理解。很少有数据集关注长视频中的场景,大多数都集中于演员活动的定位和分类。
2.研究的意义:
识别电影场景,包括场景边界的检测和对场景内容的理解,有助于广泛的电影理解任务,例如场景分类、跨电影场景检索、人际互动图和以人为中心的故事情节的建设。
难点,场景的多变性,尽管场景通常发生在固定的位置,但场景可能在多个位置之间穿越,例如在电影的战斗场景中,人物从室内移动到室外,这些复杂的场景纠缠在检测高级语义信息的场景时增加了难度。
3.提出的解决方案(局部到全局的场景分割模型):
在三个级别对场景进行分割,即clip、segment、movie,集成了多模式的信息,可以从电影中提取出复杂的语义信息,为场景分割提供了自上而下的指导。
1)关注场景的边界,使用监督的方法了解场景之间边界的内容,获得区分场景内和跨场景过渡的能力。
2)镜头的特征表示,使用四个特征去表示一个镜头,分别是place、cast、action和audio。通过镜头之间的相似性去判断两个镜头之间的关系。
在关键帧图像上的Places数据集训练ResNet去获取place特征。
在CIM数据集上训练Fast-RCNN进行检测cast实例,在PIPA数据集上训练ResNet去提取cast特征。
在AVA数据集上训练TSN去获取action特征。
在AVAActiveSpeaker数据集上训练NaverNet去分离场景的语音和背景声音,stft在镜头中获取audio特征。
3)Clip级别,对镜头边界的表示。场景分割公式化为镜头边界上的二分类问题,提出一个边界网络BNet对镜头边界进行建模,输入镜头,通过捕获前后两个镜头的差异和关系,去确定两者的边界,输出镜头的边界。
4)Segment级别,基于镜头边界进行粗略预测场景的边界。获得镜头边界的序列后,通过局部序列模型,例如Bi-LSTM,去预测粗略的场景边界得分,即镜头边界成为场景边界的概率,然后使用阈值进行二值化,场景边界是镜头边界的子集。
5)Movie级别,结合全局上下文信息进行最佳场景分割。粗略的场景边界仅仅考虑了局部的镜头信息,而忽略了全局的上下文信息。使用全局最佳模型G来考虑movie级的上下文。将粗略的场景集进行最佳合并,将局部不相关的粗略场景进行合并,形成最佳的最优的场景切换集。即通过数学建模出两个子超级镜头之间的相关性得分,得出一个最佳的合并场景集使得相关性得分总和最大。
4.电影场景数据集:
为了促进场景理解,构造了数据集MovieScenes,其中包含了21K个场景,是通过对150部电影中的270K个镜头分组得出的。与其他现有的数据集相比,MovieScenes规模巨大,镜头数量多,总持续时间长,涵盖了更广泛的数据源,拥有各种场景。涵盖了种类繁多的流派,包括戏剧、惊悚片、动作片,使得数据集更加全面和通用。带注释的场景长度从10s到120s不等,提供了较大的可变性。
5.结论:
在这项工作中,我们收集了一个大型注释集,用于对包含270K注释的150部电影进行场景分割。我们提出了一个局部到全局场景分割框架,以覆盖分层的时间和语义信息。实验表明,该框架非常有效,并且比现有方法具有更好的性能。
全文翻译
从局部到全局的多模式电影场景分割方法
Anyi Rao1, Linning Xu2, Yu Xiong1, Guodong Xu1, Qingqiu Huang1, Bolei Zhou1, Dahua Lin1 1CUHK - SenseTime Joint Lab, The Chinese University of Hong Kong 2The Chinese University of Hong Kong, Shenzhen {anyirao, xy017, xg018, hq016, bzhou, dhlin}@ie.cuhk.edu.hk, [email protected]
摘要
场景是电影中讲故事的重要单元,它包含演员的复杂活动及其在物理环境中的互动。 识别场景的组成是迈向电影语义理解的关键一步。与在传统视觉问题中研究的视频相比,这是非常具有挑战性的,例如动作识别,因为电影中的场景通常包含更丰富的时间结构和更复杂的语义信息。为了实现这一目标,我们通过构建大型视频数据集MovieScenes来扩大场景分割任务,该视频数据集包含来自150部电影的21K带注释的场景片段。我们进一步提出了一个局部到全局场景分割框架,该框架在三个级别(即clip,segment和movie)上集成了多模式信息。该框架能够从长片电影的分层时间结构中提取出复杂的语义,从而为场景分割提供了自上而下的指导。我们的实验表明,所提出的网络能够以较高的精度将电影分割成场景,并且始终优于以前的方法。我们还发现,对MovieScenes进行预训练可以对现有方法进行重大改进。
1.介绍
想象一下,您正在看汤姆·克鲁斯(Tom Cruise)主演的电影《碟中谍》:在战斗现场,伊桑(Ethan)跳上直升机的着陆滑道,并在挡风玻璃上贴上了爆炸胶,以摧毁敌人。突然,这个故事跳入一个激动人心的场景,在此,伊桑(Ethan)扣动扳机,为挽救妻子朱莉娅(Julia)牺牲了生命。如此戏剧性的场景变化在电影的故事讲述中起着重要作用。一般来说,电影是由精心设计的一系列有趣的场景组成的,带有过渡效果,其中基本的故事情节决定了所呈现场景的顺序。因此,识别电影场景,包括场景边界的检测和对场景内容的理解,有助于实现广泛的电影理解任务,例如场景分类,跨电影场景检索,人际互动图和以人为中心的故事情节的建设。

图1.当我们查看图(a)中的任何单个镜头时,例如B镜头中的女人,我们无法推断当前事件是什么。如图(b)所示,只有当我们考虑了该场景中的所有镜头1-6时,我们才能认识到“这个女人正在邀请一对夫妇与乐队跳舞”。
值得注意的是,场景和镜头本质上是不同的。通常,镜头是在不间断的时间内进行拍摄的,因此是连续的。场景是更高层次的语义单元。如图1所示,一个场景包括一系列镜头,以呈现故事中语义上连贯的部分。因此,尽管可以使用现有工具根据简单的视觉提示将电影轻松地划分为镜头[23],但是识别构成场景的镜头子序列的任务是一项艰巨的任务,因为需要顺序地进行语义理解发现这些镜头之间的关联在语义上是一致的,但实际上是不相似的。
关于视频理解已经进行了广泛的研究。尽管在这一领域取得了长足的进步,但是大多数现有的作品都集中在从短视频中识别某些活动的类别[28,6,14]。更重要的是,这些作品假定了一系列可区分的预定义类别。但是,对于电影场景分割,不可能有这样的类别列表。 另外,根据镜头的语义连贯性将镜头分为场景,而不仅仅是视觉提示。因此,为此需要开发一种新方法。
要关联视觉上不同的镜头,我们需要有一定的了解。这里的关键问题是“没有类别标签,我们如何学习语义?” 我们解决这个问题的想法包括三个方面:
1)我们不尝试对内容进行分类,而是关注场景边界。我们可以通过监督的方式了解构成场景之间边界的内容,从而获得区分场景内和跨场景过渡的能力。
2)我们利用包含在多个语义元素中的线索,包括place,cast,action和audio,来识别镜头之间的关联。通过整合这些方面,我们可以超越视觉观察,更有效地建立语义联系。
3)我们还将从对电影的整体理解中探索自上而下的指导,这将进一步提高性能。
基于这些想法,我们开发了一个局部到全局框架,该框架通过三个阶段执行场景分割:
①从多个方面提取镜头表示;
②根据集成信息进行局部预测;
③最后优化通过解决全局优化问题对镜头进行分组。
为了促进这项研究,我们构建了MovieScenes,这是一个大型数据集,其中包含超过21K的场景,其中包含来自150部电影的270,000张快照。
实验表明,与现有的最佳方法相比,我们的方法将性能提高了68%(以平均精度从28.1提高到47.1)[1]。在我们的数据集上进行预训练的现有方法在性能上也有很大的提高。
2.相关工作
场景边界检测和分割。最早的作品采用了多种无监督的方法。[22]根据镜头颜色相似度对镜头进行聚类。在[17]中,作者绘制了来自低级视觉特征的镜头响应曲线,并设置了剪切场景的阈值。[4,3]使用带有快速全局k均值算法的光谱聚类进一步对镜头进行分组。[10,24]通过优化预定义的优化目标,通过动态编程来预测场景边界。研究人员还求助于其他模态信息,例如 [13]利用HMM脚本,[23]使用低级视觉和音频功能构建场景过渡图。这些无监督的方法不灵活,并且严重依赖手动设置不同视频的参数。
研究人员转向有监督的方法,并开始建立新的数据集。IBM OVSD [21]由21个短视频组成,场景粗糙,可能包含多个情节。BBC Planet Earth [1]来自BBC纪录片的11集。[15]从Places205 [31]生成综合数据。但是,这些数据集中的视频缺少丰富的情节或故事情节,因此限制了其在现实世界中的应用。测试视频的数量如此之小,以至于不能反映出考虑各种场景的方法的有效性。另外,他们的方法以镜头为分析单元,并在局部区域中递归实现场景分割。 由于他们没有考虑场景中的语义,因此很难学习高级语义并获得理想的结果。
图像和短视频中的场景理解。基于图像的场景分析[31,29,9]可以推断出一些有关场景的基础知识,例如该图像中包含什么。但是,很难从单个静态图像中分辨出该动作,因为它缺少周围的上下文信息。几秒钟长的短视频进一步研究了动态场景理解[6,14]。但是,与长视频相比,所有这些视频都拍摄的单次拍摄视频没有足够的变化来捕捉时间和地点的变化。
较长视频中的场景理解。很少有数据集关注长视频中的场景。大多数可用的长视频数据集都集中于识别电影或电视连续剧中的演员[2、12、16]以及对活动进行定位和分类[8]。 MovieGraphs [26]专注于电影中的各个场景剪辑以及场景的语言结构。场景之间的某些过渡部分将被丢弃,从而使信息不完整。
为了实现可以扩展到长时间视频的更通用的场景分析,我们使用大型MovieScenes数据集解决了电影中的场景分割问题。我们提出了一个框架,该框架使用多个语义元素同时考虑了局部镜头之间的关系和全局场景之间的关系,从而获得了更好的分割结果。
3.电影场景数据集
为了促进电影中的场景理解,我们构造了MovieScenes,这是一个大型场景分割数据集,其中包含21K个场景,这些场景是通过对150部电影中的270K镜头进行分组而得出的。该数据集为研究场景中的复杂语义提供了基础,并促进了对场景顶部进行基于情节的长视频理解。
3.1场景定义
按照场景[17、4、10、24]的先前定义,场景是基于情节的语义单元,在一组特定的角色之间发生的一种确切的活动。尽管场景通常发生在固定的位置,但场景可能连续在多个位置之间穿越,例如在电影的战斗场景中,人物从室内移动到室外。这些复杂的场景纠缠在准确检测需要高级语义信息的场景时增加了难度。图2展示了MovieScenes中带注释的场景的一些示例,证明了这一困难。
 图2.电影Bruce Almight(2003)中带注释的场景示例。底部的蓝线对应于整个电影时间线,其中深蓝色和浅蓝色区域表示不同的场景。在场景10中,角色在两个不同的地方打了电话,因此需要对该场景进行语义理解,以防止将其归类为不同的场景。在场景11中,由于此现场广播场景涉及三个以上位置和角色组,因此任务变得更加困难。在这种情况下,视觉提示仅可能失败,因此包含其他方面(例如音频提示)变得至关重要。
图2.电影Bruce Almight(2003)中带注释的场景示例。底部的蓝线对应于整个电影时间线,其中深蓝色和浅蓝色区域表示不同的场景。在场景10中,角色在两个不同的地方打了电话,因此需要对该场景进行语义理解,以防止将其归类为不同的场景。在场景11中,由于此现场广播场景涉及三个以上位置和角色组,因此任务变得更加困难。在这种情况下,视觉提示仅可能失败,因此包含其他方面(例如音频提示)变得至关重要。
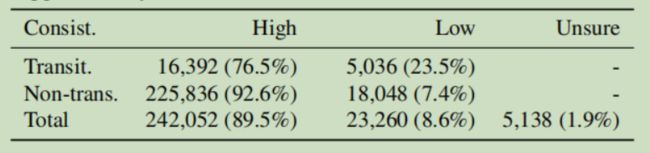
电影场景的多样性使注释者难以相互遵守。为了确保来自不同注释的结果的一致性,在注释过程中,我们提供了歧义示例的列表,并提供了具体的指导以阐明应如何处理此类情况。 此外,所有数据均由不同的注释者独立多次注释。最后,我们提供的多次批注和指导提供了高度一致的结果,即总计89.5%的高度一致性案例,如表1所示。
表1. MovieScenes的数据一致性统计信息。我们根据注释者的一致性将所有注释分为三类:高/低一致性情况和不确定情况。不确定的案例在我们的实验中被丢弃。更多详细信息在补充材料中指定。
3.2注释工具和步骤
我们的数据集包含150部电影,如果注释者一帧一帧地浏览电影,这将是一项艰巨的工作。我们采用基于镜头的方法,前提是应该始终将镜头唯一地分类为一个场景。因此,场景边界必须是所有镜头边界的子集。对于每部电影,我们首先使用现成的方法将其分为镜头[23]。这种基于镜头的方法大大简化了场景分割任务,并加快了注释过程。我们还开发了基于Web的注释工具,以方便注释。所有注释者都经过两轮注释过程,以确保高度一致性。在第一轮中,我们将电影的每个块分配给三个独立的注释器,以供以后进行一致性检查。在第二轮中,不一致的注释将重新分配给两个附加的注释器,以进行额外的评估。
3.3批注统计
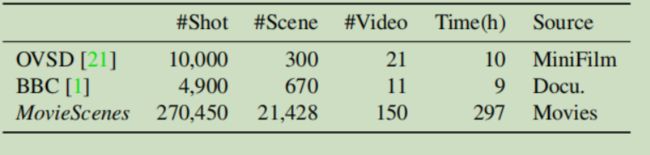
大规模。表2比较了MovieScenes和现有的相似视频场景数据集。我们显示,在镜头/场景数量和总持续时间方面,MovieScenes明显大于其他数据集。此外,与短片或纪录片相比,我们的数据集涵盖了更广泛的各种数据源,可以捕获各种场景。
多样性。我们数据集中的大多数电影具有90到120分钟的持续时间,可提供有关各个电影故事的丰富信息。涵盖了种类繁多的流派,包括最流行的流派,例如戏剧,惊悚片,动作片,使我们的数据集更加全面和通用。带注释的场景的长度从少于10s到大于120s不等,多数情况持续10到30s。Movie级别和scene级别都存在这种较大的可变性,这使得电影场景分割任务更具挑战性。
表2.现有场景数据集的比较。
4.局部到全局的场景分割
如上所述,场景是一系列连续的镜头。因此,可以将场景分割公式化为二分类问题,即确定镜头边界是否是场景边界。但是,此任务并不容易,因为分割场景需要识别多个语义方面并使用复杂的临时信息。
为了解决这个问题,我们提出了一个局部到全局场景分割框架(LGSS)。模拟的整体过程如公式1所示。具有n个镜头的电影被表示为镜头序列[s1,…,sn],其中每个镜头都具有多个语义方面。我们基于镜头表示si设计一个三级模型来合并不同级别的上下文信息,即cilp级别(B),segment级别(T)和movie级别(G)。
我们的模型给出了一系列预测[o1,···,on-1],其中oi∈{0,1}表示第i个镜头和第(i + 1)个镜头之间的边界是否是场景边界。
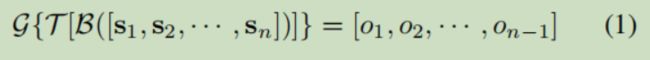 在本节的以下部分中,我们将首先介绍如何获取si,即如何使用多个语义元素来表示镜头。然后我们将说明模型三个层次的详细信息,即B,T和G。总体框架如图3所示。
在本节的以下部分中,我们将首先介绍如何获取si,即如何使用多个语义元素来表示镜头。然后我们将说明模型三个层次的详细信息,即B,T和G。总体框架如图3所示。
 图3.局部到全局场景分割框架(LGSS)。在clip级别,我们为每个镜头提取四种编码,并使用BNet建模镜头边界。局部序列模型在segment级别输出粗糙的场景切换结果。最后,在movie级别,应用全局最佳分组来优化场景分割结果。
图3.局部到全局场景分割框架(LGSS)。在clip级别,我们为每个镜头提取四种编码,并使用BNet建模镜头边界。局部序列模型在segment级别输出粗糙的场景切换结果。最后,在movie级别,应用全局最佳分组来优化场景分割结果。
4.1带有语义元素的镜头表示
电影是一种典型的多模式数据,其中包含不同的高级语义元素。从神经网络的镜头中提取的全局特征在以前的工作中被广泛使用[1,24],但不足以捕获复杂的语义信息。
场景是一系列镜头共享一些常见元素的场景,例如place、cast等,因此,重要的是要考虑这些相关的语义元素,以更好地表示镜头。在我们的LGSS框架中,镜头用四个元素表示,它们在场景的构成中起着重要作用,即place,cast,action和audio。
为了获得每个镜头si的语义特征,我们利用:
1)在关键帧图像上的Places数据集[31]上预训练的ResNet50 [11]以获取place特征,
2)在CIM数据集[12]上预训练的Faster-RCNN [19]进行检测cast实例,在PIPA数据集[30]上预训练ResNet50以提取cast特征,
3)在AVA数据集[8]上预先训练的TSN [27]以获取action特征,
4)NaverNet [5]在AVAActiveSpeaker数据集[20]上进行了预训练,以分离语音和背景声音,stft [25]在具有16K Hz采样率和512窗口信号长度的镜头中分别获得其特征,并将它们连接起来以获得audio特征。
4.2clip级别的镜头边界表示
如前所述,场景分割可以公式化为镜头边界上的二分类问题。因此,如何表示镜头边界成为至关重要的问题。在这里,我们提出了一个边界网络(BNet)对镜头边界进行建模。如公式2所示,BNet(用B表示)以2wb镜头作为输入的电影clip,并输出边界表示bi。出于直觉,边界表示应同时捕捉镜头前后的差异和镜头之间的关系,BNet由两个分支Bd和Br组成。Bd由两个临时的卷积层建模,每个卷积层都在边界的前后都嵌入了镜头,然后进行内积运算去计算他们的差异。Br的目的是捕获镜头之间的关系,它是由一个临时卷积层紧跟着一个最大池化层实现的。
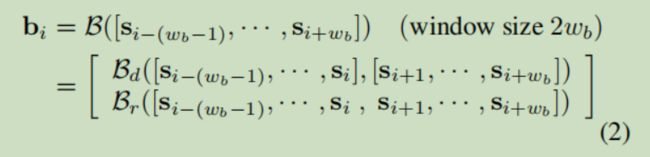
4.3segment级别的粗略预测
在获得每个镜头边界bi的代表之后,问题就变成了根据表示序列[b1,···,bn-1]的序列来预测序列二进制labels [o1,o2,···,on-1],可以通过序列到序列模型[7]解决。但是,镜头数量n通常大于1000,这对于现有的顺序模型很难保存这么长的内存。因此,我们设计了一个segment级模型,以基于包含wt镜头(wt≪ n)的电影片段来预测粗略结果。具体来说,我们使用序列模型T,例如Bi-LSTM [7],步幅为wt / 2,可预测一系列粗略得分[p1,…,pn-1],如式3所示。pi∈[0,1]是镜头边界成为场景边界的概率。

然后,我们得到了一个粗略的预测oi∈{0,1},该预测表明第i个镜头边界是否为场景边界。通过将pi通过阈值τ进行二值化,我们得到
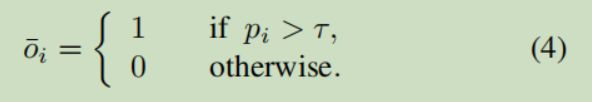
4.4movie级别的全局最佳分组
Segment级别模型T获得的分割结果o¯i不够好,因为它只考虑wt镜头的局部信息,而忽略了整个电影的全局上下文信息。为了捕获全局结构,我们开发了全局最佳模型G来考虑电影级上下文。它将镜头表示si和粗略预测o¯i作为输入,并做出如下最终决定oi,

全局最优模型G被公式化为一个优化问题。在介绍它之前,我们先建立超级镜头和目标函数的概念。
局部分割为我们提供了一个初始的粗糙场景剪切集C = {Ck},这里我们将Ck表示为超级镜头,即由segment级别结果[o¯1,…,,o¯n-1]确定的一系列连续镜头。我们的目标是将这些超级镜头合并为j个场景Φ(n = j)= {φ1,…,φj},其中
![]() 和|φk| ≥1。由于没有给出j,所以要自动确定目标场景编号j,我们需要查看所有可能的场景切换,即
和|φk| ≥1。由于没有给出j,所以要自动确定目标场景编号j,我们需要查看所有可能的场景切换,即![]() 。对于固定的j,我们想要找到最佳场景切换集
。对于固定的j,我们想要找到最佳场景切换集![]() 。总体优化问题如下:
。总体优化问题如下:

在此,g(φk)是由场景φk获得的最佳场景切换得分。它公式化了超级镜头Cl∈φk与其余超级镜头Pk,l =Φk\ Cl之间的关系。g(φk)构成两个项以捕获全局关系和局部关系,Fs(Ck,Pk)是Ck和Pk之间的相似性得分,而Ft(Ck,Pk)是一个指示函数,表明Ck与来自Pk的任何超级镜头之间是否有非常高的相似性,目的是在场景中建立镜头线程。特别,
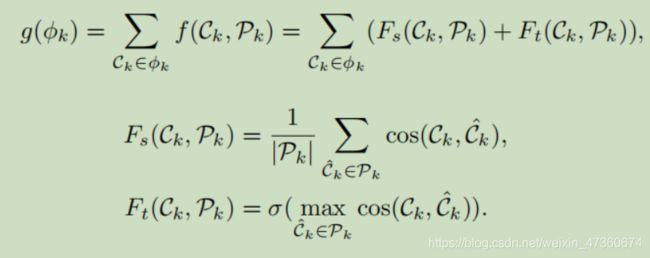
DP.通过动态编程(DP)可以有效地解决优化问题并确定目标场景编号。F(n = j)的更新是
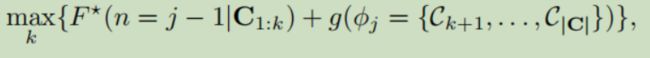
其中C1:k是包含前k个超级镜头的集合。
迭代优化。上面的DP可以给我们一个场景切换的结果,但是我们可以进一步将这个结果当作一个新的超级镜头集,并迭代地合并它们以改善最终结果。当超级镜头更新时,我们还需要更新这些超级镜头表示形式。对于所有包含的镜头进行简单的汇总对于超级镜头可能不是理想的表示,因为有些镜头包含的信息较少。因此,最好在最佳分组中优化超级镜头的表示。 补充中给出了有关超级镜头表示的这种改进的细节。
实验
5.1实验建立
数据。我们使用MovieScenes数据集实现所有基线方法。整个注释集根据视频级别按10:2:3的比例分为Train,Val和Test集。
实施细节。我们将交叉熵损失用于二分类。由于数据集中存在不平衡现象,即非场景转换镜头边界占主导地位(大约9:1),因此我们分别将非场景转换镜头边界和场景转换镜头边界的交叉熵损失设为1:9权重。我们使用Adam优化器对这些模型进行了30个时期的训练。初始学习速率为0.01,在第15个时期将学习速率除以10。
在全局最优分组中,根据获得的这些镜头边界的分类分数(通常一个电影包含1k〜2k镜头边界),我们从局部分割中取j = 600 超级镜头。目标场景的范围从50 到400,即i∈[50,400]。这些值是根据MovieScenes统计信息估算的。
评估指标。我们采用三种常用的度量标准:
1)平均精度(AP)。特别是在我们的实验中,它是每部电影的AP的平均值oi = 1。
2)Miou:检测到的场景边界的并交的加权总和,即其与最近的GroundTruth场景边界的距离。
3)Recall @ 3s:每隔3秒钟调用一次,已注释场景边界的百分比位于预测边界的3s之内。
5.2定量结果
总体结果显示在表3中。我们重现了具有深层位置特征的现有方法[18、4、10、21、24、1],以进行公平比较。基本模型对具有place特征的镜头应用时间卷积,我们逐步向其中添加以下四个模块,即
1)多个语义元素(Multi-Semantics),
2)Clip级别的镜头边界表示(BNet),
3)使用局部序列模型(Local Seq)在segment级别进行粗略预测,以及
4)在movie级别(Global)进行全局最优分组。
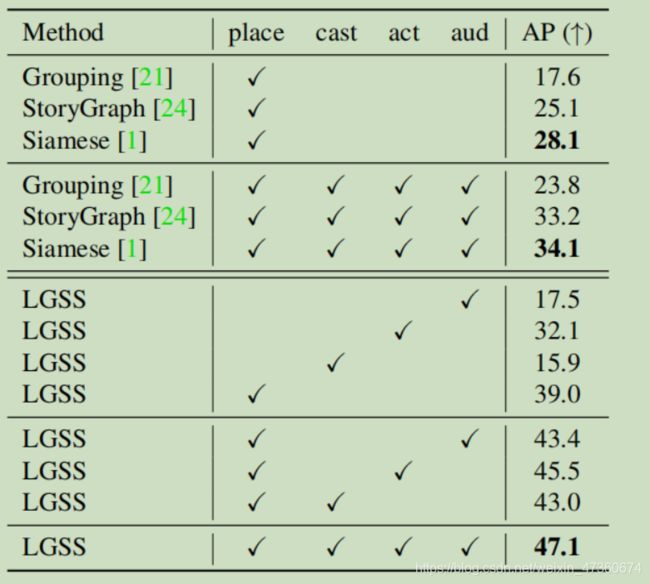
表3.场景分割结果。在我们的管道中,“多语义”表示多个语义元素,“ BNet”表示镜头边界建模边界网,“ Local Seq”表示局部序列模型,“ Global”表示全局最优分组。
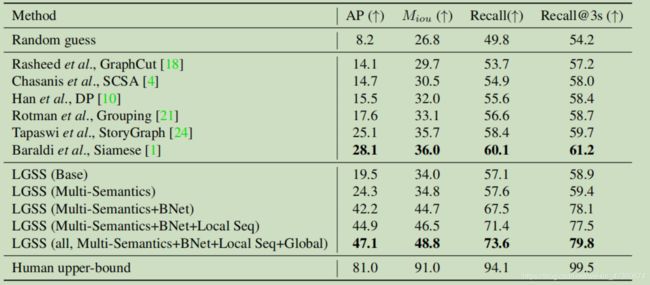
总体结果分析。随机方法的性能取决于测试集中场景过渡/非场景过渡镜头边界的比率,该比率约为1:9。所有常规方法[18、4、10、21]的性能均优于随机方法。但是,由于它们仅考虑本地上下文信息而无法捕获语义信息,因此无法获得良好的性能。[24,1]通过考虑大范围信息,比常规方法[18,4,10,21]取得了更好的结果。
分析我们的框架。我们的基本模型将时间卷积应用于具有place特征的镜头,并在AP上达到19.5。借助多种语义元素,我们的方法从19.5(基本)提高到24.3(多语义)(相对而言提高了24.6%)。使用BNet进行镜头边界建模的框架将性能从24.3(多语义)提高到42.2(多语义+ BNet)(相对于73.7%),这表明在场景分割任务中,直接对镜头边界进行建模是有用。局部序列模型(Multi-Semantics + BNet + Local Seq)的方法比模型(Multi Semantics + BNet)从42.2到44.9可获得2.7的绝对改善和6.4%的相对改进。完整的模型包括局部序列模型和全局最佳分组(多语义+ BNet +局部序列+全局),进一步将结果从44.9提高到47.1,这表明电影级优化对于场景分割非常重要。
总而言之,借助多个语义元素,clip级别的镜头建模,segment级别的局部序列模型和movie级别的全局最佳分组,我们的最佳模型大大优于基本模型和以前的最佳模型[1],提高了27.6。在基础模型(Base)上,绝对值提高了142%,在暹罗模型上,绝对值提高了19.0,相对提高了68%[1]。这些验证了此局部到全局框架的有效性。
5.3消融研究
多个语义元素。我们以镜头边界建模BNet,局部序列模型和全局最优分组为基础模型。如表4所示,逐渐添加中层语义元素提高了最终结果。从仅使用place的模型开始,audio改进了4.4,action改进了6.5,cast改进了4.0,并且总体改进了8.1。该结果表明,place,cast表,action和audio在形成中都有助于场景分割。
另外,借助我们的多语义元素,其他方法[21、24、1]可以实现20%到30%的相对改进。 该结果进一步证明我们的假设,即多语义元素有助于场景分割。
表4.多个语义元素场景分割消融结果,其中研究了四个元素,包括place,cast,action和audio。
时间长度的影响。我们在clip级别(BNet)的镜头边界建模中选择了不同的窗口尺寸,在segment级别(Local Seq)中选择了Bi-LSTM的不同序列长度。结果显示在表5中。实验表明,较长的信息范围可以提高性能。有趣的是,最好的结果来自用于镜头边界建模的4个镜头和作为局部序列模型的输入的10个镜头边界,总共涉及14个镜头信息。这大约是一个场景的长度。它表明此时间信息范围有助于场景分割。
表5.在clip和segment级别的不同时间窗口大小的比较。垂直线在clip级别镜头边界建模(BNet)的窗口大小上有所不同,水平线在segment级别序列模型的长度(seq)上有所不同。

全局最优分组中超参数的选择。我们将优化的迭代次数(Iter#)和初始超级镜头数目(Init#)不同,并将结果显示在表6中。
表6.全局最佳分组中不同超参数的比较以及初始超级镜头数的不同选择。
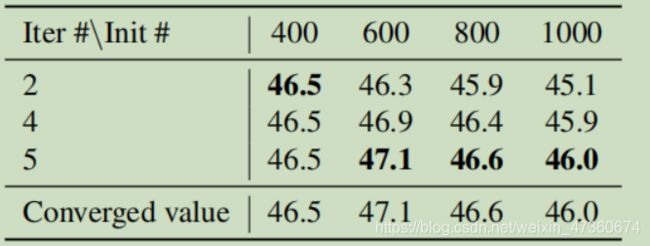
我们首先查看每一行,然后更改初始超级镜头数量。初始编号为600的设置可获得最佳效果,因为它接近目标场景编号50到400,同时确保了足够大的搜索空间。然后,当我们查看每列时,我们发现初始编号为400的设置以最快的方式收敛。经过2次迭代,它可以很快获得最佳结果。并且所有设置都覆盖5次迭代。
5.4定性结果
定性结果显示了我们的多模式方法的有效性,如图4所示,全局最优分组的定性结果如图5所示。

图4.多个语义元素的解释,其中每个语义元素的相似性规范由相应的条长表示。这四个影片剪辑说明了不同元素如何有助于场景的预测。
多个语义元素。为了量化多个语义元素的重要性,我们采用每种模式的余弦相似度范数。 图4(a)显示了一个示例,其中连拍在连续镜头中非常相似,有助于场景的形成。在图4(b)中,角色及其动作难以辨认:第一个镜头是人物很小的长镜头,而最后一个镜头只显示了一部分人物而没有清晰的面孔。在这些情况下,由于这些镜头之间共享了相似的音频功能,因此可以识别场景。图4(c)是一个典型的“电话”场景,其中每个镜头的动作都相似。在图4(d)中,只有一个地方是相似的,我们仍将其总结为一个场景。从以上对更多此类情况的观察和分析中,我们得出以下经验结论:多模式信息相互补充,有助于场景分割。
最佳分组。我们展示了两种情况,以证明最佳分组的有效性。图5中有两个场景。如果没有全局最佳分组,则具有突然视点变化的场景很可能会预测场景转换(图中的红线),例如, 在第一种情况下,当镜头类型从全景拍摄变为近景拍摄时,粗略预测会得到两个场景切换。 在第二种情况下,当出现极端特写镜头时,粗略预测会得到场景切换。我们的全局最佳分组能够按预期消除这些多余的场景切换。

图5.两种情况下全局最优分组的定性结果。在每种情况下,第一行和第二行分别是在全局最优分组之前和之后的结果。两张照片之间的红线表示有场景切换。每种情况的基本事实是这些镜头属于同一场景。
5.5跨数据集传输
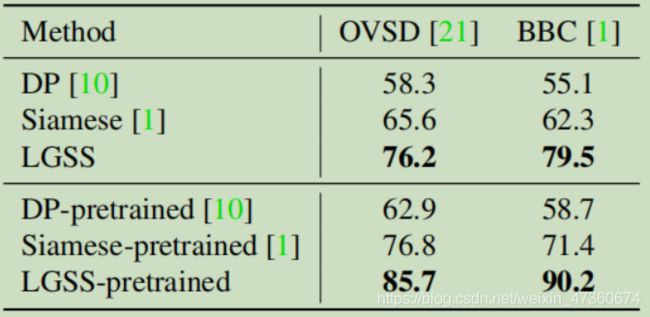
我们通过对MovieScenes数据集进行预训练,在现有数据集OVSD [1]和BBC [21]上测试了DP [10]和Siamese [1]的不同方法,结果如表7所示。通过对我们的数据集进行预训练,性能可以达到显着改善,即AP的绝对改善约10%,相对改善约15%。原因是我们的数据集涵盖了更多的场景,并为其上训练的模型带来了更好的生成能力。
表7.现有数据集上的场景分割跨数据集传输结果(AP)。
6.结论
在这项工作中,我们收集了一个大型注释集,用于对包含270K注释的150部电影进行场景分割。我们提出了一个局部到全局场景分割框架,以覆盖分层的时间和语义信息。实验表明,该框架非常有效,并且比现有方法具有更好的性能。成功的场景分割能够支持许多电影理解应用程序。本文所有研究共同表明,场景分析是一个充满挑战但有意义的话题,值得进一步研究。
致谢这项工作得到了香港普通研究基金(GRF)的部分支持(No.14203518和编号14205719)和SenseTime协作式赠款,用于大规模多模式分析。