利用感知机实现鸢尾花分类问题
1. 实验简介
什么是感知机?
感知机是一种二分类的线性判别模型。主要采用了分离超平面的概念,其学习策略是极小化误分点到超平面距离,使用的学习算法为随机梯度下降算法。
我们将采用sklearn包中提供的iris数据使用两种方法进行训练及分类。第一种是根据随机梯度下降法编写算法来训练数据,直到找到分离的超平面。第二种将采用sklearn包中的Perceptron(感知机)类实现。使用最经典的鸢尾花数据集: 鸢尾花数据集地址,鸢尾花的特征主要包括萼片长度、萼片宽度、花瓣长度和花瓣宽度,本次实验利用花瓣的长度和宽度来区分山鸢尾和变色鸢尾。
2. 实验原理
感知机的输入是实例的特征向量,输出是实例的类别,分别取值为1和-1。假设感知机的输入空间是X,输出空间是Y,则,由输入空间到输出空间的函数f(x)=sign(wx+b)称为感知机。其中w是权值向量,b是偏置,线性方程wx+b=0对应于特征空间中的一个超平面S,其中w是超平面的法向量,b是超平面的截距,这个超平面将特征空间划分为了两个部分,这两个部分的点分别是两类。
为了找到这个超平面,定义一个损失函数,并将损失函数最小化,将损失函数定义为误分类点到超平面的距离,误分类点xi到超平面S的距离是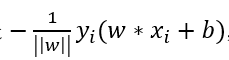 ,这样,所有误分类点到超平面的总距离是
,这样,所有误分类点到超平面的总距离是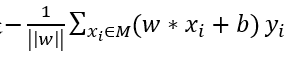 将其定为感知机的损失函数。感知机的学习过程就是将损失函数最优化,可以采用随机梯度下降法,一次随机选取一个误分类点使其梯度下降,对w,b进行更新:
将其定为感知机的损失函数。感知机的学习过程就是将损失函数最优化,可以采用随机梯度下降法,一次随机选取一个误分类点使其梯度下降,对w,b进行更新: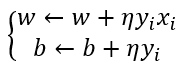 ,(η ,0<η≤1,是学习率)。通过迭代使损失函数不断减少,直到训练集中没有误分类点。
,(η ,0<η≤1,是学习率)。通过迭代使损失函数不断减少,直到训练集中没有误分类点。
算法过程为:
输入:训练数据集以及η
输出:w,b;感知机模型f(x)=sign(w⋅x+b)
-
选取初值w0,b0
-
在训练集中选取数据(x_i y_i)
-
如果y_i (w*x_i+b)≤0,
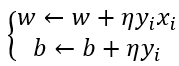
-
转至2,直至训练集中没有误分类点。
3. 实验代码
3.1 方法一
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
# 取出花瓣长度、花瓣宽度以及分类
data = np.array(df.iloc[:100, [2, 3, -1]])
# X是长度和宽度,y是分类
X, y = data[:, :-1], data[:, -1]
y = np.array([1 if i == 1 else -1 for i in y])
class Model:
def __init__(self):
self.w = np.ones(len(data[0]) - 1, dtype=np.float32) # 初始化权重
self.b = 0 # 初始化截距
self.l_rate = 0.1 # 学习步长
# 符号函数
def sign(self, x, w, b):
y = np.dot(x, w) + b
return y
# 进行感知训练
def fit(self, X_train, y_train):
is_wrong = False
while not is_wrong:
wrong_count = 0
for d in range(len(X_train)):
X = X_train[d]
y = y_train[d]
if y * self.sign(X, self.w, self.b) <= 0:
self.w = self.w + self.l_rate * np.dot(y, X) # 更新权重
self.b = self.b + self.l_rate * y # 更新步长
wrong_count += 1
if wrong_count == 0:
is_wrong = True
return 'Perceptron Model!'
perceptron = Model()
perceptron.fit(X, y)
print(perceptron.w)
print(perceptron.b)
x_points = np.linspace(1, 4, 10)
y_ = -(perceptron.w[0] * x_points + perceptron.b) / perceptron.w[1]
plt.plot(x_points, y_)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend()
plt.show()
实验截图
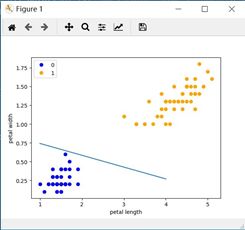
3.2 方法二
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
# 取出花瓣长度、花瓣宽度以及分类
data = np.array(df.iloc[:100, [2, 3, -1]])
# X是长度和宽度,y是分类
X, y = data[:, :-1], data[:, -1]
y = np.array([1 if i == 1 else -1 for i in y])
clf = Perceptron(max_iter=1000)
clf.fit(X, y)
x_points = np.linspace(1, 4, 10)
y_ = -(clf.coef_[0][0] * x_points + clf.intercept_) / clf.coef_[0][1]
plt.plot(x_points, y_)
print(clf.coef_)
print(clf.intercept_)
print(Perceptron.get_params(clf))
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend()
plt.show()
实验截图
