【Datawhale可解释性机器学习笔记】ZFNET
ZFNET介绍
论文地址:Visualizing and Understanding Convolutional Networks
AlexNet的提出使得大型卷积网络开始变得流行起来,但是人们对于CNN网络究竟为什么能表现这么好,以及怎么样能变得更好尚不清楚,因此为了解决上述两个问题,ZFNet提出了一种可视化技术,用于理解网络中间的特征层和最后的分类器层,并且找到改进神经网络的结构的方法。ZFNet是Matthew D.Zeiler 和 Rob Fergus 在2013年撰写的论文Visualizing and Understanding Convolutional Networks中提出的,是当年ILSVRC的冠军。ZFNet使用反卷积(deconv)和可视化特征图来达到可视化AlexNet的目的,并指出不足,最后修改网络结构,提升分类结果。
特征可视化过程如下流程图:

可视化时每一层的操作如下:
Unpooling:在前向传播时,记录相应max pooling层每个最大值来自的位置,在unpooling时,根据来自上层的map直接填在相应位置上,如上图所示,Max Locations “Switches”是一个与pooling层输入等大小的二值map,标记了每个局部极值的位置。
Rectification:因为使用的ReLU激活函数,前向传播时只将正值原封不动输出,负值置0,“反激活”过程与激活过程没什么分别,直接将来自上层的map通过ReLU。
Deconvolution:可能称为transposed convolution更合适,卷积操作output map的尺寸一般小于等于input map的尺寸,transposed convolution可以将尺寸恢复到与输入相同,相当于上采样过程,该操作的做法是,与convolution共享同样的卷积核,但需要将其左右上下翻转(即中心对称),然后作用在来自上层的feature map进行卷积,结果继续向下传递。
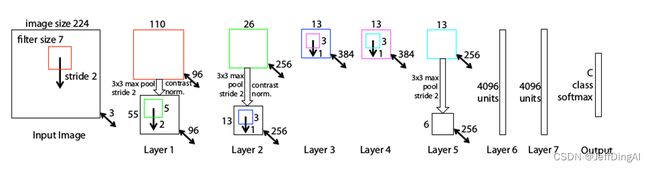
ZFNET结构
ZFNET代码示例(TensorFlow 1x 实现)
代码参考:https://github.com/amir-saniyan/ZFNet/
zfnet.py
import tensorflow as tf
class ZFNet:
def __init__(self, input_width=224, input_height=224, input_channels=3, num_classes=1000, learning_rate=0.01,
momentum=0.9, keep_prob=0.5):
# From article: Stochastic gradient descent with a mini-batch size of 128 was used to update the parameters,
# starting with a learning rate of 10**−2, in conjunction with a momentum term of 0.9.
# From article: Dropout is used in the fully connected layers (6 and 7) with a rate of 0.5.
self.input_width = input_width
self.input_height = input_height
self.input_channels = input_channels
self.num_classes = num_classes
self.learning_rate = learning_rate
self.momentum = momentum
self.keep_prob = keep_prob
self.random_mean = 0
self.random_stddev = 0.01
# ----------------------------------------------------------------------------------------------------
# Input: 224x224x3.
with tf.name_scope('input'):
self.X = tf.placeholder(dtype=tf.float32,
shape=[None, self.input_height, self.input_width, self.input_channels], name='X')
# Labels: 1000.
with tf.name_scope('labels'):
self.Y = tf.placeholder(dtype=tf.float32, shape=[None, self.num_classes], name='Y')
# Dropout keep prob.
with tf.name_scope('dropout'):
self.dropout_keep_prob = tf.placeholder(dtype=tf.float32, shape=(), name='dropout_keep_prob')
# Layer 1.
# [Input] ==> 224x224x3
# --> 224x224x3 ==> [Convolution: size=(7x7x3)x96, strides=2, padding=valid] ==> 110x110x96
# --> 110x110x96 ==> [ReLU] ==> 110x110x96
# --> 110x110x96 ==> [Max-Pool: size=3x3, strides=2, padding=valid] ==> 55x55x96
# --> [Output] ==> 55x55x96
# Note: There were some calculation errors in ZFNet architecture:
# floor((224-7)/2) + 1 = 109
# floor((110-3)/2) + 1 = 54
with tf.name_scope('layer1'):
layer1_activations = self.__conv(input=self.X, filter_width=7, filter_height=7, filters_count=96,
stride_x=2, stride_y=2, padding='VALID')
layer1_pool = self.__max_pool(input=layer1_activations, filter_width=3, filter_height=3, stride_x=2,
stride_y=2, padding='VALID')
# Layer 2.
# [Input] ==> 55x55x96
# --> 55x55x96 ==> [Convolution: size=(5x5x96)x256, strides=2, padding=valid] ==> 26x26x256
# --> 26x26x256 ==> [ReLU] ==> 26x26x256
# --> 26x26x256 ==> [Max-Pool: size=3x3, strides=2, padding=valid] ==> 13x13x256
# --> [Output] ==> 13x13x256
# Note: There were some calculation errors in ZFNet architecture:
# floor((26-3)/2) + 1 = 12
with tf.name_scope('layer2'):
layer2_activations = self.__conv(input=layer1_pool, filter_width=5, filter_height=5, filters_count=256,
stride_x=2, stride_y=2, padding='VALID')
layer2_pool = self.__max_pool(input=layer2_activations, filter_width=3, filter_height=3, stride_x=2,
stride_y=2, padding='VALID')
# Layer 3.
# [Input] ==> 13x13x256
# --> 13x13x256 ==> [Convolution: size=(3x3x256)x384, strides=1, padding=same] ==> 13x13x384
# --> 13x13x384 ==> [ReLU] ==> 13x13x384
# --> [Output] ==> 13x13x384
with tf.name_scope('layer3'):
layer3_activations = self.__conv(input=layer2_pool, filter_width=3, filter_height=3, filters_count=384,
stride_x=1, stride_y=1, padding='SAME')
# Layer 4.
# [Input] ==> 13x13x384
# --> 13x13x384 ==> [Convolution: size=(3x3x384)x384, strides=1, padding=same] ==> 13x13x384
# --> 13x13x384 ==> [ReLU] ==> 13x13x384
# --> [Output] ==> 13x13x384
with tf.name_scope('layer4'):
layer4_activations = self.__conv(input=layer3_activations, filter_width=3, filter_height=3,
filters_count=384, stride_x=1, stride_y=1, padding='SAME')
# Layer 5.
# [Input] ==> 13x13x384
# --> 13x13x384 ==> [Convolution: size=(3x3x384)x256, strides=1, padding=same] ==> 13x13x256
# --> 13x13x256 ==> [ReLU] ==> 13x13x256
# --> 13x13x256 ==> [Max-Pool: size=3x3, strides=2, padding=valid] ==> 6x6x256
# --> [Output] ==> 6x6x256
with tf.name_scope('layer5'):
layer5_activations = self.__conv(input=layer4_activations, filter_width=3, filter_height=3,
filters_count=256, stride_x=1, stride_y=1, padding='SAME')
layer5_pool = self.__max_pool(input=layer5_activations, filter_width=3, filter_height=3, stride_x=2,
stride_y=2, padding='VALID')
# Layer 6.
# [Input] ==> 6x6x256=9216
# --> 9216 ==> [Fully Connected: neurons=4096] ==> 4096
# --> 4096 ==> [ReLU] ==> 4096
# --> 4096 ==> [Dropout] ==> 4096
# --> [Output] ==> 4096
with tf.name_scope('layer6'):
pool5_shape = layer5_pool.get_shape().as_list()
flattened_input_size = pool5_shape[1] * pool5_shape[2] * pool5_shape[3]
layer6_fc = self.__fully_connected(input=tf.reshape(layer5_pool, shape=[-1, flattened_input_size]),
inputs_count=flattened_input_size, outputs_count=4096, relu=True)
layer6_dropout = self.__dropout(input=layer6_fc)
# Layer 7.
# [Input] ==> 4096
# --> 4096 ==> [Fully Connected: neurons=4096] ==> 4096
# --> 4096 ==> [ReLU] ==> 4096
# --> 4096 ==> [Dropout] ==> 4096
# --> [Output] ==> 4096
with tf.name_scope('layer7'):
layer7_fc = self.__fully_connected(input=layer6_dropout, inputs_count=4096, outputs_count=4096, relu=True)
layer7_dropout = self.__dropout(input=layer7_fc)
# Layer 8.
# [Input] ==> 4096
# --> 4096 ==> [Logits: neurons=1000] ==> 1000
# --> [Output] ==> 1000
with tf.name_scope('layer8'):
layer8_logits = self.__fully_connected(input=layer7_dropout, inputs_count=4096,
outputs_count=self.num_classes, relu=False, name='logits')
# Cross Entropy.
with tf.name_scope('cross_entropy'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=layer8_logits, labels=self.Y,
name='cross_entropy')
self.__variable_summaries(cross_entropy)
# Training.
with tf.name_scope('training'):
loss_operation = tf.reduce_mean(cross_entropy, name='loss_operation')
tf.summary.scalar(name='loss', tensor=loss_operation)
optimizer = tf.train.MomentumOptimizer(learning_rate=self.learning_rate, momentum=self.momentum)
# self.training_operation = optimizer.minimize(loss_operation, name='training_operation')
grads_and_vars = optimizer.compute_gradients(loss_operation)
self.training_operation = optimizer.apply_gradients(grads_and_vars, name='training_operation')
for grad, var in grads_and_vars:
if grad is not None:
with tf.name_scope(var.op.name + '/gradients'):
self.__variable_summaries(grad)
# Accuracy.
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(layer8_logits, 1), tf.argmax(self.Y, 1), name='correct_prediction')
self.accuracy_operation = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name='accuracy_operation')
tf.summary.scalar(name='accuracy', tensor=self.accuracy_operation)
def train_epoch(self, sess, X_data, Y_data, batch_size=128, file_writer=None, summary_operation=None,
epoch_number=None):
num_examples = len(X_data)
step = 0
for offset in range(0, num_examples, batch_size):
end = offset + batch_size
batch_x, batch_y = X_data[offset:end], Y_data[offset:end]
if file_writer is not None and summary_operation is not None:
_, summary = sess.run([self.training_operation, summary_operation],
feed_dict={self.X: batch_x, self.Y: batch_y,
self.dropout_keep_prob: self.keep_prob})
file_writer.add_summary(summary, epoch_number * (num_examples // batch_size + 1) + step)
step += 1
else:
sess.run(self.training_operation, feed_dict={self.X: batch_x, self.Y: batch_y,
self.dropout_keep_prob: self.keep_prob})
def evaluate(self, sess, X_data, Y_data, batch_size=128):
num_examples = len(X_data)
total_accuracy = 0
for offset in range(0, num_examples, batch_size):
end = offset + batch_size
batch_x, batch_y = X_data[offset:end], Y_data[offset:end]
batch_accuracy = sess.run(self.accuracy_operation, feed_dict={self.X: batch_x, self.Y: batch_y,
self.dropout_keep_prob: 1.0})
total_accuracy += (batch_accuracy * len(batch_x))
return total_accuracy / num_examples
def save(self, sess, file_name):
saver = tf.train.Saver()
saver.save(sess, file_name)
def restore(self, sess, checkpoint_dir):
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir))
def __variable_summaries(self, var):
mean = tf.reduce_mean(var)
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('mean', mean)
tf.summary.scalar('stddev', stddev)
tf.summary.histogram('histogram', var)
def __initial_weight_values(self, shape):
# return tf.constant(value=0.01, dtype=tf.float32, shape=shape)
return tf.random_normal(shape=shape, mean=self.random_mean, stddev=self.random_stddev, dtype=tf.float32)
def __conv(self, input, filter_width, filter_height, filters_count, stride_x, stride_y, padding='VALID',
name='conv'):
# From article: All weights are initialized to 10**−2 and biases are set to 0.
with tf.name_scope(name):
input_channels = input.get_shape()[-1].value
filters = tf.Variable(
self.__initial_weight_values(shape=[filter_height, filter_width, input_channels, filters_count]),
name='filters')
convs = tf.nn.conv2d(input=input, filter=filters, strides=[1, stride_y, stride_x, 1], padding=padding,
name='convs')
biases = tf.Variable(tf.zeros(shape=[filters_count], dtype=tf.float32), name='biases')
preactivations = tf.nn.bias_add(convs, biases, name='preactivations')
activations = tf.nn.relu(preactivations, name='activations')
with tf.name_scope('filter_summaries'):
self.__variable_summaries(filters)
with tf.name_scope('bias_summaries'):
self.__variable_summaries(biases)
with tf.name_scope('preactivations_histogram'):
tf.summary.histogram('preactivations', preactivations)
with tf.name_scope('activations_histogram'):
tf.summary.histogram('activations', activations)
return activations
def __max_pool(self, input, filter_width, filter_height, stride_x, stride_y, padding='VALID', name='pool'):
with tf.name_scope(name):
pool = tf.nn.max_pool(input, ksize=[1, filter_height, filter_width, 1], strides=[1, stride_y, stride_x, 1],
padding=padding, name='pool')
return pool
def __fully_connected(self, input, inputs_count, outputs_count, relu=True, name='fully_connected'):
with tf.name_scope(name):
wights = tf.Variable(self.__initial_weight_values(shape=[inputs_count, outputs_count]), name='wights')
biases = tf.Variable(tf.zeros(shape=[outputs_count], dtype=tf.float32), name='biases')
preactivations = tf.nn.bias_add(tf.matmul(input, wights), biases, name='preactivations')
if relu:
activations = tf.nn.relu(preactivations, name='activations')
with tf.name_scope('wight_summaries'):
self.__variable_summaries(wights)
with tf.name_scope('bias_summaries'):
self.__variable_summaries(biases)
with tf.name_scope('preactivations_histogram'):
tf.summary.histogram('preactivations', preactivations)
if relu:
with tf.name_scope('activations_histogram'):
tf.summary.histogram('activations', activations)
if relu:
return activations
else:
return preactivations
def __dropout(self, input, name='dropout'):
with tf.name_scope(name):
return tf.nn.dropout(input, keep_prob=self.dropout_keep_prob, name='dropout')
cifar10数据处理代码
dataset_helper.py
import pickle
import numpy as np
import scipy.misc
def __unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def read_cifar_10(image_width, image_height):
batch_1 = __unpickle('./cifar-10/data_batch_1')
batch_2 = __unpickle('./cifar-10/data_batch_2')
batch_3 = __unpickle('./cifar-10/data_batch_3')
batch_4 = __unpickle('./cifar-10/data_batch_4')
batch_5 = __unpickle('./cifar-10/data_batch_5')
test_batch = __unpickle('./cifar-10/test_batch')
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
total_train_samples = len(batch_1[b'labels']) + len(batch_2[b'labels']) + len(batch_3[b'labels'])\
+ len(batch_4[b'labels']) + len(batch_5[b'labels'])
X_train = np.zeros(shape=[total_train_samples, image_width, image_height, 3], dtype=np.uint8)
Y_train = np.zeros(shape=[total_train_samples, len(classes)], dtype=np.float32)
batches = [batch_1, batch_2, batch_3, batch_4, batch_5]
index = 0
for batch in batches:
for i in range(len(batch[b'labels'])):
image = batch[b'data'][i].reshape(3, 32, 32).transpose([1, 2, 0])
label = batch[b'labels'][i]
X = scipy.misc.imresize(image, size=(image_height, image_width), interp='bicubic')
Y = np.zeros(shape=[len(classes)], dtype=np.int)
Y[label] = 1
X_train[index + i] = X
Y_train[index + i] = Y
index += len(batch[b'labels'])
total_test_samples = len(test_batch[b'labels'])
X_test = np.zeros(shape=[total_test_samples, image_width, image_height, 3], dtype=np.uint8)
Y_test = np.zeros(shape=[total_test_samples, len(classes)], dtype=np.float32)
for i in range(len(test_batch[b'labels'])):
image = test_batch[b'data'][i].reshape(3, 32, 32).transpose([1, 2, 0])
label = test_batch[b'labels'][i]
X = scipy.misc.imresize(image, size=(image_height, image_width), interp='bicubic')
Y = np.zeros(shape=[len(classes)], dtype=np.int)
Y[label] = 1
X_test[i] = X
Y_test[i] = Y
return X_train, Y_train, X_test, Y_test
训练代码
import tensorflow as tf
from zfnet import ZFNet
from dataset_helper import read_cifar_10
INPUT_WIDTH = 80
INPUT_HEIGHT = 80
INPUT_CHANNELS = 3
NUM_CLASSES = 10
LEARNING_RATE = 0.001 # Original value: 0.01
MOMENTUM = 0.9
KEEP_PROB = 0.5
EPOCHS = 100
BATCH_SIZE = 128
print('Reading CIFAR-10...')
X_train, Y_train, X_test, Y_test = read_cifar_10(image_width=INPUT_WIDTH, image_height=INPUT_HEIGHT)
zfnet = ZFNet(input_width=INPUT_WIDTH, input_height=INPUT_HEIGHT, input_channels=INPUT_CHANNELS,
num_classes=NUM_CLASSES, learning_rate=LEARNING_RATE, momentum=MOMENTUM, keep_prob=KEEP_PROB)
with tf.Session() as sess:
print('Training dataset...')
print()
file_writer = tf.summary.FileWriter(logdir='./log', graph=sess.graph)
summary_operation = tf.summary.merge_all()
sess.run(tf.global_variables_initializer())
for i in range(EPOCHS):
print('Calculating accuracies...')
train_accuracy = zfnet.evaluate(sess, X_train, Y_train, BATCH_SIZE)
test_accuracy = zfnet.evaluate(sess, X_test, Y_test, BATCH_SIZE)
print('Train Accuracy = {:.3f}'.format(train_accuracy))
print('Test Accuracy = {:.3f}'.format(test_accuracy))
print()
print('Training epoch', i + 1, '...')
zfnet.train_epoch(sess, X_train, Y_train, BATCH_SIZE, file_writer, summary_operation, i)
print()
final_train_accuracy = zfnet.evaluate(sess, X_train, Y_train, BATCH_SIZE)
final_test_accuracy = zfnet.evaluate(sess, X_test, Y_test, BATCH_SIZE)
print('Final Train Accuracy = {:.3f}'.format(final_train_accuracy))
print('Final Test Accuracy = {:.3f}'.format(final_test_accuracy))
print()
zfnet.save(sess, './model/zfnet')
print('Model saved.')
print()
print('Training done successfully.')
参考资料
揭开CNN的神秘面纱——ZFNet
详解深度学习之经典网络架构(三):ZFNet
【精读AI论文】ZFNet深度学习图像分类算法(反卷积可视化可解释性分析)