CSP Darknet53
CSP Darknet53
代码复现:这里的代码参考CSDN@Bubbliiiing
在之前yolo v3的实战篇中,我们了解到yolo v3 使用的backbone是Darknet53,而今天要展现的是yolo v4的backbone CSP Darknet53。
他们有什么不同呢?
- 激活函数的改变,之前Darknet53使用的是LeakyReLU,而CSP Darknet53使用的是Mish。
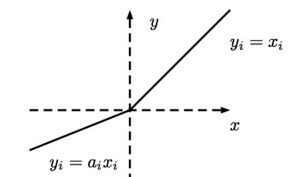
LeakyReLU的图像
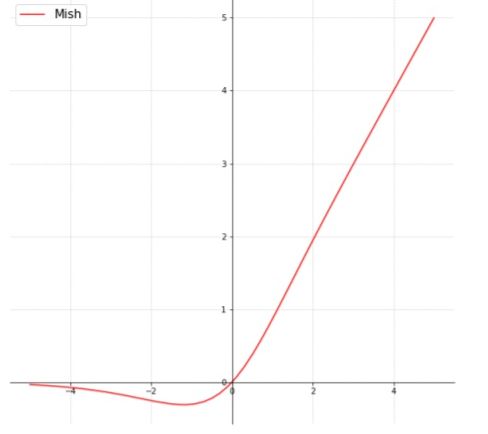
LeakyReLU是分段函数,当x>0时, f(x) = x 当x<=0时, f(x) = axMish的图像是
f(x) = x * tanh(softplus(x)) = x * tanh(ln(1+exp(x)))两者并没有很大的差距,但是下面Mish的计算量相对来说会大一些,效果可能会好些
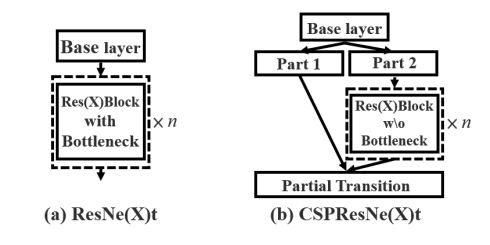
backbone从Darknet53变为CSP Darknet53,主要体现在
从上图上看,CSP在保持原来的Bottleneck的基础上,利用卷积的方式将输入的特征数据分为2个部分(split_conv0, split_conv1),这两部分其中一部分做resnet的残差卷积,然后在做1x1卷积,最后与另一部分进行cat拼接操作。
import math
import torch
from torch import nn
import torch.nn.functional as F
class Mish(nn.Module):
'''
# 实现Mish函数
Mish公式为 f(x) = x * tanh(softplus(x)) = x * tanh(ln(1+exp(x)))
'''
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))
class BasicConv(nn.Module):
'''
实现基本的卷积层结构: conv -> BN -> activation
python: // 表示结果向下取整 / 表示结果向上取整 6 // 4 == 1 6 / 4 == 1.5
'''
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=(stride, stride), padding=kernel_size // 2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = Mish()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activation(x)
return x
class Resblock(nn.Module):
'''
和resnet 一样,做残差结构
'''
def __init__(self, channels, hidden_channels=None):
super(Resblock, self).__init__()
if hidden_channels is None:
hidden_channels = channels
self.block = nn.Sequential(
BasicConv(channels, hidden_channels, 1),
BasicConv(hidden_channels, channels, 3)
)
def forward(self, x):
return x + self.block(x)
class Resblock_body(nn.Module):
'''
这里与darknet53最大的不同是:
每一次Resblock_body 都会采用csp结构,将输入利用卷积的方式分为2个部分(split_conv0, split_conv1),这两部分其中一部分会和原始darknet一样,做resnet的残差卷积,然后在做1x1卷积,最后与另一部分进行cat拼接操作,很像残差结构,但并不是,残差是各个位置相加,而这里是cat,拼接操作
'''
def __init__(self, in_channels, out_channels, num_blocks, first):
super(Resblock_body, self).__init__()
self.downsample_conv = BasicConv(in_channels=in_channels, out_channels=out_channels,
kernel_size=3, stride=2)
if first:
self.split_conv0 = BasicConv(in_channels=out_channels, out_channels=out_channels,
kernel_size=1)
self.split_conv1 = BasicConv(in_channels=out_channels, out_channels=out_channels,
kernel_size=1)
self.blocks_conv = nn.Sequential(
Resblock(channels=out_channels, hidden_channels=out_channels // 2),
BasicConv(in_channels=out_channels, out_channels=out_channels, kernel_size=1)
)
self.concat_conv = BasicConv(in_channels=out_channels * 2, out_channels=out_channels,
kernel_size=1)
else:
self.split_conv0 = BasicConv(in_channels=out_channels,
out_channels=out_channels // 2,
kernel_size=1)
self.split_conv1 = BasicConv(in_channels=out_channels,
out_channels=out_channels // 2,
kernel_size=1)
self.blocks_conv = nn.Sequential(
*[Resblock(channels=out_channels // 2) for _ in range(num_blocks)],
BasicConv(in_channels=out_channels // 2, out_channels=out_channels // 2,
kernel_size=1)
)
self.concat_conv = BasicConv(in_channels=out_channels, out_channels=out_channels,
kernel_size=1)
def forward(self, x):
x = self.downsample_conv(x)
x0 = self.split_conv0(x)
x1 = self.split_conv1(x)
x1 = self.blocks_conv(x1)
x = torch.cat([x1, x0], dim=1)
x = self.concat_conv(x)
return x
class CSPDarknet(nn.Module):
def __init__(self, layers):
super(CSPDarknet, self).__init__()
self.inplanes = 32
self.conv1 = BasicConv(in_channels=3, out_channels=self.inplanes, kernel_size=3,
stride=1)
self.feature_channels = [64, 128, 256, 512, 1024]
self.stages = nn.ModuleList([
Resblock_body(self.inplanes, self.feature_channels[0], layers[0], first=True),
Resblock_body(self.feature_channels[0], self.feature_channels[1], layers[1], first=False),
Resblock_body(self.feature_channels[1], self.feature_channels[2], layers[2], first=False),
Resblock_body(self.feature_channels[2], self.feature_channels[3], layers[3], first=False),
Resblock_body(self.feature_channels[3], self.feature_channels[4], layers[4], first=False)
])
self.num_features = 1
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.conv1(x)
x = self.stages[0](x)
x = self.stages[1](x)
out3 = self.stages[2](x)
out4 = self.stages[3](out3)
out5 = self.stages[4](out4)
return out3, out4, out5
def darknet53(pretrained, activation=None):
model = CSPDarknet([1, 2, 8, 8, 4])
if pretrained:
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request a pretrained path. got [{}]".format(pretrained))
return model
if __name__ == '__main__':
model = darknet53(pretrained=False)
from torchsummary import summary
print(summary(model, (3, 416, 416)))
.format(pretrained))
return model
if __name__ == '__main__':
model = darknet53(pretrained=False)
from torchsummary import summary
print(summary(model, (3, 416, 416)))