使用MindStudio的HPO界面工具进行调优
BiliBili视频链接:https://www.bilibili.com/video/BV1De411w7tY/?vd_source=4df1b4d14f3f9a52d67c0a0866130ae5
一、MindStudio介绍
1.1 基本介绍
MindStudio为用户提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。通过依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助用户在一个工具上就能高效便捷地完成AI应用开发。另一方面,MindStudio采用插件化扩展机制,以支持开发者通过开发插件来扩展已有功能。在本案例中所使用的MindStudio版本为5.0.RC1,具体安装流程可参考MindStudio安装教程(https://www.hiascend.com/document/detail/zh/mindstudio/50RC3/instg/instg_000002.html)。
具体的,MindStudio的功能包括:
- 针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
- 针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
- 针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
- 针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio可以进行工程管理、编译、调试、性能分析等全流程开发,可以很大程度提高开发效率。
MindStudio功能框架如图1所示,目前含有的工具链包括:模型转换工具、模型训练工具、自定义算子开发工具、应用开发工具、工程管理工具、编译工具、流程编排工具、精度比对工具、日志管理工具、性能分析工具、设备管理工具等多种工具。
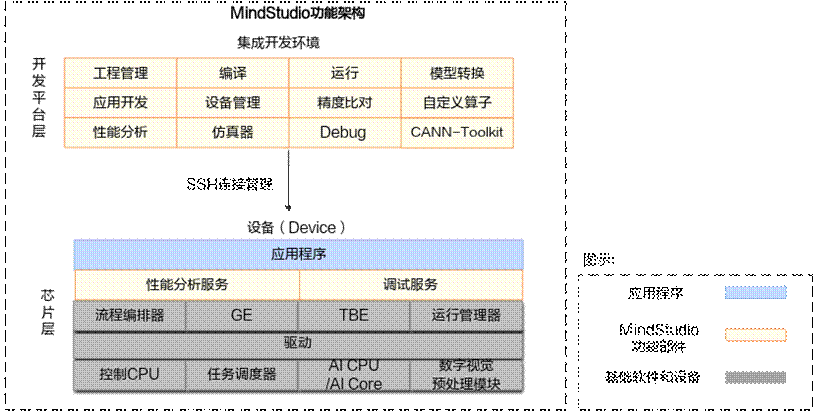
图1
1.2 MindStudio工具中的主要功能特性
- 工程管理:为开发人员提供创建工程、打开工程、关闭工程、删除工程、新增工程文件目录和属性设置等功能。
- SSH管理:为开发人员提供新增SSH连接、删除SSH连接、修改SSH连接、加密SSH密码和修改SSH密码保存方式等功能。
- 应用开发:针对业务流程开发人员,MindStudio工具提供基于AscendCL(Ascend Computing Language)和集成MindX SDK的应用开发编程方式,编程后的编译、运行、结果显示等一站式服务让流程开发更加智能化,可以让开发者快速上手。
- 自定义算子开发:提供了基于TBE和AI CPU的算子编程开发的集成开发环境,让不同平台下的算子移植更加便捷,适配昇腾AI处理器的速度更快。
- 离线模型转换:训练好的第三方网络模型可以直接通过离线模型工具导入并转换成离线模型,并可一键式自动生成模型接口,方便开发者基于模型接口进行编程,同时也提供了离线模型的可视化功能。
- 日志管理:MindStudio为昇腾AI处理器提供了覆盖全系统的日志收集与日志分析解决方案,提升运行时算法问题的定位效率。提供了统一形式的跨平台日志可视化分析能力及运行时诊断能力,提升日志分析系统的易用性。
- 性能分析:MindStudio以图形界面呈现方式,实现针对主机和设备上多节点、多模块异构体系的高效、易用、可灵活扩展的系统化性能分析,以及针对昇腾AI处理器的性能和功耗的同步分析,满足算法优化对系统性能分析的需求。
- 设备管理:MindStudio提供设备管理工具,实现对连接到主机上的设备的管理功能。
- 精度比对:可以用来比对自有模型算子的运算结果与Caffe、TensorFlow、ONNX标准算子的运算结果,以便用来确认神经网络运算误差发生的原因。
- 开发工具包的安装与管理:为开发者提供基于昇腾AI处理器的相关算法开发套件包Ascend-cann-toolkit,旨在帮助开发者进行快速、高效的人工智能算法开发。开发者可以将开发套件包安装到MindStudio上,使用MindStudio进行快速开发。Ascend-cann-toolkit包含了基于昇腾AI处理器开发依赖的头文件和库文件、编译工具链、调优工具等。
1.3 安装指南
使用MindStudio前,首先应确定其使用场景,包括纯开发场景和开发运行场景两种:
- 纯开发场景(分部署形态):在非昇腾AI设备上安装MindStudio和Ascend-cann-toolkit开发套件包。可作为开发环境仅能用于代码开发、编译等不依赖于昇腾设备的开发活动(例如ATC模型转换、算子和推理应用程序的纯代码开发)。如果想运行应用程序或进行模型训练等,需要通过MindStudio远程连接功能连接已部署好运行环境所需软件包的昇腾AI设备。
- 开发运行场景(共部署形态):在昇腾AI设备上安装MindStudio、Ascend-cann-toolkit开发套件包、npu-firmware安装包、npu-driver安装包和AI框架(进行模型训练时需要安装)。作为开发环境,开发人员可以进行普通的工程管理、代码编写、编译、模型转换等功能。同时可作为运行环境,运行应用程序或进行模型训练。
其中,不管哪种场景,都需要安装MindStudio、Ascend-cann-toolkit开发套件包:
- MindStudio:提供图形化开发界面,支持应用开发、调试和模型转换功能,同时还支持网络移植、优化和分析等功能。
- Ascend-cann-toolkit:开发套件包。为开发者提供基于昇腾AI处理器的相关算法开发工具包,旨在帮助开发者进行快速、高效的模型、算子和应用的开发。开发套件包只能安装在Linux服务器上,开发者可以在安装开发套件包后,使用MindStudio开发工具进行快速开发部署。
1.4 安装方案
1.4.1 安装方案——Linux
MindStudio和Ascend-cann-toolkit可以使用Linux服务器上原生桌面自带的终端gnome-terminal进行安装,也可以在Windows服务器上通过SSH登录到Linux服务器进行安装。
因为MindStudio是一款GUI程序,所以在Windows服务器上通过SSH登录到Linux服务器进行安装时,需要使用集成了X server的SSH终端(比如MobaXterm,该工具版本需要为v20.2及以上)。
- 纯开发场景(分部署形态):该场景下纯开发环境需要安装MindStudio和Ascend-cann-toolkit,如图2所示。昇腾AI设备上运行环境的安装操作请参见《CANN 软件安装指南》。

图2
- 开发运行场景(共部署形态):该场景下需要安装如图3所示软件包,其中驱动、固件、Ascend-cann-toolkit和AI框架包的安装操作请参见《CANN 软件安装指南》。

图3
1.4.2 安装方案——Windows
MindStudio可以单独安装在Windows上。在安装MindStudio前需要在Linux服务器上安装部署好Ascend-cann-toolkit开发套件包,之后在Windows上安装MindStudio,安装完成后通过配置远程连接的方式建立MindStudio所在的Windows服务器与Ascend-cann-toolkit开发套件包所在的Linux服务器的连接,实现全流程开发功能。
- 纯开发场景(分部署形态):该场景下在Windows服务器上安装MindStudio,昇腾AI设备上的驱动、固件、Ascend-cann-toolkit和AI框架包的安装操作请参见《CANN 软件安装指南》。

图4
- 开发运行场景(共部署形态):该场景下在Windows服务器上安装MindStudio,在纯开发环境需要安装Ascend-cann-toolkit,两者建立连接后,形成了集成MindStudio的纯开发环境。昇腾AI设备上运行环境的安装部署操作请参见《CANN 软件安装指南》,此场景运行环境多为端侧、边侧设备如Atlas 500 智能小站和Atlas 200 DK 开发者套件等。

图5
- Windows工控机场景:该场景下在Windows服务器上安装MindStudio、驱动、固件和Windows版nnrt,其中驱动、固件和Windows版nnrt需要参见《CANN Windows版用户指南》进行安装。纯开发环境需要安装Ascend-cann-toolkit,与MindStudio连接后基于两者开发的应用程序可在Windows服务器上运行。

图6
1.5 安装流程
1.5.1 安装流程——Linux

图7
Linux环境下,MindStudio安装流程如图7所示。
- 环境要求:MindStudio安装的环境要求如表1,可对照着判断是否满足条件。
表1 MindStudio环境要求
| 类别 | 限制要求 | 说明 |
|---|---|---|
| 硬件 | 内存:最小4GB,推荐8GB 磁盘空间:最小6GB | 若Linux宿主机内存为4G,在MindStudio中进行模型转换时,建议Model文件大小不超过350M,如果超过此规格,操作系统可能会因为超过安全内存阈值而工作不稳定。 若Linux宿主机配置升级,比如8G内存,则相应支持的操作对象规格按比例提升。 例如,内存由4G升级到8G,则Model文件建议大小不超过700M。 |
| 系统语言 | en_US.UTF-8 | 当前仅支持系统语言为英文。 请以任意用户使用locale命令在任意路径下查询编码格式,若系统返回“LANG=en_US.UTF-8”,则表示正确;否则,请以root用户使用“vim /etc/default/locale”命令修改“LANG=en_US.UTF-8”,重启(使用reboot命令)使之生效。 |
| 系统要求 | 操作系统可以通过ssh登录,同时打开ssh的X11Forwarding功能 glibc版本应大于或等于2.27 | ssh服务的开启和X11Forwarding的配置请参见启动MindStudio时无法显示图形化界面。 对于Docker环境,启动容器时需要映射ssh端口,如 docker run -p {宿主机端口}:{容器内ssh端口} … 若系统glibc版本小于2.27,请参见启动MindStudio时报glibc版本太低问题处理。 |
| 已验证支持的操作系统 | Ubuntu 18.04-x86_64 Ubuntu 18.04-aarch64 Ubuntu 20.04-x86_64 Ubuntu 20.04-aarch64 EulerOS 2.8-aarch64 EulerOS 2.9-aarch64 EulerOS 2.9-x86_64 EulerOS 2.10-aarch64 EulerOS 2.10-x86_64 OpenEuler 20.03-x86_64 OpenEuler 20.03-aarch64 OpenEuler 22.03 LTS-x86_64 OpenEuler 22.03 LTS-aarch64 CentOS 7.6/8.2-x86_64 CentOS 7.6/8.2-aarch64 银河麒麟OS V10 SP1-aarch64 中标麒麟OS 7.6-aarch64 |
- 准备软件包:软件安装前,请参考表2获取所需软件包和对应的数字签名文件。其中在软件数字签名验证方面,为了防止软件包在传递过程或存储期间被恶意篡改,下载软件包时需下载对应的数字签名文件用于完整性验证。在软件包下载之后,可以参考《OpenPGP签名验证指南》,对从网站下载的软件包进行PGP数字签名校验。如果校验失败,则不要直接使用该软件包,应先联系华为技术支持工程师解决。使用软件包安装/升级之前,也需要按上述过程先验证软件包的数字签名,确保软件包未被篡改过。
表2 软件包
| 软件包 | 说明 |
|---|---|
| MindStudio_{version}_linux.tar.gz | MindStudio软件包,含有GUI的集成开发环境。 MindStudio安装包解压后包含以下文件: · bin:MindStudio的执行目录及依赖的二进制文件 · build.txt:安装包构建信息 · classpath.txt:MindStudio运行时ClassPath加载顺序文件 · icons.db:MindStudio运行时SVG图标预编译数据库缓存文件 · Install-Linux-tar.txt:MindStudio安装说明 · jbr:64位系统的依赖库以及文件 · lib:Java依赖库 · license:所用的第三方依赖的许可证 · LICENSE.txt:Apache Licence说明文档 · NOTICE.txt:注意事项 · plugins:MindStudio所用到的基本插件及Java库 · product-info.json:MindStudio版本号以及执行文档路径 · redist:Java辅助注解 · tools:工具库 |
| Ascend-cann-toolkit_{version}_linux-{arch}.run | Ascend-cann-toolkit开发套件包,包含开发辅助工具和相关开发接口的开发套件包。 如果环境上已安装Ascend-cann-toolkit开发套件包,则无需再次获取。 |
- 准备安装用户:
如果已安装Ascend-cann-toolkit开发套件包,请使用Ascend-cann-toolkit开发套件包的安装用户安装MindStudio。
如果未安装Ascend-cann-toolkit开发套件包(可参考《CANN 软件安装指南》的“安装开发环境”章节),请执行如下操作:
创建安装用户
可使用root或非root用户进行安装。
-
若使用root用户安装,可直接开始安装依赖。
-
若使用已存在的非root用户安装,须保证该用户对$HOME目录具有读写以及可执行权限。
-
若使用新的非root用户安装,则需要先创建该用户,请参见如下方法创建(请以root用户执行以下命令)。
-
创建用户组和安装用户并设置该用户的$HOME目录。
其中usergroup为用户组,username为用户名。
groupadd usergroup useradd -g usergroup -d /home/username -m username -s /bin/bash以HwHiAiUser组为例,可执行如下命令创建软件包安装用户并加入到HwHiAiUser组中。
groupadd HwHiAiUser useradd -g HwHiAiUser -d /home/username -m username -s /bin/bash -
执行以下命令设置非root用户密码。
passwd username
-
-
安装依赖:安装MindStudio和Ascend-cann-toolkit开发套件包前需要安装相关依赖。具体的依赖列表可参考官方文档。
-
安装MindStudio:在完成了软件包至安装依赖,以及Ascend-cann-toolkit开发套件包的安装后,可以进行MindStudio的安装,其具体的安装步骤如下:
-
使用MindStudio的安装用户上传软件包至待安装环境。
-
解压MindStudio软件包:使用MindStudio的安装用户在软件包所在路径执行如下命令,解压MindStudio_{version}linux.tar.gz软件包,tar -zxvf MindStudio{version}_linux.tar.gz,解压后包的内容以及说明请参见表3。
表3 参数说明
参数 说明 Projects页签(工程管理) New Project 创建新工程,创建后工程保存在“$HOME/AscendProjects”目录。 Open 打开已有工程。 System Profiler 进入System Profiling界面。 Get from Version Control… 用版本控制工具下载代码仓并打开。 Customize页签(定制化个性设置) Color theme 设置颜色主题。 Accessibility 设置辅助功能,包括设置IDE字体大小和针对红绿色视觉缺陷调整颜色。 Keymap 设置键盘映射,MindStudio会根据您的环境自动建议预定义的键盘映射,请确保它与您正在使用的操作系统匹配,或者手动选择与您习惯使用的另一个IDE或编辑器中的快捷方式匹配的操作系统。 Import Settings… 从自定义配置目录导入MindStudio个性化设置。 All Settings… 进入设置界面。 Plugins页签(插件管理) Marketplace 插件市场,可搜索并下载需要的插件。 Installed 查看已安装的插件。 Learn MindStudio页签(MindStudio实用帮助) -
使用MindStudio的安装用户进入软件包解压后的MindStudio/bin目录并启动MindStudio。
-
进入导入设置界面,如图8所示界面。

图8
-
如果没有报错信息且能正常进入欢迎界面,则表示MindStudio安装成功。

图9
-
1.5.2 安装流程——Windows
将MindStudio安装在Windows服务器上时,Windows服务器为本地环境,Linux服务器为远端环境。MindStudio安装流程如图10所示。

图10
-
环境要求:
- 本地环境要求:Windows 10 x86_64操作系统
- 本地安装依赖:Python(版本要求:3.7~3.9),MinGW,Cmake,ACLlib(可选,Windows工控机场景开发Windows应用)
- 配置远端环境:
- 共部署形态远端昇腾AI设备:可参考《CANN 软件安装指南》部署好昇腾AI设备。
- 分部署形态远端纯开发环境:可根据远端Linux服务器的具体系统版本,参见准备安装用户、安装依赖和配置编译环境章节配置MindStudio使用环境。请参考《CANN 软件安装指南》安装Ascend-cann-toolkit开发套件包。
-
准备软件包:软件安装前,请参考表4获取所需软件包和对应的数字签名文件。
表4 软件包
软件包 说明 MindStudio_{version}_win.zip MindStudio免安装压缩包,含有GUI的集成开发环境。 MindStudio_{version}_win.exe MindStudio安装包,含有GUI的集成开发环境。 -
安装依赖:根据官方流程安装Python依赖,安装MinGW依赖,安装ACLlib包,安装Cmake。
-
安装MindStudio:在完成上述步骤,即可进行MindStudio的安装。
-
双击MindStudio_{version}_win.exe安装包,开始安装MindStudio。
-
进入MindStudio Setup界面,单击“Next”,如图11所示。
图11
-
选择MindStudio的安装路径后,单击“Next”,如图12所示。

图12
-
用户根据需要勾选安装选项后,单击“Next”,如图13所示。
图13
-
选择或创建MindStudio安装路径下的启动菜单文件夹,单击“Install”,如图14所示。
图14
-
开始安装MindStudio,完成后单击“Next”,如图15所示。

图15
-
完成MindStudio安装配置,单击“Finish”,如图16所示。
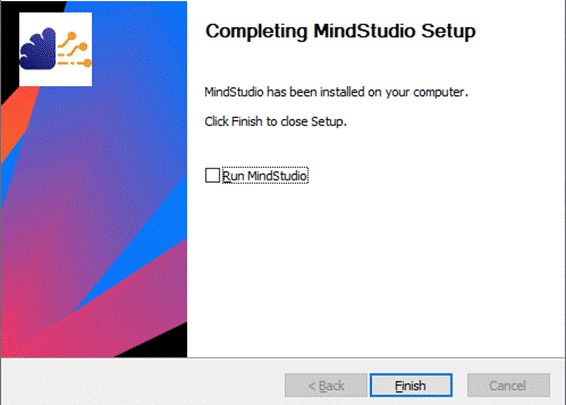
图16
-
进入MindStudio安装目录的bin文件夹,双击MindStudio应用程序启动MindStudio,导入设置界面,如图17所示界面。

图17
-
如果没有报错信息且能正常进入欢迎界面,则表示MindStudio安装成功,如图18所示。

图18
-
二、超参数优化基本介绍
在机器学习、深度学习中,有两类参数,一类需要从数据中学习和估计得到,称为模型参数(Parameter);另一类需要人为设定,称为超参数(Hyperparameter),例如学习率、正则化系数等。
超参数优化,是指用自动化的算法来优化超参数,从而提升模型的精度、性能等指标。使用HPO能力,可以快速高效地在超参数空间中测试选择最佳的超参数组合,节省大量人力和时间。
当前MindStudio提供的HPO能力支持Random、ASHA、BOHB、BOSS、PBT等HPO算法,适用于常见的深度神经网络的超参数优化,包括单目标优化和随机帕累托的多目标超参选择。
三、超参数优化前期准备工作
AutoML(Auto Machine Learning)包括模型自动生成和调优和训练工程超参数自动调优。昇腾模型开发用户可以通过模型自动性能调优功能找到性能更好的模型。AI初学者可以通过AutoML工具结合数据集,自动生成满足需求的模型,对训练超参进行自动调优。
- 训练工程超参数优化(Hyperparameter Optimization,简称HPO),支持在昇腾910 AI处理器上训练,覆盖MindSpore,PyTorch,TensorFlow框架,用自动化的算法来优化超参数,从而提升模型的精度、性能等指标。
- 模型自动生成和调优以昇腾910 AI处理器的搜索训练,昇腾310 AI处理器和昇腾310P AI处理器的推理验证为前提,覆盖MindSpore,PyTorch框架,面向分类、检测分割场景实现模型自动生成和调优。这个场景主要功能是基于数据集自动生成模型和基于预训练模型进行微调后自动生成模型。
业务流程如图19所示:

图 19
3.1 环境准备
-
使用AutoML工具前,可参考《CANN 软件安装指南》手册完成环境搭建,其他环境要求请参见训练服务器和推理服务器。
-
使用非root用户运行任务时,需要以root用户将运行用户加入驱动运行用户组(例如:HwHiAiUser)中,保证普通用户对run包的lib库有读权限。
-
集群配置中的训练和推理服务器需安装Vega,训练服务器安装noah_vega,推理服务器安装evaluate_service,具体可参考Vega官网自行安装。
-
noah_vega提供安全通信特性,相关配置请参照安全配置说明,用户在AutoML安装完成后需要参照该说明正确配置vega之后才能以通信安全的方式运行训练任务。如果使用1.8.0及以上版本的安全特性noah_vega包,启动任务时需要在命令末端增加“-s”参数。
-
用户根据需要自行安装以下AI框架包:
-
MindSpore:
请参考MindSpore官网安装MindSpore框架。
-
PyTorch:
-
请参考《CANN软件安装指南》的“安装PyTorch”章节编译安装PyTorch1.5.0框架。
-
安装Torchvision依赖,可参考以下方法进行安装:
-
在x86_64架构下安装Torchvision包:
pip3 install --user torchvision==0.6.0 -
在aarch64架构下先从azureology/torchvision下载源码,执行以下命令安装0.6.0版本的Torchvision包:
python setup.py install
-
-
若Pytorch下需要统计模型的参数量信息,则需要安装依赖thop:
pip3 install --user thop
-
-
TensorFlow:
参考《CANN 软件安装指南》安装tfplugin框架插件包和TensorFlow。
请注意CANN版本与MindSpore、PyTorch和TensorFlow的版本配套关系。
-
3.1.1 训练服务器
- 所有训练服务器的Python版本需要保持一致。
- 已安装sshd。
- 在各个训练服务器上的~/.bashrc文件中配置如下环境变量:
source $HOME/Ascend/ascend-toolkit/set_env.sh #请根据实际情况替换CANN软件包安装路径
source {$HOME/Ascend/tfplugin/set_env.sh #安装tfplugin时需要配置,请根据实际情况替换CANN软件包安装路径
#以下为单卡训练时的配置,请根据实际环境和需求配置
export DEVICE_ID=0 #单卡训练使用的device_id
#以下6项为多卡训练时的配置,请根据实际环境和需求改动
export RANK_ID=0 #指定调用卡的逻辑ID
export RANK_SIZE=8 #指定调用卡的数量
export RANK_TABLE_FILE=多卡环境组网信息json文件所在路径 #从多卡环境组网信息json文件中选择要使用的device_id
export NPU_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 #执行多卡任务时需要使用的device_id
export DEVICE_ID=0 #执行多卡训练任务时单卡阶段指定使用的device_id
export TF_CPP_MIN_LOG_LEVEL=3 #该项可控制TF框架本身日志级别的打印,0-DEBUG,1-INFO,2-WARNING,3-ERROR
说明
如果训练服务器中没有多卡环境组网信息json文件,请参见配置分布式环境变量在训练服务器上生成多卡环境组网信息json文件。当运行任务的用户为普通用户时,需要保证普通用户对该文件有可读权限。
3.1.2 推理服务器
- 在推理服务器上的~/.bashrc文件中配置如下环境变量:
source $HOME/Ascend/ascend-toolkit/set_env.sh #请根据实际情况替换CANN软件包安装路径
export install_path=$HOME/Ascend/ascend-toolkit/latest #请根据实际情况替换CANN软件包安装路径
export DDK_PATH=${install_path} #评估服务编译时使用
export NPU_HOST_LIB=${install_path}/{arch-os}/devlib #评估服务编译时使用
- 参见Link配置推理工具,并启动推理服务。
说明
推理工具中,-t参数为指定推理服务器的芯片型号,默认值Ascend310。若不使用该参数,默认在昇腾310 AI处理器上启动推理服务,参数取值如下。
- 昇腾310 AI处理器参数值:Ascend310(默认)
- 昇腾310P AI处理器参数值:Ascend310P*,例如Ascend310P1
其中,*根据芯片性能提升等级、芯片核数使用等级等因素会有不同的取值。请参考《ToolBox用户指南》的“Ascend-DMI工具使用>设备实时状态查询”章节查询芯片详细信息。
3.1.3 Vega的安全配置
要求:
1. Python3.9及以上
2. dask和distributed版本为2022.2.0
Vega的安全配置,包括如下步骤:
-
安装OpenSSL
首先要安装OpenSSL 1.1.1,从源码编译安装,或者直接安装编译后的发行包。
然后安装OpenSSL的python接口,如下:
pip3 install --user pyOpenSSL==19.0.0 -
生成CA根证书
执行如下命令生成CA证书:
openssl genrsa -out ca.key 4096 openssl req -new -x509 -key ca.key -out ca.crt -subj "/C=/ST= /L= /O= /OU= /CN= " 注意:
- 以上
、 、 、 、 、 - RSA密钥长度建议在3072位及以上,如本例中使用4096长度。
- 缺省证书有效期为30天,可使用-days参数调整有效期,如-days 365,设置有效期为365天。
- 以上
-
生成评估服务用的证书
评估服务支持加密证书和普通证书:
-
若使用加密证书,需要安装华为公司的KMC安全组件,参考生成加密证书章节
-
若使用普通证书,参考生成普通证书章节
-
生成加密证书
执行以下命令,获得证书配置文件:
-
查询openssl配置文件所在的路径:
openssl version -d在输出信息中,找到类似于OPENSSLDIR: “/etc/pki/tls”,其中"/etc/pki/tls"即为配置文件所在目录。
-
拷贝配置文件到当前目录:
cp /etc/pki/tls/openssl.cnf . -
在配置文件中openssl.cnf中,增加如下配置项:
req_extensions = v3_req # The extensions to add to a certificate request
执行如下脚本,生成评估服务器所使用的证书的加密私钥,执行该命令时,会提示输入加密密码,密码的强度要求如下:
-
密码长度大于等于8位
-
必须包含至少1位大写字母
-
必须包含至少1位小写字母
-
必须包含至少1位数字
-
必须包含至少1位特殊字符
openssl genrsa -aes-256-ofb -out server.key 4096
然后再执行如下命令,生成证书,并删除临时文件:
openssl req -new -key server.key -out server.csr -subj "/C=/ST= -config ./openssl.cnf -extensions v3_req openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt -extfile ./openssl.cnf -extensions v3_req rm server.csr/L= /O= /OU= /CN= " 执行如下脚本生成评估服务客户端所使用的证书的加密私钥,执行该命令时,会提示输入加密密码,密码的强度要求如服务器端私钥,且和服务器端私钥密码不同,请记录好该密码,后继还需使用:
openssl genrsa -aes-256-ofb -out client.key 4096然后再执行如下命令,生成证书,并删除临时文件:
openssl req -new -key client.key -out client.csr -subj "/C=/ST= -config ./openssl.cnf -extensions v3_req openssl x509 -req -in client.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client.crt -extfile ./openssl.cnf -extensions v3_req rm client.csr/L= /O= /OU= /CN= " -
-
生成普通证书
执行如下脚本,生成评估服务器端和客户端使用的证书的私钥和证书:
openssl genrsa -out server.key 4096 openssl req -new -key server.key -out server.csr -subj "/C=/ST= -config ./openssl.cnf -extensions v3_req openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt -extfile ./openssl.cnf -extensions v3_req rm server.csr openssl genrsa -out client.key 4096 openssl req -new -key client.key -out client.csr -extensions v3_ca -subj "/C=/L= /O= /OU= /CN= " /ST= -config ./openssl.cnf -extensions v3_req openssl x509 -req -in client.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client.crt -extfile ./openssl.cnf -extensions v3_req rm client.csr/L= /O= /OU= /CN= "
-
-
-
生成Dask用的证书
执行如下脚本,生成Dask服务器端和客户端使用的证书的私钥和证书:
openssl genrsa -out server_dask.key 4096 openssl req -new -key server_dask.key -out server_dask.csr -subj "/C=/ST= -config ./openssl.cnf -extensions v3_req openssl x509 -req -in server_dask.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server_dask.crt -extfile ./openssl.cnf -extensions v3_req rm server_dask.csr openssl genrsa -out client_dask.key 4096 openssl req -new -key client_dask.key -out client_dask.csr -subj "/C=/L= /O= /OU= /CN= " /ST= -config ./openssl.cnf -extensions v3_req openssl x509 -req -in client_dask.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client_dask.crt -extfile ./openssl.cnf -extensions v3_req rm client_dask.csr/L= /O= /OU= /CN= " 删除CA私钥:
rm ca.key -
加密私钥口令
若加密服务器使用加密证书,则需要执行本章节余下步骤,若使用普通证书,则跳过该章节。
加密生成评估服务的服务器端和客户端的私钥口令,需要安装华为公司KMC安全组件,并将该安全组件动态链接库所在的目录添加到LD_LIBRARY_PATH中。
export LD_LIBRARY_PATH=<Directory where the KMC dynamic link library is located>:$LD_LIBRARY_PATH接下来安装Vega,使用Vega的密码加密工具调用KMC安全组件对密码加密。 在执行如下命令时,请输入在生成私钥时输入的口令,该命令会生成加密后的口令,请注意保存,在配置文件中会使用到这两个加密后的口令:
vega-encrypt_key --cert=server.crt --key=server.key --key_component_1=ksmaster_server.dat --key_component_2=ksstandby_server.dat vega-encrypt_key --cert=client.crt --key=client.key --key_component_1=ksmaster_client.dat --key_component_2=ksstandby_client.dat -
配置安全相关的配置文件
请在当前用户的主目录下创建.vega目录,并将如上生成的秘钥、证书、加密材料等,拷贝到该目录下,并改变权限:
mkdir ~/.vega mv * ~/.vega/ chmod 600 ~/.vega/*说明:
-
如上的秘钥、证书、加密材料也可以放到其他目录位置,注意访问权限要设置为600,并在后继的配置文件中同步修改该文件的位置,需要使用绝对路径。
-
在训练集群上,需要保留ca.crt、client.key、client.crt、ksmaster_client.dat、ksstandby_client.dat、server_dask.key、server_dask.crt、client_dask.key、client_dask.crt,并删除其他文件。
-
评估服务上,需要保留ca.crt、server.key、server.crt、ksmaster_server.dat、ksstandby_server.dat,并删除其他文件。
-
以下为默认配置的加密套件:
ECDHE-ECDSA-AES128-CCM:ECDHE-ECDSA-AES256-CCM:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-DSS-AES128-GCM-SHA256:DHE-DSS-AES256-GCM-SHA384:DHE-RSA-AES128-CCM:DHE-RSA-AES256-CCM
如需缩小范围,可在client.ini与vega.ini中加入配置:
ciphers=ECDHE-ECDSA-AES128-CCM:ECDHE-ECDSA-AES256-CCM在~/.vega目录下创建server.ini和client.ini。
在训练集群中,需要配置/.vega/server.ini和/.vega/client.ini:
server.ini:
[security] # 以下文件路径需要修改为绝对路径 ca_cert=<~/.vega/ca.crt>server_cert_dask=<~/.vega/server_dask.crt> server_secret_key_dask=<~/.vega/server_dask.key> client_cert_dask=<~/.vega/client_dask.crt> client_secret_key_dask=<~/.vega/client_dask.key>client.ini:
[security] # 以下文件路径需要修改为绝对路径 ca_cert=<~/.vega/ca.crt> client_cert=<~/.vega/client.crt> client_secret_key=<~/.vega/client.key> encrypted_password=<加密后的client端的口令> # 如果使用普通证书, 此项配置为空 key_component_1=<~/.vega/ksmaster_client.dat> # 如果使用普通证书, 此项配置为空 key_component_2=<~/.vega/ksstandby_client.dat> # 如果使用普通证书, 此项配置为空在评估服务器上,需要配置~/.vega/vega.ini:
[security] # 以下文件路径需要修改为绝对路径 ca_cert=<~/.vega/ca.crt> server_cert=<~/.vega/server.crt> server_secret_key=<~/.vega/server.key> encrypted_password=<加密后的server端的口令> # 如果使用普通证书, 此项配置为空 key_component_1=<~/.vega/ksmaster_server.dat> # 如果使用普通证书, 此项配置为空 key_component_2=<~/.vega/ksstandby_server.dat> # 如果使用普通证书, 此项配置为空
-
-
配置评估服务守护服务
使用systemctl管理评估服务器进程,当进程出现异常时自动重启,保证评估服务器连续性。
首先创建一个启动评估服务的脚本run_evaluate_service.sh,内容如下,注意替换、 为真实IP和目录:
vega-evaluate_service-service -i <ip> -w <path>然后再创建一个守护服务的文件evaluate-service.service,脚本内容如下,注意替换为真实的脚本位置:
[Unit] Description=Vega Evaluate Service Daemon [Service] Type=forking ExecStart=/<your_run_script_path>/run.sh Restart=always RestartSec=60 [Install] WantedBy=multi-user.target然后将evaluate-service.service拷贝到目录/usr/lib/systemd/system中,并启动该服务:
sudo cp evaluate-service.service /usr/lib/systemd/system/ sudo systemctl daemon-reload sudo systemctl start evaluate-service -
配置HCCL白名单
请参考Ascend提供的配置指导。
-
注意事项
-
模型风险
对于AI框架来说,模型就是程序,模型可能会读写文件、发送网络数据。例如Tensorflow提供了本地操作API tf.read_file, tf.write_file,返回值是一个operation,可以被Tensorflow直接执行。 因此对于未知来源的模型,请谨慎使用,使用前应该排查该模型是否存在恶意操作,消除安全隐患。
-
运行脚本风险
Vega提供的script_runner功能可以调用外部脚本进行超参优化,请确认脚本来源,确保不存在恶意操作,谨慎运行未知来源脚本。
-
KMC组件不支持多个用户同时使用
若使用KMC组件对私钥密码加密,需要注意KMC组件不支持不同的用户同时使用KMC组件。若需要切换用户,需要在root用户下,使用如下命令查询当前信号量:
ipcs然后删除查询到的当前所有的信号量:
ipcrm -S '<信号量>' -
删除开源软件中不适用的私钥文件
Vega安装时,会自动安装Vega所依赖的开源软件,请参考列表。
部分开源软件的安装包中可能会带有测试用的私钥文件,Vega不会使用这些私钥文件,删除这些私钥文件不会影响Vega的正常运行。
可执行如下命令所有的私钥文件:
find ~/.local/ -name *.pem在以上命令列出的所有文件中,找到Vega所依赖的开源软件的私钥文件。一般私钥文件的名称中会带有单词key,打开这些文件,可以看到以-----BEGIN PRIVATE KEY-----开头,以-----END PRIVATE KEY-----结尾,这些文件都可以删除。
-
Horovod和TensorFlow
在安全模式下,Vega不支持Horovod数据并行,也不支持TensorFlow框架,Vega在运行前检查若是Horovod数据并行程序,或者TensorFlow框架,会自动退出。
-
限定Distributed仅使用tls1.3协议进行通信
若需要限定开源软件Distributed的组件间的通信仅使用tls1.3协议,需要配置~/.config/dask/distributed.yaml
distributed.yaml:
distributed: comm: tls: min-version: 1.3请参考Dask的配置指导。
-
3.2 集群管理
创建新集群
-
在菜单栏选择“Ascend > AutoML > Cluster Manager”。进入“Cluster Manager”界面。
-
单击“+New Cluster”。进入“Add Cluster”界面,如图20所示。界面参数说明如表5所示。

图 20
表5
参数 说明 Cluster Name 集群名称,在所有集群里具有唯一性。只支持英文字母、数字或者下划线,以英文字母开头,且长度不超过32个字符。例如:Cluster_01。 Evaluation Service 评估服务,通过下拉框选择已通过SSH配置好的远端环境。 Evaluation Service Port 评估服务器端口,仅支持输入1~65535之间的数字,默认值为8888。 Training Service 训练服务器,通过下拉框选择已通过SSH配置好的远端训练环境。 Primary 训练服务集群主节点,通过下拉框选择已通过SSH配置好的远端训练环境。 Add 添加训练服务。单击选择此项后,“Secondary”、“Data Sharing Service”和“NFS Server Path”参数才会在界面体现。 Secondary 训练服务集群从节点,通过下拉框选择已通过SSH配置好的远端训练环境。单击删除图标可以删除从节点。
删除集群
-
在菜单栏选择“Ascend > AutoML > Cluster Manager”。进入“Cluster Manager”界面。
-
单击需要删除的集群后方的,如图21所示。
图 21
四、模型开发使用HPO界面工具调优流程
4.1 前提条件
已安装1.1.3版本的pandas依赖包,执行以下命令以安装:
pip install pandas==1.1.3 --user
4.2 修改模型训练脚本
修改用户模型训练脚本,添加dump_objective函数,并在此脚本中调用此函数,保存待优化指标。代码段截图如图22所示。
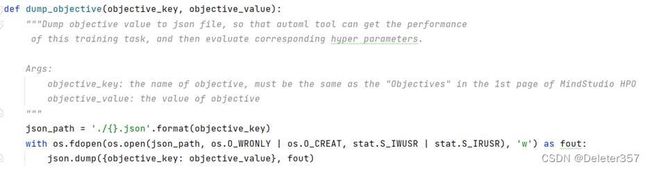
图22
用户可参考{CANN包安装路径}/ascend-toolkit/latest/tools/ascend_automl/algorithms /script_hpo/hpo_ui_sample.py进行操作,此样例使用以下语句保存平均耗时和精度指标。如图23所示。
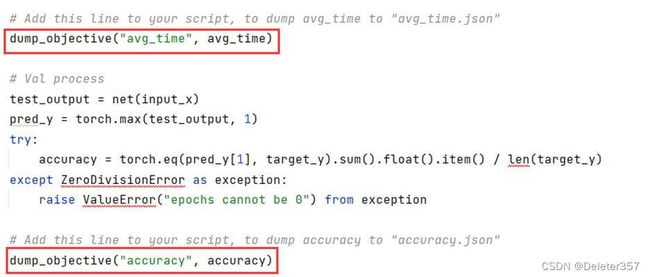
图23
其中dump_objective函数的入参objective_key要与步骤4.3中General Config页签中填写的Objectives优化目标一致,objective_value为用户脚本中优化目标值。
HPO功能在用户指定的搜索空间内,进行超参数采样,并对每一组超参数调起一个用户模型的训练任务。通过以上修改,用户脚本可在模型训练任务完成后,将超参数对应的精度、性能等信息传递给HPO主进程,以便后续选出最优超参。
4.3 配置 General Config
在菜单栏选择“Ascend > AutoML > HPO”,进入General Config页签,如图24所示。详细参数说明如表5所示。

图24
表 5 参数说明
| 参数 | 说明 |
|---|---|
| Compute Nodes Cluster | 计算集群选择。 |
| Parallel Search | 多卡或者单卡配置按钮,按钮开状态为多卡,关闭为单卡。 |
| Total Epochs | 搜索epoch配额。在HPO过程中,每个训练任务会消耗一定数量的epochs,所有训练任务的epoch总和小于此Total Epochs项。用户可参考Total Epochs*time_per_epoch / num_of_device来估算时间。 |
| Task Work Path | 当前运行用户目录下的工作路径,HPO过程的输出路径。需用户选定或者输入存在且有读权限路径,且文件路径中不包含非法字符。 |
| Search Alogorithom Type | 搜索算法,目前仅支持AshaHpo算法。 |
| Objectives | 优化目标,单击右侧“+”图标可添加需要优化的目标。在文本框中输入优化目标,例如平均精度、训练迭代耗时等。 l Max:表示期望优化目标最大化。 l Min:表示期望优化目标最小化。 单击右侧删除图标可以删除对应的优化目标参数项。 |
4.4 配置 Train Config
单击“Next”,进入Train Config页签,如图25所示。详细参数说明如表6所示。
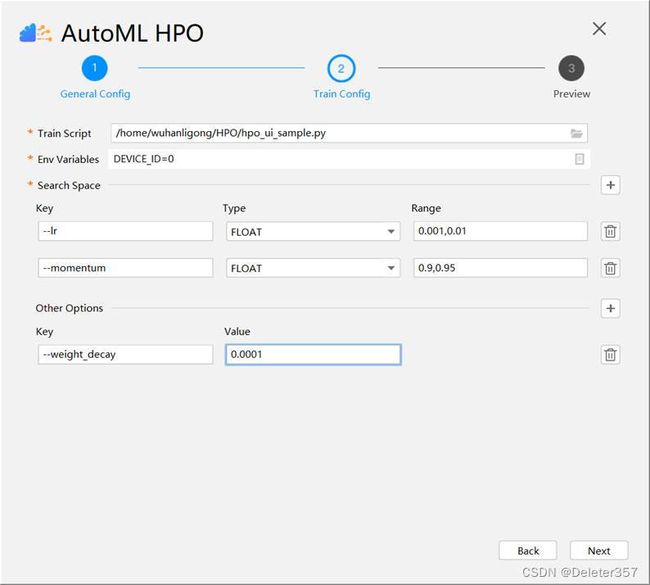
图25
表 6 参数说明
| 参数 | 说明 |
|---|---|
| Train Script | 4.2中的用户的模型训练脚本,需为存在的可读Python脚本,不包含非法字符。在HPO调优过程中会调用该脚本。 |
| Env Variables | 环境变量。单击右侧按钮添加环境变量。 l 当General Config页签开启Parallel Search参数时,需配置以下环境变量: NPU_VISIBLE_DEVICES:可用的device。 RANK_SIZE:device列表长度。 RANK_TABLE_FILE:组网信息文件(若在环境准备已配置该环境变量,则不用在此处进行配置)。用户需要先配置组网信息文件,具体可参考https://www.mindspore.cn/tutorial/training/zh-CN/r1.2/advanced_use/distributed_training_ascend.html。 BATCH_TASK_INDEX:任务编号,一般配置为0。 l 当General Config页签关闭Parallel Search参数时,需配置DEVICE_ID实现在指定卡上运行。 |
| Search Space | 搜索空间,单击右侧的“+”按钮可以添加以下搜索内容。 l Key:搜索关键字,需要优化的用户脚本输入参数名,这里需要优化的是“lr”和“momentum”参数,因此填“–lr”和“–momentum”,必填项。 l Type:搜索类型。支持CATEGORY、BOOL、INT、INT_EXP、FLOAT、FLOAT_EXP,必填项。 l Range:当前Key的搜索范围。需手动输入,内容用英文逗号分隔,必填项。 单击删除图标可以删除对应的搜索空间。 说明: 搜索类型可选以下六种: l CATEGORY 分组类型,用户在Range中给出可选的取值,可以为任意的数据类型,如:[18, 34, 50, 101],[0.3, 0.7, 0.9],[‘Adam’, ‘SGD’],[[1, 0, 1],[0, 0, 1]]。 l BOOL 布尔类型,对应Range取值为[True, False]。 l INT 整数类型,对应Range设置最小值和最大值,均匀采样,如:[10, 100]。 l INT_EXP 整数类型,对应Range设置最小值和最大值,指数采样,如:[1, 100000]。 l FLOAT 浮点数类型,对应Range设置最小值和最大值,均匀采样,如:[0.1, 0.9]。 l FLOAT_EXP 浮点数类型,对应Range设置最小值和最大值,指数采样,如:[0.1, 100000.0]。 |
| Other Options | 其他参数项,单击右侧的“+”按钮可以添加不需要优化的参数。 l Key:不需要优化的用户脚本入参名,可选项。示例中不需要优化的有“–weight_decay”参数,因此填入“–weight_decay” l Value:用户指定的入参值,选填项。 单击删除图标可以删除对应的其他参数项。 |
| Epoch Name | 在HPO的不同阶段,对网络训练不同的epoch,这一epoch值由HPO进程给出,不需用户指定。因此,用户需将脚本入参中,代表epoch的参数名称,填入此栏,以便HPO过程中将HPO算法给出的epoch值传入用户脚本。 例如:4.2中示例,此项应填“–epochs ” 说明: 如果待优化的训练脚本不能传入epoch参数,需要用户将训练脚本修改为能传入epoch参数的形式。 |
| Device Name | 在HPO过程中,启动多个训练任务,使用不同的超参数进行网络训练。不同的训练任务使用不同的AI芯片,AI芯片ID由HPO进程给出,不需用户指定。因此,用户需将脚本入参中,代表AI芯片ID的参数名称,填入此栏,以便HPO过程中将这一参数自动传入用户脚本。 例如:1中示例,此项应填“–device” 说明: l 如果待优化的训练脚本不能传入该device参数,需要用户将训练脚本修改为能传入device参数的形式。 l 传入的device值的格式为“npu:x”,其中x可能为0,1,2,3,4,5,6,7。 |
4.5 预览配置结果
单击“Next”,进入Preview页签,如图26、27所示。
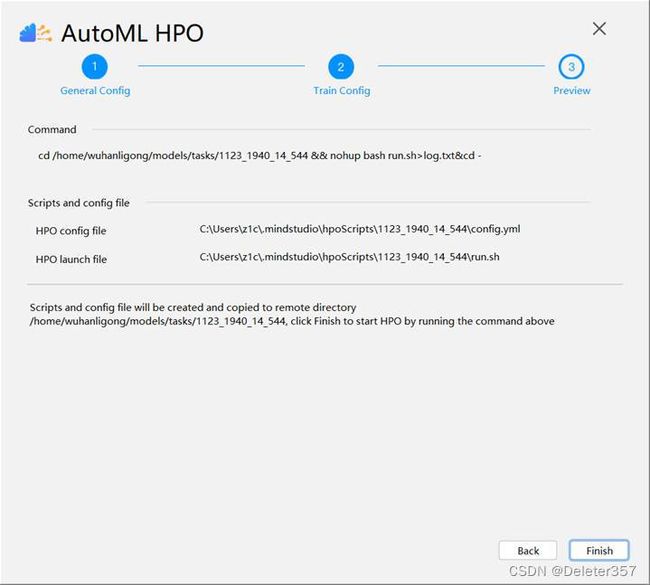
图26
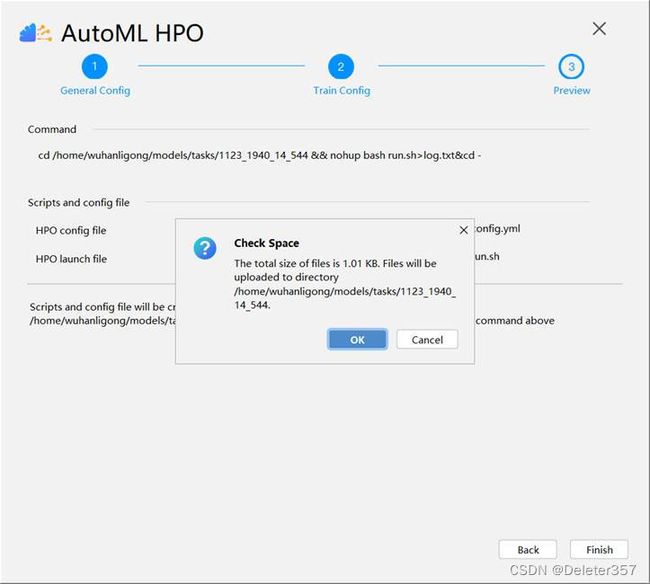
图27
基于前面的两个配置界面,可以生成配置文件config.yml,接口文件train.py,启动文件run.sh,并发送到远端服务器,调起HPO任务。此页面提供命令行命令的预览。单击“Finish”之后运行HPO任务。如图28、29、30所示
说明
可使用vega-process查询正在运行的任务,使用vega-kill -p PID或vega-kill -t task_id结束正在运行的vega任务。

图28
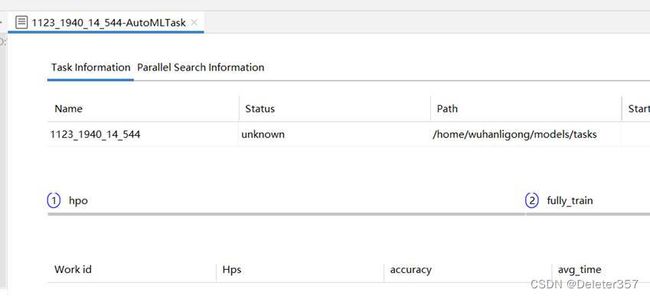
图29
![]()
图30
4.6 过程和结果获取
任务开始后,HPO窗口关闭,Output窗口中将提示可到远端查看HPO任务运行过程和结果,如图31~35所示。

图31
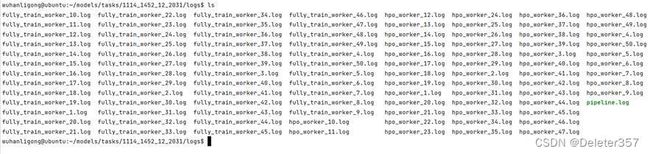
图32

图33
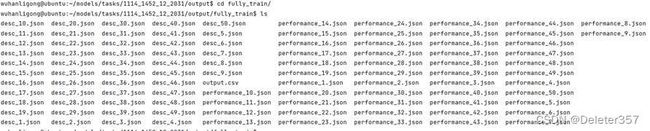
图34
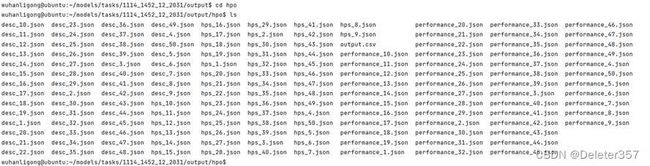
图35
在Output窗口所示路径下会生成tasks文件夹,tasks文件夹下有名为{task_id}的文件夹,此文件下有文件夹logs、output和workers。
├── tasks
│ ├── {task_id}
│ │ ├──logs
│ │ │ ├──hpo_worker_{worker_id}。log // 第worker_id个worker上进行hpo的日志文件
│ │ │ ├──pipeline.log // 整个hpo任务日志文件
│ │ ├──output
│ │ │ ├──config.yml // 配置文件
│ │ │ ├──report.json // hpo任务的报告文件
│ │ │ ├──hpo
│ │ │ │ ├──hps_{worker_id}.json //搜索出的最佳超参值
│ │ │ │ ├──performance_{worker_id}.json //搜索出的最佳优化指标值
│ │ │ │ ├──output.csv //优化指标值汇总文件
│ │ ├──workers
│ │ │ ├──hpo
│ │ │ │ ├──{worker_id}
│ │ │ │ │ ├──hps_{worker_id}.json //超参值
│ │ │ │ │ ├──performance_{worker_id}.json //优化目标值
五、经验总结
利用HPO界面调优会在所指定的路径下生成相应的执行文件,直接在后台执行run.sh文件会报错。

图36
解决办法:可更改生成的config.yml文件中的task_id为非纯数字的名称,然后利用vega config.yml -d NPU命令在后台执行HPO调优。
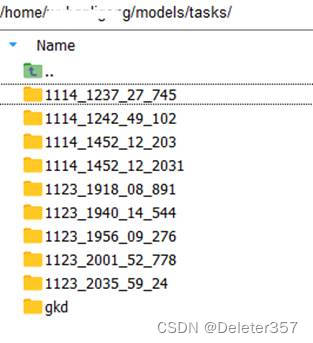

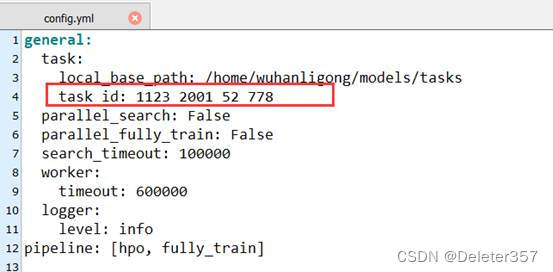
图37
六、关于MindStudio更多的内容
如果需要了解关于MindStudio更多的信息,请查阅昇腾社区中MindStudio的用户手册,里面模型训练、脚本转换、模型开发、算子开发、精度对比、AI Core Error分析工具、AutoML工具(Beta)、Benchmark工具、专家系统工具等各种使用安装操作的详细介绍。
如果在使用MindStudio过程中遇到任何问题,也可以在昇腾社区中的昇腾论坛进行提问,会有华为内部技术人员对其进行解答,如下图。
图38