AFDet: Anchor Free One Stage 3D Object Detection
论文链接:https://arxiv.org/pdf/2006.12671v1.pdf
前言
在嵌入式系统上操作的高效点云3D目标检测对于包括自动驾驶在内的许多机器人应用来说都是重要的。
大多数以前的工作都试图使用基于Anchor的检测方法来解决这个问题,这些方法有2个缺点:
- 后处理相对复杂且计算昂贵
- 调整Anchor参数很复杂
本文是第一个使用Anchor-free和NMS-Free的单阶段检测器AFDet解决这些缺点的算法
整个AFDet可以通过简化的后处理在CNN加速器或GPU上高效处理。
在没有附加功能的情况下
本文提出的AFDet在KITTI验证集和Waymo开放数据集验证集上与其他基于Anchor的方法相比也具有一定的竞争力。
简介
检测点云中的3D目标是自动驾驶最重要的感知任务之一
为了满足功率和效率的限制,大多数检测系统都在车辆嵌入式系统上运行
开发嵌入式系统友好的点云3D检测系统是实现自动驾驶的关键步骤
由于点云的稀疏性,直接在原始点云上应用3D或2D卷积神经网络(CNN)是低效的
一方面,引入了许多点云编码器来将原始点云编码为3D或2D CNN可以有效处理的数据格式
另一方面,一些工作直接从原始点云中提取特征用于3D检测,这是PointNet的启发
但在检测部分,大多数采用了在图像目标检测任务中被证明有效的基于Anchor的检测方法
基于Anchor的方法有2个主要缺点:
第一
非最大抑制(NMS)是基于Anchor的方法抑制重叠的高置信度检测边界框所必需的
但它可能会引入比较大的计算成本,尤其是对于嵌入式系统
即使在具有高效实现的现代高端桌面CPU上,处理一个KITTI点云帧也需要20毫秒以上,更不用说通常用于嵌入式系统的CPU了
第二
基于Anchor的方法需要Anchor选择,这既复杂又耗时,因为调整的关键部分可能是手动试错过程
每次向检测系统添加新的检测类别时,都需要选择诸如合适的Anchor数量、Anchor尺寸、Anchor角度和Anchor密度等超参数
可以摆脱NMS,设计一个高效的嵌入式系统友好的Anchor-Free点云3D检测系统吗?
图像检测中的Anchor-Free方法取得了显著的性能
在这项工作中,作者提出了一种具有简单后处理的Anchor-Free和无NMS的单阶段端到端点云3D目标检测器(AFDet)
在作者的实验中,使用PointPillars将整个点云编码为鸟瞰图(BEV)中的伪图像或类似图像的特征图
然而,AFDet可以与生成伪图像或类似图像的2D数据的任何点云编码器一起使用
编码后,应用具有上采样Neck的CNN输出特征图
该特征图连接到5个不同的头部,以预测BEV平面中的目标中心,并回归3D边界框的不同属性
最后,将5个头的输出组合在一起以生成检测结果
关键点热图预测头用于预测BEV平面中的目标中心
它将把每个物体编码成一个以heatmap为中心的小区域
在推断阶段,每一个heatmap值都将通过最大池化操作进行挑选
在此之后,不再将多个回归Anchor平铺到一个位置,因此不需要使用传统的NMS
这使得整个检测器可以在典型的CNN加速器或GPU上运行,为自动驾驶中的其他关键任务节省了CPU资源
总结
- 提出了一种Anchor-Free和无NMS检测器,用于简化后处理的点云3D目标检测
- AFDet是嵌入式系统友好的,可以以更少的工程工作量实现高处理速度
- 在KITTI验证集上,AFDet可以实现与以前的单阶段检测器相比具有竞争力的精度
- AFDet的一种变体在Waymo验证上超越了最先进的单阶段3D检测方法
相关工作
LiDAR-based 3D Object Detection
由于长度和顺序不固定,点云呈稀疏且不规则的格式,需要在输入神经网络之前对其进行编码
一些工作利用网格网格对点云进行体素化
诸如密度、强度、高度等特征在不同的体素中被连接为不同的通道
体素化点云被投影到不同的视图,例如BEV、距离视图(RV)等
以通过2D卷积处理,或者被保持在3D坐标中,以通过稀疏3D卷积处理
PointNet提出了一种使用原始点云作为输入进行3D检测和分割的有效解决方案
PointNet使用多层感知器和最大池化操作来解决点云的无序和非均匀性,并提供了令人满意的性能
基于原始点云输入的连续3D检测解决方案提供了有前景的性能,如PointNet++、Frustum PointNet、PointR CNN和STD
VoxelNet结合了体素化和PointNet,提出了体素特征提取器(VFE),其中在每个体素内实现了PointNet风格的编码器
尽管稀疏3D卷积被用于在VFE之后在z轴上进一步提取和下采样信息,但在SECOND中使用了类似的思想
VFE显著提高了基于LiDAR的检测器的性能,然而,使用从数据中学习的编码器,检测流水线变得更慢
PointPillars建议将点云编码为pillar而不是体素。结果,整个点云变成BEV伪图像,其通道等效于VFE的输出通道,而不是3个
在基于Anchor的方法中,为边界框编码提供预定义的框
然而,使用密集Anchor会导致大量潜在目标对象,这使得NMS成为一个不可避免的问题
之前的一些工作提到了Anchor-free概念
PointRCNN提出了一种基于全场景点云分割的Anchor-free box的3D proposals生成子网络
VoteNet从投票的兴趣点而不是预定义的Anchor框构建3D边界框
但它们都不是无NMS的,这使得它们效率较低,对嵌入式系统也不友好
此外,PIXOR是一个BEV检测器,而不是3D检测器
Camera-based 3D Object Detection
基于摄像头的解决方案随着降低成本的意愿而蓬勃发展
随着越来越复杂的网络的设计,基于摄像头的解决方案正在迅速赶上基于激光雷达的解决方案
MonoDIS利用了2D和3D检测损失的新颖解纠缠变换和3D边界框的新颖自监督置信分数
它在nuScenes 3D目标检测挑战中排名第一
CenterNet从特征图上的边界框中心预测目标的位置和类别
虽然最初设计用于2D检测,但CenterNet也有可能使用单摄像头进行3D检测
TTFNet提出了缩短训练时间和提高推理速度的技术
RTM3D预测图像空间中3D边界框的9个透视关键点,并利用几何规则恢复3D边界框
方法

将从3个方面详细介绍AFDet:点云编码器、Anchor-free检测器以及Backbone and Necks
点云编码器
为了进一步挖掘Anchor-free检测器的效率潜力,本文使用PointPillars作为点云编码器,因为其速度快
首先,将检测范围离散为鸟瞰图(BEV)平面(也是x-y平面)中的pillar
不同的点根据其x-y值指定给不同的pillar。在这一步骤中,每个点也将增加到D=9维
其次,具有足够数量点的预定义P数量的pillar将应用于线性层和最大池化操作,以创建大小为 F ∗ P F*P F∗P的输出张量
其中F是PointNet中线性层的输出通道数
由于P是所选pillar的数量,因此它们在整个检测范围内与原始pillar不是一一对应的
因此,第三步是将选定的Ppillar散射到它们在检测范围上的原始位置
之后,可以得到伪图像 I I I
尽管使用PointPillars作为点云编码器,但Anchor-free检测器与生成伪图像或类似图像的2D数据的任何点云编码器兼容
Anchor Free检测器
Anchor-free检测器由5个头组成
它们是keypoint heatmap head、 local offset head、z-axis location head、 3D object size head 和orientation head
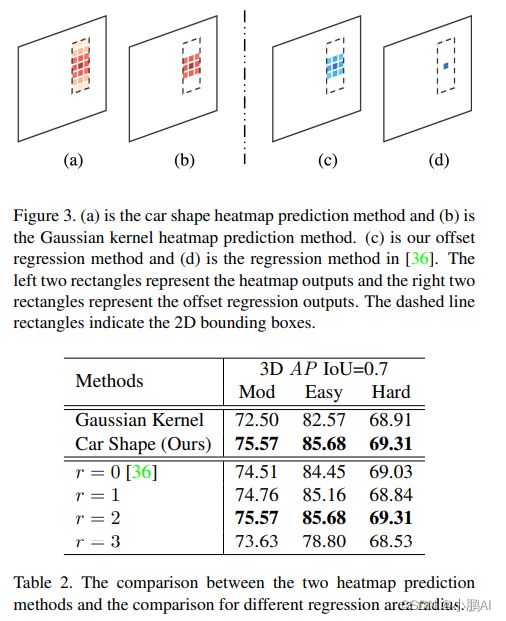
关键点heatmap用于查找目标中心在BEV中的位置
offset regression图有助于heatmap在BEV中找到更精确的目标中心,也有助于恢复pillar化过程导致的离散化误差

对于 offset regression head,有两个主要功能
首先,它用于消除由pillar化过程引起的误差,在pillar化过程中,将浮动目标中心分配给BEV中的整数pillar位置
第二,它在细化heatmap目标中心的预测中起着重要作用,特别是当heatmap预测错误的中心时
具体而言,一旦heatmap预测到距离GT中心数个像素的错误中心,offset head就能够减轻甚至消除对GT目标中心的数个像素误差
在offset regression 图中围绕目标中心像素选择半径为R的正方形区域。到目标中心的距离越远,偏移值就越大
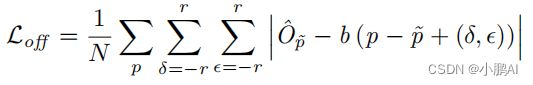
z轴位置回归
在BEV中定位目标之后,只有目标的x-y位置。因此,有z轴的位置头来回归z轴的值。使用L1损失直接回归z值
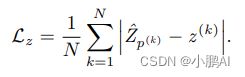
大小回归
回归的训练损失也是L1的损失
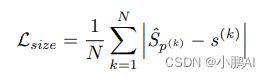
方向预测
目标k的方向是围绕垂直于地面的z轴旋转的标量角度
按照CenterNet将其编码为8个标量,每个bin有4个标量
2个标量用于softmax分类,另外2个用于角度回归
2个bin的角度略有重叠
损失函数
已经描述了每个损失。总的训练损失函数是
![]()
其中,λ表示每个头的权重。对于所有的回归头,包括局部偏移量、z轴位置、大小、方向回归
收集索引并解码
在训练阶段,不对整个特征映射进行反向传播。相反,只反向传播作为所有回归头的目标中心的索引
在推理阶段,使用最大池化和and操作来寻找在CenterNet之后的预测heatmap中的峰值,这比基于iou的NMS更快、更有效
在最大池化和and操作之后,可以从关键点heatmap中轻松地收集每个中心的索引
Backbone and Necks
在这项工作中对主干进行了几个关键修改,以支持Anchor-free检测器。网络包括主干部分和neck部分
主干部分类似于分类任务中使用的网络,该网络用于提取特征
neck部分用于对特征进行上采样,以确保来自主干的不同块的所有输出具有相同的空间大小,以便可以沿一个轴连接它们
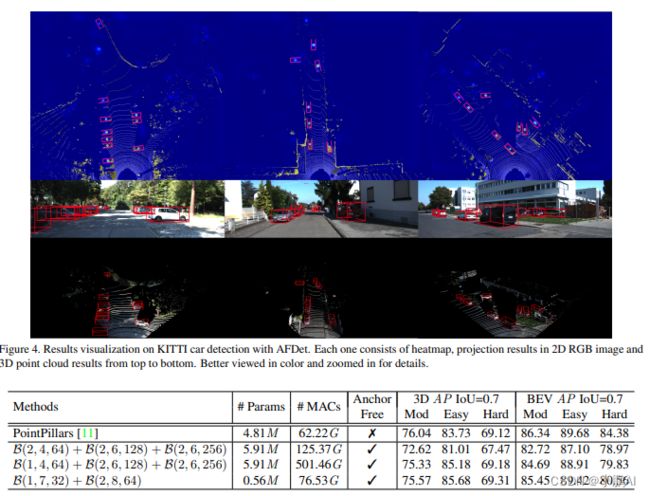
图2显示了主干和neck的细节。
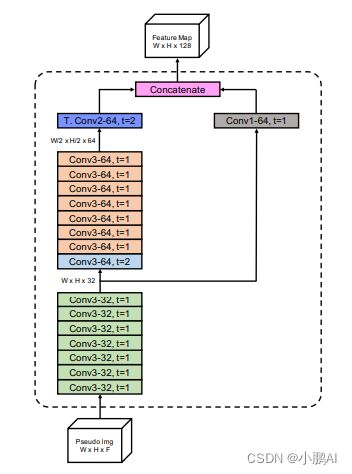
在生成特征图的过程中,不进行降采样,这对于保持KITTI数据集的类似检测性能至关重要
减少下采样步长只会增加FLOP,因此作者还减少了主干和Neck的过滤器数量。事实证明,主干和Neck的FLOP较少
实验