经典网络架构训练图像分类模型
使用经典网络完成花朵的102分类
- 数据预处理
-
- 数据读取
- 数据增强
- 迁移学习
-
- 重定义全连接层
- 执行函数,调整网络可更新参数
- 设置优化器
- 训练模块
- 第一轮训练
- 加训
- 测试数据预处理
- 展示预测结果
数据预处理
今天我们使用的数据集和以前几次有所不同,我们的训练集和测试集都是由文件夹组成的,文件夹的名字是花朵的分类,文件夹存储了该种类花朵的几张图片。
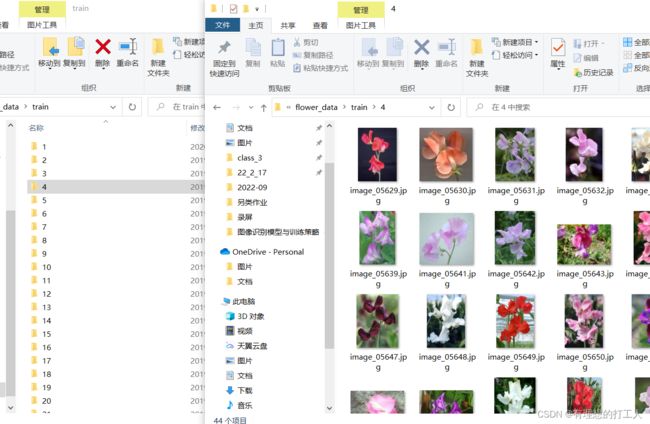
每个编号对应的花朵名称储存在另一个地方,由于每种花朵的图片数量都比较少,所以我们需要做一下数据增强。
数据读取
在开始写代码之前,先做好模块引用:
import os
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
from torchvision import transforms, models, datasets
# https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
warnings.filterwarnings("ignore")
import random
import sys
import copy
import json
from PIL import Image
引用号模块之后,我们把文件的路径读取到位:
data_dir = './flower_data/'
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'
因为我是把py文件和数据文件放在了同一路径下,所以引用起来也比较简单。
数据增强
由于我们的数据量较少,要做一下数据增强。旋转、翻转、平移、剪切都可以从有限的数据得到更多的特征信息:

这些操作可以模拟现实中图片出现的“不完美”,比如裁剪可以模拟现实中图片的遮挡、缺失等现象。因为在数据上多做文章比改网络结构更为简便,达到的效果更好,因此这一步是必须的。
数据增强是torchvision中transforms模块自带功能,数据预处理也是torchvision中transforms帮我们实现好了的,可以直接调用:
data_transforms = { #指定了所有图像预处理操作
'train':
transforms.Compose([# 指定之后操作按顺序进行
transforms.Resize([96, 96]), # 将大小不同的输入源统一成相同规格。分类任务尽量设置成正方形
# 图像大小要兼顾计算机运行速度和所截图像能保存的数据量
transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(64),#从中心开始裁剪
# 裁剪完成后得到的图片是64*64的,通常用到的参数有64,128,256,224
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
# 适配于极端工作场景,如极端光照、极端黑暗
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025), # 依概率转换成灰度图,3通道就是R=G=B
# 以上两条命令不常用到
transforms.ToTensor(), # 转化成tensor类型
# 标准化操作
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 分别对应三通道的均值,标准差。由于我们的数据集太小,
# 因此这些数值使用在真实大数据量的数据集中计算出的结果
]),
'valid': # 验证集只用于检测学习效果,因此不需要再做图像变换,以原图为准就好
transforms.Compose([
transforms.Resize([64, 64]), # 这里要与训练集中做出的最终大小保持一致
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 这里用到的均值和标准差和训练集中保持一致
# 不可以使用用测试集中数据计算出的均值和标准差
]),
}
print(data_transforms['train']) # 查看一下我们做好的数据
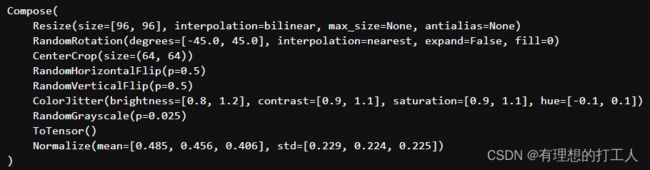
这样,data_transforms中就已经指定了所有图像预处理操作。接下来我们需要把所有图像数据以及标签(文件名)读取进来:
batch_size = 128 # batch选取要根据计算机算力资源判断
# 训练集和测试集用到的数据都是以文件夹为单位标出来的,并且文件夹以数字进行命名,意味着已经对数据做好了分组。
# 因此可以直接用数字作为分类的标签
# ImageFolder可以通过文件夹的形式读取图像的数据和标签
# 假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']} # 通过文件夹找到数据集
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']} # 计算训练集和验证集的总数分别有多少,大家可以自行打印查看
class_names = image_datasets['train'].classes # class_names是按照每一位的数字大小排序的
print(class_names)

同样,我们也可以打印查看一下image_datasets的存储内容:
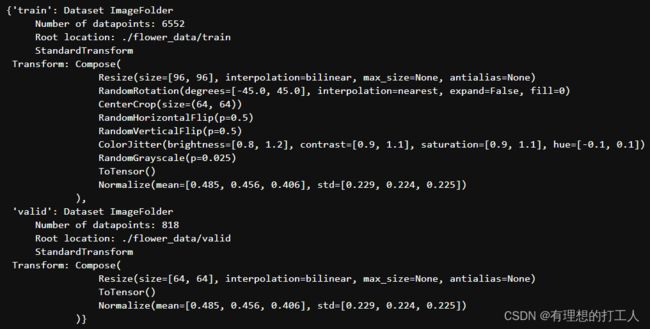
到这里,我们所需要处理的花的数据已经处理的差不多了,接下来改到我们本节的重点了:
迁移学习
使用随机初始化的矩阵开始从零开始学习效率会非常低,而如果使用别人训练好的模型当我们的初始化,只更新部分参数就会变得很高效。
我们迁移别人学习好的模型不一定是针对特定的花朵分类的结果,任何成熟的图像分类模型都可以用于迁移,这是由于图像特征决定的。图像特征提取主要是要提取色彩、周围环境等特征,这些特征的提取方法不会因为应用场景的不同而改变。
套用的别人训练好点的模型就叫做预训练模型,如果我们拥有的数据量少,可以只训练输出层,将中间层冻住,防止学习效果退化;数据量适中,可以减少冻住的中间层数量;数据量很大时,可以只用预训练模型当初始化参数,随着训练的进行对每一层网络的参数都做微调。
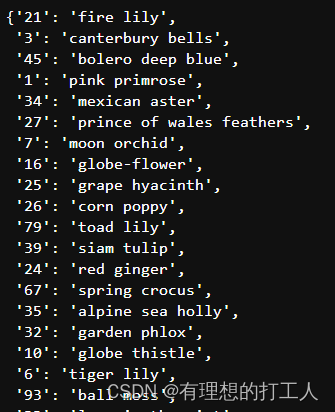
当然,在此之前,我们可以先把分类的数字对应花朵名加载进来:
with open('cat_to_name.json', 'r') as f: # json文件存放的是字典内容,编号为键,名字为值
cat_to_name = json.load(f)
大家可以打印查看一下:
这样一来,准备工作基本都做好了,我们现在开始定义网络的结构:
model_name = 'resnet' # 使用现成的模型,模型里有定义好的网络层数和结构。
# 可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
model_ft = models.resnet18() # 18层resnets,能快点,计算机条件好点的也可以选152(models.resnet152())
# 这个数值不是任意指定的,通常会用到的有18、50、101、152
# 这里只是有了别人训练好的网络结构,买没有训练好的权重参数
#是否用人家训练好的特征来做
feature_extract = True # 特征提取选择True。都用人家特征,咱先不更新
# 判断是否可以用GPU训练
train_on_gpu = torch.cuda.is_available() # cuda装好的就用GPU进行训练,否则使用CPU训练
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
我们可以查看一下model_ft的内容:
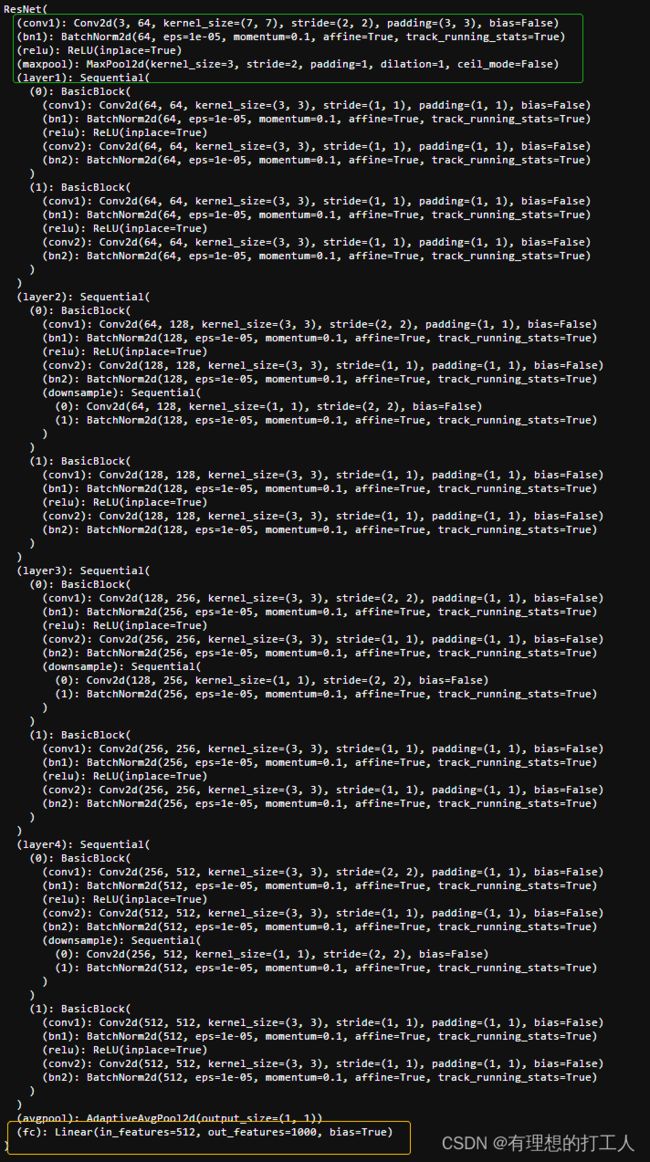
黄色的是全连接层,绿色的是第一层。至于中间的隐层,大家应该能很快地看懂这16层结构吧,这就是18层resnet网络的结构。
下面我们解析一下网络的部分参数:
- 第一层inputchannel为3,outputchannel为64,卷积核选择7*7,为了让第一层卷积得到的图像结果相对较小
- 卷积的步长选择长宽都为2,填充3圈0
- 每次卷积(conv)之后,都需要进行一次归一化
- 在最后一层,迁移来的模型做的是out_features=1000(这个模型全连接层做1000分类),但我们需要做的是102分类,因此我们需要修改最后一层的参数
- avgpool代表了最后做了一个全局的平均池化,例如最终得到的卷积结果是512张14*14特征图,output_size=(1, 1)意味着我们要把
- 每张1414的特征图所有特征求平均,最终要处理成512个11的数字
下面我们要对部分网络结构进行冻结,由于我们的数据较少,所以学习起来先只对全连接层进行学习。阻止网络进行更新的方法也很简单,我们只需要把每一层的requires_grad参数制成False,即可阻止反向传播,自然也就不会更新参数了:
def set_parameter_requires_grad(model, feature_extracting): # 冻结
if feature_extracting:
for param in model.parameters(): # 遍历网络的每一层参数
param.requires_grad = False # 每一层参数requires_grad设置成False,保证反向播时不计算梯度,意味着参数不能进行更新
重定义全连接层
接下来我们要设置模型为可以更新全连接层的参数。如果把迁移学习比喻成抄作业,那么更新全连接层参数就像把名字和学号改成自己的:
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# model_name
model_ft = models.resnet18(pretrained=use_pretrained) # pretrained=True意为把别人训练好的模型参数当做我们的初始化
set_parameter_requires_grad(model_ft, feature_extract) # 停止更新网络的所有参数
# 重新定义全连接层(相当于解冻全连接层)
num_ftrs = model_ft.fc.in_features # 找到原网络全连接层的神经元个数
# 更改分类结果
model_ft.fc = nn.Linear(num_ftrs, num_classes) # 根据任务需求更改分类数量,但是不要更改神经元数
input_size = 64 # 输入大小根据自己配置来
return model_ft, input_size
执行函数,调整网络可更新参数
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)
# GPU还是CPU计算
model_ft = model_ft.to(device)
# 最好的训练模型进行保存,这里先自己起好名字
# 将来会保存网络结构图、权重参数
# 保存好后就可以直接调用,不需要再做重复的训练了
filename='best.pt'
# 是否训练所有层
params_to_update = model_ft.parameters() # params_to_update会把模型当中的所有参数都进行保存
print("Params to learn:") # 查看是否将全连接层解冻
if feature_extract: # 如果冻结了部分参数更新
params_to_update = [] # 清空保存的参数
for name,param in model_ft.named_parameters():
if param.requires_grad == True: # 如果某一层允许更新,我们记录这一层的参数名称
params_to_update.append(param) # 参数要更新,就需要优化器来参与优化
print("\t",name)
else: # 打印出所有参数中所有没有被冻结的需要更新的内容
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
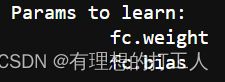
运行到这里,我们就已经成功地冻结了17层网络,只让全连接层进行更新。不放心的小伙伴可以打印一下我们更新过的model_ft,看看网络结构发生了什么变化。
设置优化器
优化器的设置已经贯穿了我们四节课的内容,这一次我们设置的有所不同。因为本次学习内容比较复杂,所以我们要把学习率调整一下。学习率设置过高,后期训练结果提升的幅度就会很小,但如果学习率设置太小,就会导致准确率在一开始就提升的很慢,后面会给大家演示。这里,我们设置初始的学习率为0.01,随着迭代次数的增加而逐渐减小。看代码:
# 优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2) # 把有梯度的参数传进来,作为要训练啥参数
# 衰减策略,学习率随着迭代次数减少
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1) # 用StepLR指定学习率每step_size个epoch衰减成原来的gamma
criterion = nn.CrossEntropyLoss() # 损失函数
训练模块
首先,我们还是按设定将数据打包成多个batch存起来:
for inputs, labels in dataloaders['train']:
inputs = inputs.to(device) # 把数据和标签放到CPU或GPU
print(inputs.shape)
labels = labels.to(device)
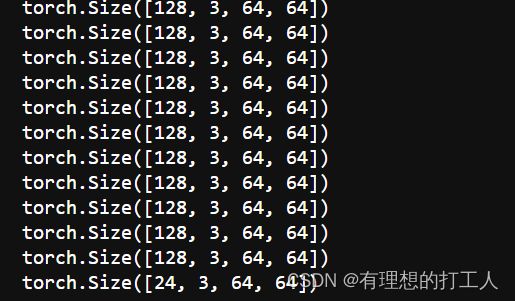
一共有52行,意为训练集数据分为52组,除了最后一组,每组都有128张规格为64×64的图片。
下面我们开始写训练模型和保存、打印学习效果的代码:
# resnet,文件夹+数据形式,损失函数,优化器,默认迭代次数,保存文件的路径&文件名
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25,filename='best.pt'):
# 记录时间
since = time.time()
# 记录最好一次的准确率,防止迭代次数过多之后出现准确率下降的情况
best_acc = 0
# 把模型放到CPU或者GPU
model.to(device)
#训练过程中打印一堆损失和指标
# 保存训练集、验证集的准确率及损失
val_acc_history = []
train_acc_history = []
train_losses = []
valid_losses = []
# 取到字典结构中保存的学习率
LRs = [optimizer.param_groups[0]['lr']]
# 验证集的效果比之前的好才会更新
# 拷贝模型当前的权重参数,后面会不断地用更好的参数覆盖
best_model_wts = copy.deepcopy(model.state_dict())
# 一个个epoch来遍历
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 训练和验证
for phase in ['train', 'valid']:
if phase == 'train':model.train() # 训练
else:model.eval() # 验证
running_loss = 0.0
running_corrects = 0
# 把数据都取个遍
for inputs, labels in dataloaders[phase]:
# 把数据和标签放到CPU或GPU
inputs = inputs.to(device) # 这里不会修改inputs和labels的实质内容
labels = labels.to(device)
# 清零
optimizer.zero_grad()
# 只有训练的时候计算和更新梯度
outputs = model(inputs) # 计算损失
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1) # 拿到预测值(概率最大的分类标签)
# 训练阶段更新权重
if phase == 'train':
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 计算损失
# 一轮完整的训练会进行52次参数的修改
# 这里计算的损失是每一次修改前的损失
# 由于每一次更新参数后损失和预测准确率都会有所变化
# 所以后续还要求均值进行比较
running_loss += loss.item() * inputs.size(0) # 0表示batch那个维度
running_corrects += torch.sum(preds == labels.data)#预测结果最大的和真实值是否一致
# 求平均
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
time_elapsed = time.time() - since #一个epoch我浪费了多少时间
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 查看当前模型训练结果是否为最优,是则保存
# 这部分会不断被覆盖,最终只会留下一个结果
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict()) # 用当前的参数作为最好的参数进行保存
state = {
'state_dict': best_model_wts,#字典里key就是各层的名字,值就是训练好的权重
'best_acc': best_acc,
'optimizer' : optimizer.state_dict(),
}
torch.save(state, filename)
# 将所有信息都进行保存,不会进行覆盖操作
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRs.append(optimizer.param_groups[0]['lr']) # 保存当前学习率
print()
scheduler.step() # 学习率衰减,累加到设定值的时候会自动衰减
time_elapsed = time.time() - since # 计算整体运行所花时间
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 训练完后用最好的一次当做模型最终的结果,等着一会测试
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
现在,我们的只更新全连接层参数的完整训练代码已经准备就绪了,接下来我们就要跑起来了:
第一轮训练
这一轮训练我们只训练全连接层,看看能达到什么样的效果:
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20)
# 一共进行二十轮完整的学习
就是这么简单的代码,执行一下计算机就会学习起来啦~在这里,我把初始学习率改成了0.00001,只是为了给大家演示学习率过低的后果,大家自己执行的时候效果肯定是肯定比我的效果好很多的:
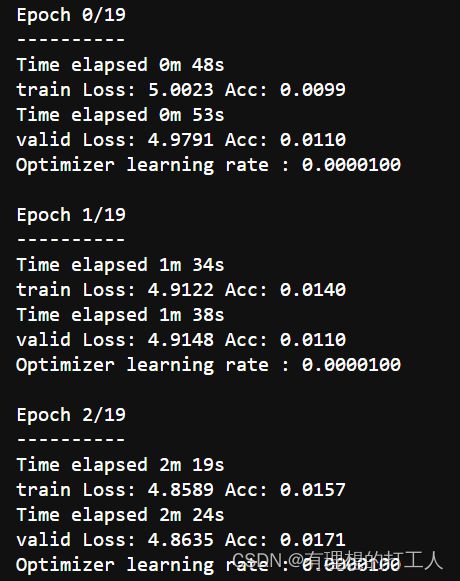
由于太长截不下,这里就不展示中间的内容了
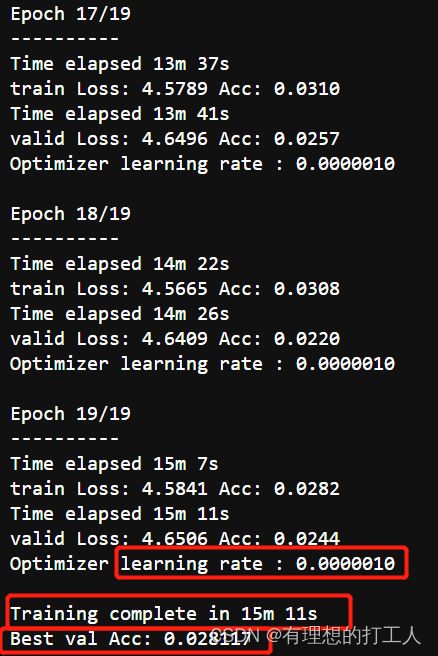
可以看到,这个模型跑下来花费了15分钟,学习率是逐渐衰减的但最好的效果也只是2.8%(我们不关心训练集的准确率,以验证集准确率为考核标准)。大家跑的时候初始学习率设置成0.01,最后应该可以拿到30%以上的准确率。
加训
由于第一轮训练的准确率已经提不上去了,但训练的效果并不算太好,因此我们现在可以考虑让更多层参与训练。这里给大家一个思路,我们可以生成随机数,让计算机决定解冻哪一层。但是我们的加训自然要解冻所有层啦,解冻就是冻结的逆过程,只要把所有的requires_grad(包括全连接层)再次全部设成True即可:
for param in model_ft.parameters(): # 解冻
param.requires_grad = True
# 再继续训练所有的参数,学习率调小一点
optimizer_ft = optim.Adam(model_ft.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=4, gamma=0.1)
# 损失函数
criterion = nn.CrossEntropyLoss()
这里需要注意,我们要引用一下之前训练好的参数,以免计算机从头开始训练:
# 加载之前训练好的权重参数
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc'] # 加载最好的训练结果
print(model_ft.load_state_dict(checkpoint['state_dict'])) # 查看字典所有键是否匹配成功
运行完这段代码之后都会有匹配成功的提示哦~
接下来才是正式的加训:
# 加训十轮吧
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=10)
经过一番激烈的运行,我们得到这样的结果:
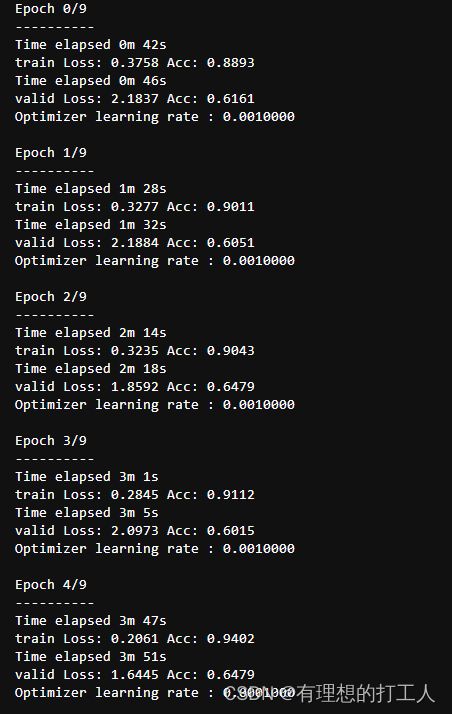
接下来我们就要准备测试了,当然,测试之前同样要保存一下刚训练好的内容:
filename='best.pt'
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
测试数据预处理
测试数据处理方法需要跟训练时一致才可以。crop操作的目的是保证输入的大小是一致的,标准化操作也是必须的,用跟训练数据相同的mean和std,但是需要注意一点训练数据是在0-1上进行标准化,所以测试数据也需要先归一化。最后一点,PyTorch中颜色通道是第一个维度,跟很多工具包都不一样,需要转换:
# 得到一个batch的测试数据
dataiter = iter(dataloaders['valid']) # 制作成迭代器
images, labels = dataiter.next() # 每次取下一组的128个验证集图片数据
model_ft.eval()
if train_on_gpu:
output = model_ft(images.cuda())
else:
output = model_ft(images)
最终output会存储每张验证图片属于102分类中属于每一类的概率。得到概率以后,我们要取出最大的概率对应的编号作为判断结果:
_, preds_tensor = torch.max(output, 1)
# GPU和CPU转换格式的方法有所不同
preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())
展示预测结果
到这里,我们的任务就已经可以结束了,但是这样看起来还是非常抽象,毕竟我只得到了一堆看不太懂的数字。下面我们把得到的数字转换成我们能看得懂的内容:
def im_convert(tensor):
""" 展示数据"""
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze() # 删除数组中条目为单维度条目:https://www.jb51.net/article/208109.htm
image = image.transpose(1,2,0) # 把颜色通道数放在最后
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406)) # 去标准化,尽量更接近原图
image = image.clip(0, 1)
return image
fig=plt.figure(figsize=(20, 20))
columns =4
rows = 2
for idx in range (columns*rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
plt.imshow(im_convert(images[idx]))
ax.set_title("{} ({})".format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),
# 如果是绿色字,证明预测正确,红色字则代表预测错误
color=("green" if cat_to_name[str(preds[idx])]==cat_to_name[str(labels[idx].item())] else "red"))
plt.show()
需要注意,由于空间有限,我们只展示了某一组的128张图片中的前8个图像判断情况:

当然,如果我们想要看同一组验证集图像中后面的图片和分类结果的情况,可以将上面代码中的
plt.imshow(im_convert(images[idx]))
改成
plt.imshow(im_convert(images[idx+10]))

今天的讲述就到这里啦,感兴趣的小伙伴可以继续自己探索哟~