生成式模型
0 前言
生成模型和判别模型
生成模型:观测样本和标签的联合概率分布P(x,y),可以用于无监督或有监督
判别模型:直接学习预测函数f(x)或者条件概率分布P(y|x)作为预测
生成模型判别模型
早期的训练
根据训练集估计样本分布p(x),之后对p(x)进行采样,可以生成“和训练集类似”的新样本。
对于低维样本,可以使用简单的,只有少量参数的概率模型(例如高斯)拟合p(x),但高维样本就不好处理了。
目前流行的三种模型
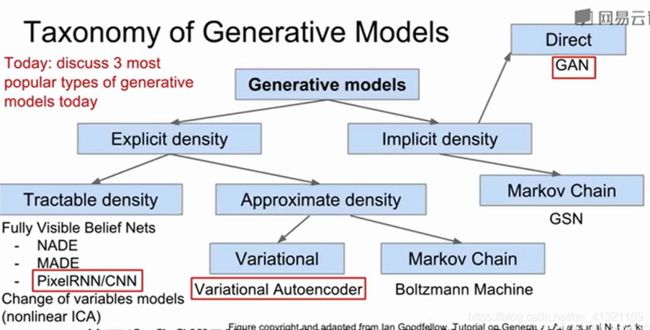
1 PixelRNN&PixelCNN


![在这里插入图片描述]直https://接上传(blog.csdnimg.cn/m-28iaB10114162119307.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxMzIxMTY5,size_16,color_FFFFFF,t_70)https:/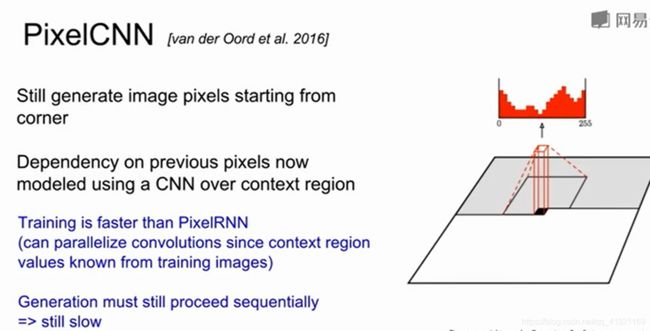
极大似然函数

2 VAE
2.1 自编码器
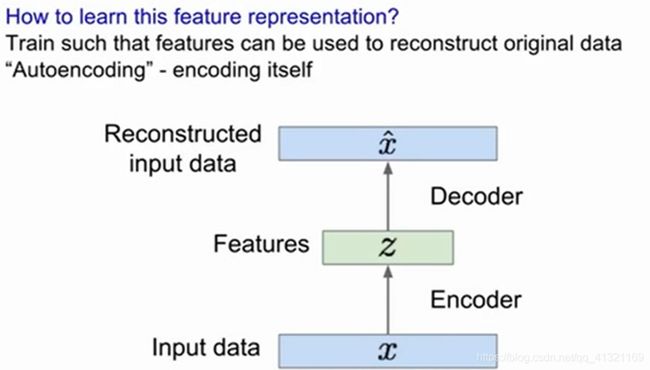
Encoder Decoder

编码器解码器也可以用卷积神经网络
自编码器就是通过输入x进行编码得到低维向量z,再解码出x~。通过对比x与x帽,利用神经网络去训练使得误差逐渐减小,从而达到非监督学习的目的。
用L2 Loss
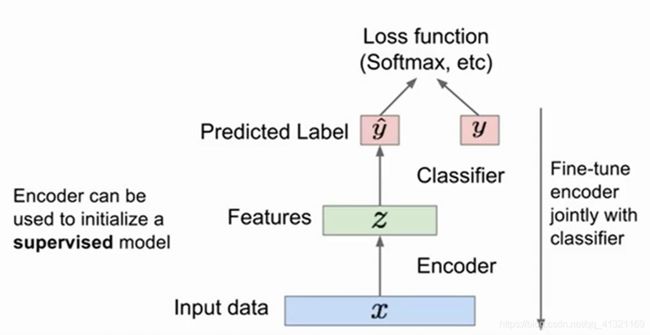
将训练好的编码器来做监督学习的任务 适用于数据少的情况
2.2 变分自编码器
VAE与自编码器的区别是 VAE对z进行了正态分布约束。
2.2.1 网络结构图
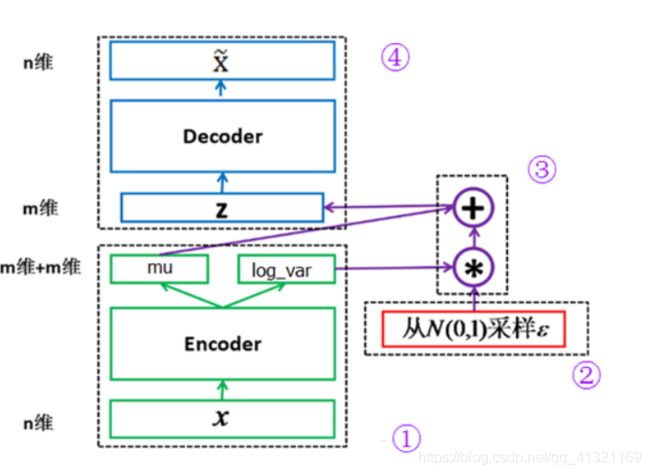
模块①的功能把输入样本X通过编码器输出两个m维向量(mu、log_var),这两个向量是潜在空间(假设满足正态分布)的两个参数(相当于均值和方差)。那么如何从这个潜在空间采用一个点Z?
这里假设潜在正态分布能生成输入图像,从标准正态分布N(0,I)中采样一个ε(模块②的功能),然后使这也是模块③的主要功能。
Z是从潜在空间抽取的一个向量,Z通过解码器生成一个样本X ̃,这是模块④的功能。
这里ε是随机采样的,这就可保证潜在空间的连续性、良好的结构性。而这些特性使得潜在空间的每个方向都表示数据中有意义的变化方向。
以上这些步骤构成整个网络的前向传播过程,反向传播如何进行?要确定反向传播就涉及到损失函数了,损失函数是衡量模型优劣的主要指标。这里我们需要从以下两个方面进行衡量。
(1)生成的新图像与原图像的相似度;
(2)隐含空间的分布与正态分布的相似度。
度量图像的相似度一般采用交叉熵(如nn.BCELoss),度量两个分布的相似度一般采用KL散度(Kullback-Leibler divergence)。这两个度量的和构成了整个模型的损失函数。
![]()
三部分:自编码器、潜在空间、解码器
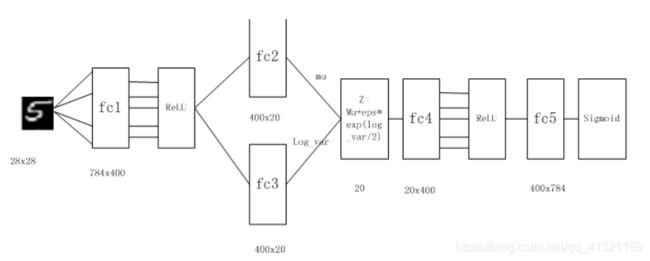
2.2.2 网络结构代码
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc2_mu = nn.Linear(400, 20)
self.fc2_logvar = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc2_mu(h1), self.fc2_logvar(h1)
#潜在空间z,这个假设分布能生成图像
def reparametrization(self, mu, logvar):
# sigma = 0.5*exp(log(sigma^2))= 0.5*exp(log(var))
std = torch.exp(logvar/2)
# N(mu, std^2) = N(0, 1) * std + mu
z = torch.randn(std.size()) * std + mu
return z
def decode(self, z):
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparametrization(mu, logvar)
x_reconst=self.decode(z)
return x_reconst, mu, logvar
VAE利用潜在空间,可以生成连续的新图像,不过因损失函数采用像素间的距离,所以图像有点模糊。
3 GAN
3.1 概念
它是基于博弈论的,所以又称为生成式对抗网络(Generative adversarial nets,GAN)。它是2014年由Ian Goodfellow提出的,它要解决的问题是如何从训练样本中学习出新样本,训练样本是图片就生成新图片,训练样本是文章就输出新文章等。
GAN既不依赖标签来优化,也不是根据对结果奖惩来调整参数。它是依据生成器和判别器之间的博弈来不断优化。打个不一定很恰当的比喻,就像一台验钞机和一台制造假币的机器之间的博弈,两者不断博弈,博弈的结果假币越来越像真币,直到验钞机无法识别一张货币是假币还是真币为止。
这里有两个角色,一个是伪造者,另一个是技术鉴赏者。他们训练的目的都是打败对方。
因此,GAN从网络的角度来看,它由两部分组成。
(1)生成器网络:它一个潜在空间的随机向量作为输入,并将其解码为一张合成图像。
(2)判别器网络:以一张图像(真实的或合成的均可)作为输入,并预测该图像来自训练集还是来自生成器网络。
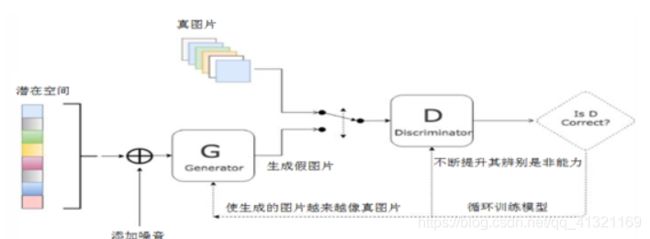
与VAE不同的是,这个潜空间无法保证带连续性或有特殊含义的结构。
GAN的优化过程不像通常的求损失函数的最小值,而是保持生成与判别两股力量的动态平衡。因此,其训练过程要比一般神经网络难很多。
两个子网络交替训练,直到平衡。
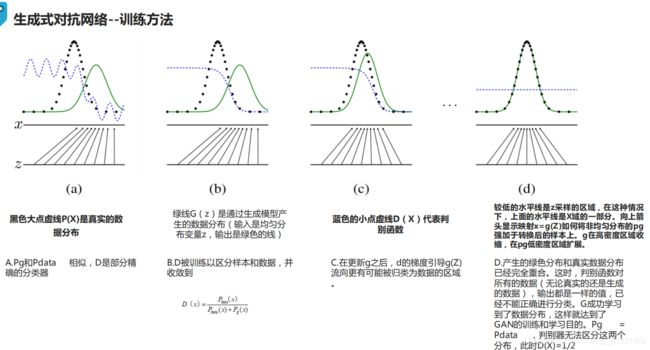
3.2 损失函数
控制生成器或判别器的关键是损失函数,如何定义损失函数成为整个GAN的关键。

最小化两者的组合,使总的代价函数下降。

3.3代码
3.3.1 判别器
# 构建判断器
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid())
3.3.2生成器
生成器与AVE的生成器类似,不同的地方是输出为nn.tanh,使用nn.tanh将使数据分布在[-1,1]之间。其输入是潜在空间的向量z,输出维度与真图片相同。
# 构建生成器,这个相当于AVE中的解码器
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh())
3.3.3训练模型
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
images = images.reshape(batch_size, -1).to(device)
# 定义图像是真或假的标签
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
3.3.3.1 训练判别器
# 定义判别器对真图片的损失函数
outputs = D(images)
d_loss_real = criterion(outputs, real_labels)
real_score = outputs
# 定义判别器对假图片(即由潜在空间点生成的图片)的损失函数
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
d_loss_fake = criterion(outputs, fake_labels)
fake_score = outputs
# 得到判别器总的损失函数
d_loss = d_loss_real + d_loss_fake
# 对生成器、判别器的梯度清零
reset_grad()
d_loss.backward()
d_optimizer.step()
3.3.3.2 训练生成器
# 定义生成器对假图片的损失函数,这里我们要求判别器生成的图片越来越像真图片,故损失函数的标签改为真图片的标签,即希望生成的假图片,越来越靠近真图片
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z)
outputs = D(fake_images)
g_loss = criterion(outputs, real_labels)
# 对生成器、判别器的梯度清零
#进行反向传播及运行生成器的优化器
reset_grad()
g_loss.backward()
g_optimizer.step()
if (i+1) % 200 == 0:
print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'
.format(epoch, num_epochs, i+1, total_step, d_loss.item(), g_loss.item(),
real_score.mean().item(), fake_score.mean().item()))
3.4 缺陷
VAE适合于学习具有良好结构的潜在空间,潜在空间有比较好的连续性,其中存在一些有特定意义的方向。VAE能够捕捉到图像的结构变化(倾斜角度、圈的位置、形状变化、表情变化等)。这也是VAE的一个好处,它有显式的分布,能够容易地可视化图像的分布。
GAN生成的潜在空间可能没有良好结构,但GAN生成的图像一般比VAE的更清晰。


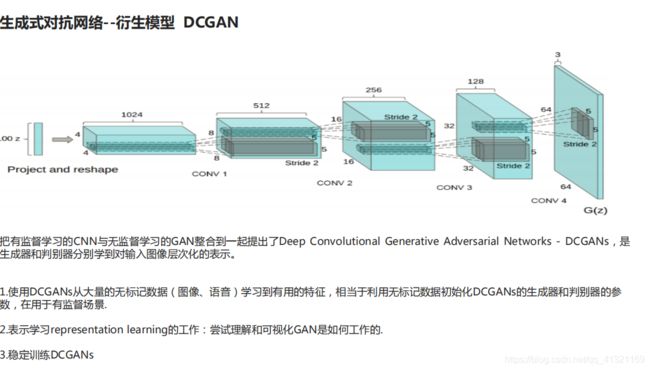
3.5 DCGAN (加入深度卷积网络)
4 生成对抗网络应用
- 图像分辨率
- 图像去雨
- 头像生成