3.DataSet API
DataSet API
文章目录
- DataSet API
-
- 一.DataSet API介绍
- 二.DataSet API
-
- 1.DataSources数据接入
-
- 1)文件类数据
- 2)集合类数据
- 3)通用数据接口
- 4)第三方文件系统
- 2.DataSet 转换操作
-
- 1)数据处理
- 2)聚合操作
- 3)多表关联
- 4)集合操作
- 5)排序操作
- 3.DataSinks数据输出
-
- 1)基于文件输出接口
- 2)通用输出接口
- 三.迭代计算
-
- 1.全量迭代
- 2.增量迭代
- 四.广播变量与分布式缓存
-
- 1.广播变量
- 2.分布式缓存
- 五.语义注解
-
- 1.Forwarded Fields注解
-
- 1)函数注解方式
- 2)算子参数方式
- 2.Non-Forwarded Fields
- 3.Read Fields注解
一.DataSet API介绍
DataSet API用来处理批量数据。Flink将接入数据转换成DataSet数据集,并行分布在集群中的每个节点上,基于DataSet数据集完成各种转换操作(map、filter等),并通过DataSink操作将结果输出到外部系统中。
-
开发环境配置
在使用Flink DataSet API进行批量应用程序开发之前,需要在工程中引入Flink批量计算相关依赖库,可以在项目工程中的pom.xml文件中添加flink-java对应的Dependency配置,引入DataSet API所需要的依赖库,用户可以根据需要选择Java版本或者Scala版本,也可以将两个依赖库同时引入工程。
//基于java版本的批量计算依赖库 <dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-javaartifactId> <version>1.7.0version> dependency> //引入Scala版本的批量计算依赖库 <dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-scala_2.11artifactId> <version>1.7.0version> dependency> -
Flink DataSet API wordcount 实例
import org.apache.flink.api.scala._ //批处理的WordCount object WordCount { def main(args:Array[String]): Unit={ //创建一个批处理的执行环境 val env:ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment //定义转换操作 //1.从文件中读取数据 val inputPath:String = "D:\\software\\IDEA\\work_space\\src\\main\\resources\\hello.txt" val inputDataSet:DataSet[String] = env.readTextFile(inputPath)//scala具有自动类型推断,类型可写可不写 //2.对数据进行转换处理统计,先分词,再按照word进行分组,最后进行聚合统计 val resultDataSet:DataSet[(String,Int)] = inputDataSet. flatMap(_.split(" ")) .map((_,1))//第一个元素为word,第二个为1 .groupBy(0) .sum(1) //按照第一个元素作为Key进行分组,针对第二个元素进行求和统计 //打印输出 resultDataSet.print() } } //如果使用Scala语言编写DataSet API程序,需要引入相应隐式的方法 DataSet API需要创建ExecutionEnvironment环境,然后使用ExecutionEnvironment提供的方法读取外部数据,将外部数据转换成DataSet数据集,最后在创建好的数据集上应用DataSet API提供的Transformation操作,对数据进行转换,处理成最终的结果,并对结果进行输出。
二.DataSet API
1.DataSources数据接入
DataSet API数据接入接口共有三种类型:文件系统类型、Java Collection类型,以及通用类数据源。同时在DataSetAPI中可以自定义实现InputFormat/RichInputFormat接口,以接入不同数据格式类型的数据源,常见的数据格式有CsvInputFormat、TextInputFormat、SequenceFileInputFormat等。
1)文件类数据
-
readTextFile(path)/TextInputFormat
//读取本地文件 val textFiles:DataSet[String] = env.readTextFile("file:///path/textfile") //读取HDFS文件 val hdfsFiles = env.readTextFile("hdfs://nnHost:nnPort/path/textfile") -
readTextFileWithValue(path)/TextValueInputFormat
读取文本文件内容,将文件内容转换成DataSet[StringValue]类型数据集。StringValue是一种可变的String类型,通过StringValue存储文本数据可以有效降低String对象创建数量,从而降低系统性能上的开销。
//读取本地文件,指定读取字符格式类型为UTF-8 val ds = env.readTextFileWithValue("file:///path/textfile","UTF-8") -
readCsvFile(path)/CsvInputFormat
//读取指定分隔符切割的CSV文件,且可以直接转换成Tuple类型、Case Class对象或者POJOs类。在方法中可以指定行切割符、列切割、字段等信息 val csvInput = env.readCsvFile[(String,Double)]( "hdfs://nnHost:nnPort/path/to/csvfile", includedFields = Array(0,3)) -
readSequenceFile(Key_Class,Value_Class,path)/SequenceFileInputFormat
//读取SequenceFileInputFormat类型的文件,在参数中指定Key Class和Value Class类型,放回结果为Tuple2[Key,Value]类型。 val tuples = env.readSequenceFile(classof[IntWritable],classof[Text],"hdfs://nnHost:bbPort/path/to/file")
2)集合类数据
-
fromCollection(Seq)
从给定集合中创建DataSet数据集,集合类型可以是数组、List等,也可以从非空Iterable中创建,需要指定数据集的Class类型。
//从Seq中创建DataSet数据集 val dataSet:DataSet[String] = env.fromCollection(Seq("flink","hadoop","spark")) //从Iterable中创建DataSet数据集 val dataSet:DataSet[String] = env.fromCollection(Iterable("flink","hadoop","spark")) -
fromElements(elements:_*)
//从给定数据元素序列中创建DataSet数据集,且所有的数据对象类型必须一致 val dataSet:DataSet[String] = env.fromElements("flink","spark","hadoop") -
generateSequence(from,to)
//指定from到to范围区间,然后在区间内部生成数字序列数据集 val numbers:DataSet[Long] = env.generateSequence(1,10000000)
3)通用数据接口
DataSet API中提供了Inputformat通用的数据接口,以接入不同数据源和格式类型的数据。InputFormat接口主要分为两种类型:一种是基于文件类型,在DataSet API对应readFile()方法;另外一种是基于通用数据类型的接口,例如读取RDBMS或NoSQL数据库等,在DataSet API中对应 creatInput() 方法。
-
readFile(inputFormat,path)/FileInputFormat
//自定义文件类型输入源,将指定格式文件读取并转换成DataSet数据集。 env.readFile(new PointInFormat(),"file:///path/file") -
createInput(inputFormat)/InputFormat
自定义通用型数据源,将读取的数据转换为DataSet数据集。如以下实例使用Flink内置的JDBCInputFormat,创建读取mysql数据源的JDBCInputFormat,完成从mysql中读取Person表,并转换成DataSet[Row]数据集
//通过创建JDBCInputFormat读取JDBC数据源 val jdbcDataSet:DataSet[Row] = env.createInput( JDBCInputFormat.buildJDBCInputFormat() .setDrivername("com.mysql.jdbc.Driver") .setDBUr1("jdbc:mysql://localhost:3306/test") .setQuery("select id,name from person") .setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.LONG_TYPE_INFO,BsaicTypeInfo.STRING_TYPE_INFO)) .finish() )
4)第三方文件系统
为简化用户和其他第三方文件系统之间的交互,Flink针对常见类型数据源提出通用的FileSystem抽象类,每种数据源分别继承和实现FileSystem抽象类,将数据从各个系统中读取到Flink中。DataSet API中内置了HDFS数据源、Amazon S3、MapR file system,Alluxio等文件系统的连接器。可以参考官方文档说明进行使用。
2.DataSet 转换操作
转换操作的实质是将DataSet转换成另外一个新的DataSet,然后将各个DataSet的转换连接成有向无环图,并基于Dag完成对批量数据的处理。
1)数据处理
-
Map
完成对数据集Map端的转换,并行将每一条数据转换成一条新的数据,数据分区不发生变化。
val dataSet:DataSet[String] = env.fromElements("flink","hadoop","spark") val transformDS:DataSet[String] = dataSet.map(x => x.toUpperCase) -
FlatMap
将接入的每一条数据转换成0条、1条或者多条输出。例如以下实例将文件中的每一行文本切割成单词集合。
val dataSet:DataSet[String] = env.fromElements("flink,hadoop,spark") val words = dataSet.flatMap{_.split(",")} -
MapPartition
功能和Map函数类似,只是MapPartiion操作时在DataSet中基于分区对数据进行处理,函数调用中会按照分区将数据通过Iterator的形式传入,并返回任意数量的结果值。
val dataSet:DataSet[String] = env.fromElements("flink","hadoop","spark") dataSet.MapPartition{in => in.map{(_,1)}} -
Filter
根据条件对传入数据进行过滤,当条件为True后,数据元素才会传输到下游的DataSet数据集中。
val dataSet:DataSet[Long] = env.fromElements(222,12,34,323) val resultDs = dataSet.filter(x => x>100)
2)聚合操作
-
Reduce
通过两两合并,将数据集中的多个元素合并成一个元素,可以在整个数据集上使用,也可以和Group Data Set结合使用。
val dataSet: DataSet[Long] = env.fromElements(222,12,34,323) val result = dataSet.reduce((x,y) => x+y) -
ReduceGroup
将一组元素合并成一个或者多个元素,可以在整个数据集上使用,也可以和Group Data Set结合使用。
val dataSet:DataSet[Long] = env.fromElements(22,1,321,231) dataSet.reduceGroup{collector => collector.sum} -
Aggregate
通过Aggregate Function将一组元素值合并成单个值,可以在整个DataSet数据集上使用,也可以和Group Data Set结合使用。如下代码是,在DataSet数据集中根据第一字段求和,根据第三个字段求最小值。
val dataSet:DataSet[(Int,String,Long)] = env.fromElements((12,"Alice",34),(12,"Alice",34),(12,"Alice",34)) val result:DataSet[(Int,String,Long)] = dataSet.aggregate(Aggregations.SUM,0).aggregate(Agregations.Min,2) //也可以使用Aggregation函数的缩写方法,sum()、min()、max()等 val result2:DataSet[(Int,String,Long)] = dataSet.sum(0).min(2) -
Distinct
求取DataSet数据集中的不同记录,去除所有重复的记录。
val dataSet:DataSet[Long] = env.fromElements(22,123,532,51) val distinct:DataSet[Long] = dataSet.distinct
3)多表关联
-
Join
根据指定的条件关联两个数据集,然后根据选择的字段形成一个数据集。关联的key可以通过key表达式、Key-selector函数、字段位置以及Case Class字段指定。
对于两个Tuple类型的数据集可以通过字段位置进行关联,左边数据集的字段通过where方式指定,右边数据集字段通过equalTo()方式指定。
val dataSet1:DataSet[(Int,String)] = …… val dataSet2:DataSet[(Double,Int)] = …… val result = dataSet1.join(dataSet2).where(0).equalTo(1) 对于Case Class类型的数据集可以直接使用字段名称作为关联Key。
val dataSet1:DataSet[Person] = env.fromElements(Person(1,"Peter"),Person(2,"Alice")) val dataSet2:DataSet[(Double,Int)] = env.fromElements((12.3,1),(23.3,3)) val result = dataSet1.join(dataSet2).where("id").equalTo(1) 可以在关联的过程中指定自定义Join Function,Function的入参为左边数据集中的数据元素和右边数据集中的数据元素所组成的元组,并返回一个经过计算处理后的数据,其中Left和right的Key相同。
val result = dataSet1.join(dataSet2).where("id").equalTo(1){ (left,right) => (left.id,left.name,right_1+1) } Join Function中同时提供了FlatJoin Function用来关联两个数据集,FlatJoin函数返回可以是一个或者多个元素,也可以不返回任何结果。
val result = dataSet1.join(dataSet2).where("id").equalTo(1){ (left,right),collecotr: Collector[(String,Double)] => collector.collect(left.name,right._1+1) collector.collect("prefix_"+ left.name , right._1+2) } 为了能够更好地引导Flink底层去正确地处理数据集,可以在DataSet数据集关联中,通过Size Hint标记数据集的大小,Flink可以根据用户给定的线索调整计算策略,例如可以使用joinWithTiny或joinWithHuge提示第二个数据集的大小。
val dataSet1:DataSet[Person] = env.fromElements(Person(1,"Peter"),Person(2,"Alice")) val dataSet2:DataSet[(Double,Int)] = env.fromElements((12.3,1),(22.3,3)) //提示Flink第二个数据集是小数据集 val result = dataSet1.joinWithTiny(dataSet2).where("id").equalTo(1) //提示Flink第二个数据集是大数据集 val result = dataSet1.joinWithHuge(dataSet2).where("id").equalTo(1) 除了能够使用joinWithTiny或joinWithHuge方法来提示关联数据集的大小之外,Flink还提供了Join算法提示,可以让Flink更加灵活且高效地执行Join操作。
//将第一个数据集广播出去,并转换成HashTable存储,该策略适用于第一个数据集非常小的情况 ds1.join(ds2,JoinHint.BROADCAST_HASH_FIRST).where("id").equalTo(1) //将第二个数据集广播出去,并转换成HashTable存储,该策略适用于第二个数据集非常小的情况 ds1.join(ds2,JoinHint.BROADCAST_HASH_SECOND)。where("id").equalTo(1) //和不设定Hint相同,将优化的工作交给系统处理 ds1.join(ds2,joinHint.OPTIMIZER_CHOOSES).where("id").equalTo(1) //将两个数据集重新分区,并将第一个数据集转换成HashTable存储,该策略适用于第一个数据集比第二个数据集小,但两个数据集相对比较大的情况 ds1.join(ds2,JoinHint.REPARTITION_HASH_FIRST).where("id").equalTo(1) //将两个数据集重新分区,并将第二个数据集转换成HashTable存储,该策略适用于第二个数据集比第一个数据集小,但两个数据集相对都比较大的情况 ds1.join(ds2,JoinHint.REPARTITION_HASH_SECOND).where("id").equalTo(1) //将两个数据重新分区,并将每个分区排序,该策略适用于两个数据集已经排好顺序的情况 ds1.join(ds2,JoinHint.REPARTITION_SORT_MERGE).where("id").equalTo(1)
-
OuterJoin
OuterJoin对两个数据集进行外关联,包含left,right,full outer join三种关联方式,分别对应DataSet API中的leftOuterJoin、rightOuterJoin以及fullOuterJoin方法。
//左外关联两个数据集,按照相同的key进行关联,如果右边数据集中没有数据则会填充空值 dataSet1.leftOuterJoin(dataSet2).where("id").equalTo(1) //右外关联两个数据集,按照相同的key进行关联,如果左边数据集中没有数据则会填充空值 dataSet1.rightOuterJoin(dataSet2).where("id").equalTo(1) 和JoinFunction一样,OuterJoin也可以指定用户自定义的JoinFunction。
dataSet1.leftOuterJoin(dataSet2).where("id").equalTo(1){ (left,right) => if(right == null){(left.id,1)} else {(left.id,right._1)} } 对于大数据集,Flink也在OuterJoin操作中提供相应的关联算法提示,可以针对左右数据集的分布情况选择合适的优化策略,以提升整体作业的处理效率。
//将第二个数据集广播出去,并转换成HashTable存储,该策略适用于第一个数据集非常小的情况 ds1.leftOuterJoin(ds2,JoinHint.BROADCAST_HASH_SECOND).where("id").equalTo(1) //将两个数据集重新分区,并将第二个数据集转换成HashTable存储,该策略适用于第一个数据集比第二个数据集小,但两个数据集都相对比较大的情况 ds1.leftOuterJoin(ds2.JoinHint.REPARTITION_HASH_SECOND).where("id").equalTo(1) 和Join操作不同,OuterJoin的操作只能适用于部分关联算法提示。其中leftOuterJoin仅支持OPTIMIZER_CHOOSES、BROADCAST_HASH_SECOND、REPARTITION_HASH_SECOND以及REPARTITION_SORT_MERGE四种策略。rightOuterJoin仅支持OPTIMIZER_CHOOSES、BROADCAST_HASH_FIRST、REPARTITION_HASH_FIRST以及REPARTITION_SORT_MERGE四种策略。fullOuterJoin仅支持OPTIMIZER_CHOOSES、REPARTITION_SORT_MERGE两种策略。
-
Cogroup
将两个数据集根据相同的Key记录组合在一起,相同Key的记录会存放在一个Group中,如果指定key仅在一个数据集中有记录,则co-group Function会将这个Group与空的Group关联
val dataSet = dataSet1.coGroup(dataSet2).where("id").equalTo(1)
-
cross
将两个数据集合并成一个数据集,返回被连接的两个数据集所有数据行的笛卡尔积,返回的数据行数等于第一个数据集中符合查询条件的数据行数乘以第二个数据集中符合查询条件的数据行数。Cross操作可以通过应用Cross Function将关联的数据集合合并成目标格式的数据集,如果不指定Cross Function则返回Tuple2类型的数据集。
val dataSet1:DataSet[(Int,String)] = env.fromElements((12),"flink"),(22,"spark")) val dataSet2:DataSet[String] = env.fromElements("flink") //不指定Cross Function,则返回Tuple[T,V],其中T为左边数据集数据类型,V为右边数据集 val crossDataSet:DataSet[((Int,String),String)] = dataSet1.cross(dataSet2)
4)集合操作
-
union
合并两个DataSet数据集,两个数据集的数据元素格式必须相同,多个数据集可以连续合并。
val dataSet1:DataSet[(Long,Int)] = ... val dataSet2:DataSet[(Long,Int)] = ... //合并两个数据集 val unioned = dataSet1.union(dataSet2) -
Rebalance
对数据集中的数据进行平均分布,使得每个分区上的数据量相同。
val dataSet:DataSet[String] = env.fromElements("flink","spark") //将DataSet数据集进行重平衡,然后执行map操作 val result = dataSet.rebalance().map{_.toUpperCase} -
Hash-Partition
根据给定的Key进行Hash分区,key相同的数据会被放入同一个分区内。
val dataSet:DataSet[(String,Int)] = ... //根据第一个字段进行数据重分区,然后再执行MapPartition操作处理每个分区的数据 val result = dataSet.partitionByHash(0).mapPartition{...} -
Range-Partition
根据给定的Key进行Range分区,key相同的数据会被放入同一个分区内。
val dataSet:DataSet[(String,Int)] = ... //根据第一个字段进行数据重分区,然后再执行MapPartition操作处理每个分区的数据 val result = dataSet.partitionByRange(0).mapPartition{....} -
Sort Partition
在本地对DataSet数据集中的所有分区根据指定字段进行重排序,排序方式通过Order.ASCENDING以及Order.DESCENDING关键字指定。
val dataSet:DataSet[(String,Int)] = ... //本地对根据第二个字段对分区数据进行逆序排序, val result = dataSet.sortPartition(1,Order.DESCENDING) //根据第一个字段对分区进行升序排序 .sortPartition(0,order.ASCENDING) //然后在排序的分区上执行MapPartition转换操作 .mapPartition{...}
5)排序操作
- First-n
返回数据集的n条随机结果,可以应用于常规类型数据集、Grouped类型数据集以及排序数据集上。
val dataSet:DataSet[(Int,String)] = ...
//普通数据集上返回五条记录
val result1 = dataSet.first(5)
//聚合数据集上返回五条记录
val result2 = dataSet.groupBy(0).first(5)
//Group排序数据集上返回五条记录
val result3 = dataSet.groupBy(0).sortGroup(1,Order.ASCENDING).first(5)
- Minby/Maxby
从数据集中返回指定字段或组合对应最小或最大的记录,如果选择的字段具有多个相同值,则在集合中随机选择一条记录返回。
val dataSet:DataSet[(Int,Double,String)] = ...
//返回数据集中第一个字段和第三个字段最小的记录,并产生新的数据集
val result1:DataSet[(Int,Double,String)] = dataSet.minBy(0,2)
//根据第一个字段对数据集进行聚合,并返回每个Group内第二个字段最小对应的记录
val result2:DataSet[(Int,Double,String)] = dataSet.groupBy(1).minBy(1)
3.DataSinks数据输出
通过对批量数据的读取以及转换之后得到结果数据集,还需要将其写入不同的外部介质进行存储,从而完成整个批处理过程。Flink中对应数据输出功能被称为DataSinks操作,和DataSource Operator操作类似。Flink批量数据输出全部实现于OutputFormat接口,例如文本文件(TextOutputFormat)、CSV文件格式(CSVOutputFormat)。Flink内置了常用数据存储介质对应的OutputFormat,如HadoopOutputFormat、JDBCOutputFormat等。用户也可以自定实现OutputFormat接口,对接其他第三方接口。
Flink在DataSet API中的数据输出共分为三种类型。
第一种是基于文件实现,对应DataSet的write()方法,实现将DataSet数据输出到文件系统中。
第二种是基于通用存储介质实现,对应DataSet的output()方法,例如使用JDBCOutputFormat将数据输出到关系型数据库中。
第三种是客户端输出,直接将DataSet数据从不同的节点收集到Client,并在客户端中输出,例如DataSet的print()方法。
1)基于文件输出接口
在DataSet API中,基于文件的输出接口直接在DataSet中完成封装和定义,例如目前支持的writeAsText直接将DataSet数据输出到指定文件中。在使用write相关方法输出文件的过程中,用户也可以指定写入文件的模式,分为OVERWRITE模式和NOT_OVERWRITE模式,前者代表将对文件内容进行覆盖写入,后者代表输出的数据将追加到文件尾端。
-
writeAsText/TextOutputFormat
将DataSet数据以TextOutputFormat文本格式写入文件系统,其中文件系统可以是本地文件系统,也可以是HDFS文件系统,根据用户指定的路径的前缀进行识别,例如< file >前缀表示本地文件系统,< hdfs >前缀表示HDFS分布式文件系统。TextOutputFormat是FileOutputFormat的子类,而FileOutputFormat则是OutputFormat的实现类。
//DataSet文本格式文件输出实例 val dataSet:DataSet[(String,Int,Double)] = ... //将DataSet数据输出到本地文件系统 dataSet.writeAsText("file:///my/result/on/localFPS") //将DataSet数据输出到HDFS文件系统 dataSet.writeAsText("hdfs://nnHost:nnPort/my/result/on/localFPS") -
writeAsCsv(…)/CSVOutputFormat
该方法将数据集以CSV文件格式输出到指定的文件系统中,并且可以在输出方法中指定行切割符、列切割符等基本CSV文件配置。
val dataSet:DataSet[(String,Int,Double)] = ... //将DataSet数据输出到CSV文件,指定行切割夫为\n,列切割符为, dataSet.writeAsCsv("file://path/file","\n",",")
2)通用输出接口
在DataSet API中,除了已经定义在DataSet中的输出方式,也可以使用自定义OutputFormat方法来定义介质对应的OutputFormat,例如JDBCOutputFormat、HadoopOutputFormat等。
//读取数据集并转换为(word,count)类型数据
val dataSet:DataSet[(String,Long)] = ...
//将数据集的格式转换成[Text,LongWritable]类型
val words = dataSet.map( t => (new Text(t._1),new LongWritable(t._2)) )
//定义HadoopOutputFormat
val hadoopOutputFormat = new HadoopOutputFormat[Text,LongWritable](
new TextOutputFormat[Text,LongWritable],
new JobConf)
//指定输出路径
FileOutputFormat.setOutputPath(hadoopOutputFormat.getJobconf, new Path(resultPath))
//调用Output方法将数据写入Hadoop文件系统
words.output(hadoopOutputFormat)
三.迭代计算
目前Flink中的迭代计算种类有两种模式,分别是Bulk Iteration(全量迭代计算)和Delt Iteration(增量迭代计算)。
1.全量迭代
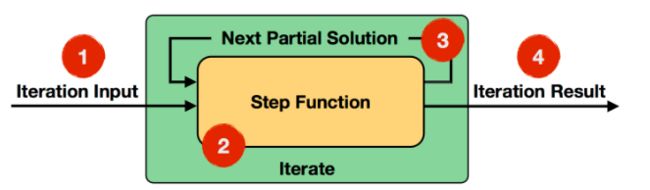
全量迭代如图所示,在数据接入迭代算子过程中,Step Function每次都会处理全量的数据,然后计算下一次迭代的输入(Next Partial Solution),最后根据触发条件输出迭代计算的结果。Flink中迭代的数据和其他计算框架比,并不是通过在迭代计算过程中不断生成新的数据集完成,而是基于同一份数据集上完成迭代计算操作,因此不需要对数据集进行大量拷贝复制操作,避免了性能下降。
全量迭代步骤
- 首先初始化数据,可以通过DataSource算子中获取,也可以通过其他转换Operator中接入。
- 其次定义Step Function,并在每一步迭代过程使用Step Function,结合数据集以及上一次迭代计算的Solution数据集,进行本次迭代计算。
- 每一次迭代过程中Step Function输出的结果,被称为Next Partial Solution数据集,该结果会作为下一次迭代计算的输入数据集。
- 最后一次迭代计算的结果输出,可通过DataSink输出,或接入到下一个Opreators中。迭代终止的条件有两种,分别为达到最大迭代次数或者符合自定义聚合器收敛条件:
- 最大迭代次数:指定迭代的最大次数。
- 自定义收敛条件:用户自定义的聚合器和收敛条件。
全量迭代计算通过DataSet的iterate()方法调用,具体实例如代码所示。
val env = ExecutionEnvironment.getExecutionEnvironment
//创建初始化数据集
val initial = env.fromElements(0)
//调用迭代方法,并设定迭代次数为10000次
val count = initial.iterate(10000){ iterationInput:DataSet[Int] =>
val result = iterationInput.map {i =>
val x = Math.random()
val y = Math.random()
i+(if(x*x + y*y <1 ) 1 else 0)
}
result
}
//输出迭代结果
val result = count.map{ c => c/10000.0 * 4}
result.print()
env.execute("Iterative Pi Example")
2.增量迭代
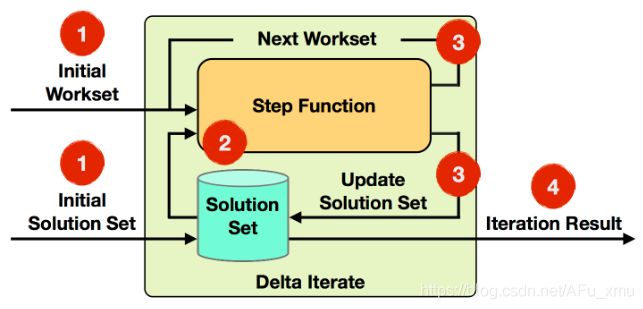
如图所示,增量迭代是通过部分计算取代全量计算,在计算过程中会将数据集分为热点数据和非热点数据集,每次迭代计算会针对热点数据展开,这种模式适合用于数据量比较大的计算场景,不需要对全部的输入数据集进行计算,所以在性能和速度上都会有很大的提升。
增量迭代步骤
- Initial Workset: 初始化数据,可以是DataSource生成,也可以是计算算子生成;
- Step Function: 在每一步迭代过程中使用的计算方法,可以是类似于map、reduce、join等方法;
- Next Workset: 在每一次迭代过程中,当前Step Function输出的结果,该结果会作为下一次迭代计算的输入;
- Iteration Result: 最后一次迭代计算的输出,可以通过指定DataSink输出,或者接入下一个Operators中。
- 增量迭代的终止条件可以指定为:
- Workset为空;
- 最大迭代次数;
//增量迭代计算示例
//读取初始化数据集Workset
val initialSolutionSet:DataSet[(Long,Double)] = ...
//读取初始化Workset数据集
val initialWorkset:DataSet[(Long,Double)] = ...
//设定迭代参数
val maxIterations = 100
val keyPosition = 0
//通过IterateDelta应用增量迭代方法
val result = initialSolutionSet.iterateDelta(initialWorkset, maxIterations, Array(keyPosition)){
(solution , workset) =>
val candidateUpdates = workset.groupBy(1).reduceGroup(new ComputeCandidateChanges())
val deltas = candidateUpdates.join(solution).where(0).equalTo(0)(new CompareChangesTocurrent())
val nextWorkset = deltas.filter(new FilterByThreshold())
(deltas,nextWorkset)
}
//输出迭代结果
result.writeAsCsv(outputPaht)
env.execute()
四.广播变量与分布式缓存
1.广播变量
广播变量是采用网络传输的方式将小数据集存储在每个并行的计算节点的实例内存中。避免节点多次远程调用,提高计算性能。
//将broadcastData数据集广播在data数据集所在的每个实例中
//创建所需要的广播数据集
val broadcastData = env.fromElements(1,2,3)
//广播broadcastData数据集,指定广播变量名称为broadcastSetName(要唯一)
data.map(...).withBroadcastSet(broadcastData,"broadcastSetName")
DataSet API 支持在RichFunction接口中通过RuntimeContext读取到广播变量。首先在RichFunction中实现Open()方法,然后调用getRuntimeContext()方法获取应用的RuntimeContext,接着调用getBroadcastVariable()方法通过广播名称获取广播变量。同时Flink直接通过collect操作将数据集转换为本地Collection。
如下代码所示,在dataSet2的Map转换中通过withBroadcastSet方法指定dataSet1为广播变量,然后通过实现RichMapFunction接口,在open()方法中调用RuntimeContext对象的getBroadcastVariable()方法,将dataSet1数据集获取到本地并转换成Collection。最后在map方法中访问dataSet1的数据,完成后续操作。
//创建需要广播的数据集
val dataSet1:DataSet[Int] = ...
//创建输入数据集
val dataSet2:DataSet[Int] = ...
dataSet2.map(new RichMapFunction[String,String](){
var broadcastSet: Traversable[Int] = null
override def open(config:Configuration):Unit = {
//获取广播变量数据集,并且转换为Collection对象
broadcastSet = getRuntimeContext().getBroadcastVariable[Int]("broadcastSet-1").asScala
}
def map(input:String):String = {
input + broadcastSet.toList //获取broadcastSet元素信息
}
//广播DataSet数据集,指定广播变量名称为broadcastSetName
}).withBroadcastSet(dataSet1,"broadcastSet-1")
2.分布式缓存
Flink不像MapReduce计算向数据靠拢,因此会频繁复制文件,所以需要使用分布式缓存的方式,将高频文件放置在每台计算节点实例的本地task内存中,从而提高任务执行效率。
分布式缓存在ExecutionEinvironment中直接注册文件或文件夹,Flink在启动任务的过程中将会把指定的文件同步到task所在计算节点的本地文件系统中,目前支持本地文集、HDFS、S3等文件系统,另外可以通过Boolean参数来指定文件是否可执行,具体使用方式如下:
val env = ExecutionEnvironment.getExecutionEnvironment
//通过HDFS文件读取并转换成分布式缓存
env.registerCacheFile("hdfs:///path/file","hdfsFile")
//通过本地文件中读取并注册为分布式缓存,并将可执行设定为true
env.registerCacheFile("file:///path/file","localFile",true)
获取缓存文件的方式和广播变量相似,也是实现RichFunciton接口,并通过RichFunction接口获得RuntimeContext对象,然后通过RuntimeContext提供的接口获取对应的本地缓存文件,使用方式如以下代码所示:
//定义RichMapFunction获取分布式缓存文件
class FileMapper extends RichMapFunction[String,Int]{
var myFile:File = null
override def open(config:Configuration): Unit = {
//通过RuntimeContext和DistributedCache获取缓存文件
myFile = getRuntimeContext.getDistributedCache.getFile("hdfsFile")
}
override def map(value:String): Int={
//使用读取到的文件内容
val inputFile = new FileInputStream(myFile)
...//定义数据处理逻辑
}
}
通过RuntimeContext和DistributedCache获取缓存文件,且文件为java.io.File类型,然后将文件定义成静态对象中,就可以直接在map方法中读取文件中的内容,进行后续的算子操作,同时使用完缓存文件后Flink会自动将文件从本地文件系统中清除。
五.语义注解
在Flink批处理过程中,传入的数据可能包含很多字段,有的字段计算会用到,有些字段没有参与到计算过程中。针对这种情况,Flink提出了语义注解的功能:将这些字段在Function中通过注解的形式标记出来,区分出哪些是需要参与函数计算的字段,哪些是直接输出的字段。Flink Runtime在执行算子过程中,会对注解的字段进行判别,对于不需要处理的数据直接转发到Output对象,减少网络IO或者不必要的排序,提高效率。
在DataSet API中将语义注解支持的字段分为三种类型,分别为Forwarded Fields、Non-Forward Fields以及Read Fields,下面详细介绍每种语义注解的使用方式。
1.Forwarded Fields注解
转发字段(Forwaded Fields)代表数据从Function进入后,对指定为Forwaded的Fields不进行修改,且不参与函数的计算逻辑,而是根据设定的规则表达式,将Fields直接推送到Output对象中的相同位置或指定位置上。
转发字段的规则通过表达式进行指定,表达式中可以指定转发字段的源位置和目标位置。例如“f0 -> f2"代表将Input的Tuple对象中的第一个字段转发到Output的Tuple对象中的第三个字段上。单个”f2“,表示转发到相同位置上。”f1->*"表示转发到Output的全部字段上。
多个表达式可以同时使用,表达式中间通过分号分隔,例如“f1->f2;f3->f1;f0"。
转发字段定义方式有两种,首先可以通过在函数类上添加Java注解的方式指定,其次也可以通过在Operator算子对应的Function后调用ForwardedFieldsFirst的方法来指定。
1)函数注解方式
ForwadedFields注解主要用于但输入的Function进行字段转发,例如Map、Reduce等。如下代码所示,定义实现MapFunction接口的MyMap Function Class,完成map方法的定义,最后在MyMap Class上添加ForwadedFields注解。
//通过函数注解方式配置转发字段,将输入数据集中的第一个字段转发到输出数据集中的第二个字段中
@ForwardedFields("_1->_2")
class MyMapper extends MapFunction[(Int,Double),(Double,Int)]{
def map(t:(Int,Double)):(Double,Int) = {
//map函数中也定义为将t._1输出到output对象的t._2字段中
return (t._2 / 2 , t._1)
}
}
对于多输入函数,如Cogroup、Join等函数,可以使用@ForwadedFieldsFirst以及@ForwadedFieldsSecond注解分别对输入的数据集进行转发配置,而且@Forwaded-FieldsFirst 和 @ForwadedFieldsSecond也可以在函数定义的过程中使用。
2)算子参数方式
在单输入Operator算子中,可以调用withForwardedFields完成函数的转发字段的定义。例如data.map(myMapFnc).withForwadedFields(“f0->f2”)。针对多输入算子的转发字段第一,例如CoGroup、Join等算子,可以通过withForwardedFieldsFirst()方法或withForwadedFieldsSecond方法分别对第一个和第二个输入数据集中的字段进行转发,两个方法也可以同时使用。
//创建数据集
val dataSet1:DataSet[Person] = ...
val dataSet2:DataSet[(Double,Int)] = ...
//指定Join函数,并且在算子尾部通过withForwadedFieldsSecond方法指定字段转发逻辑
val result = dataSet1.join(dataSet2).where("id").equalTo(1){
(left,right,collector:Collector[(String,Double,Int)]) =>
collector.collect(left.name,right._1+1,right._2)
collector.collect("prefix_" + left.name, right._1+2,right._2)
}.withForwardedFieldsSecond("_2->_3")//定义转发逻辑
2.Non-Forwarded Fields
与Forwarded Fields相反,Non-Forwarded Fields用于指定不转发字段。
//不转发第二个,其余字段转发到输出对象相同位置上
@NonForwardedFields("_2")
class MyMapper extends MapFunction[(String, Long, Int),(String, Long, Int)]{
def map(input: (String, Long, Int)):(String, Long, Int) = {
//第一个和第三个字段不参与函数计算,第二个字段参与到函数计算过程中,并产生新结果
reurn(input._1,input._2/2,input._3)
}
}
3.Read Fields注解
读取字段(Read Fields)注解用来指定Function中需要读取以及参与函数计算的字段,在注解中被指定的字段将参与当前函数结果的运算过程,如条件判断、数值计算等。
对于但输入类型函数,使用@ReadFields完成注解定义,表达式可以是”f0;f2",表示Input中Tuple的第一个字段和第三个字段参与函数的运算过程。如下代码所示,其中f0和f3参与了函数计算过程,f0参与了条件判断,f3参与了数值运算,指定在@ReadFields("_1; _2")函数注解指明,f1虽然也在函数中引用过,但没有涉及运算,无需指明。
@ReadFields("_1; _2")
class MyMapper extends MapFunction[(Int, Int, Double, Int),(Int, Long)]{
def map(value:(Int, Int, Double, Int)):(Int, Double) = {
if(value._1 == 42){
return (value._1, value._3)
}
else{
return (value._2 +10, value._3)
}
}
}
针对多输入的函数,例如Join、Cogroup等函数,可以使用ReadFieldsFirst和ReadFieldsSecond注解来完成对第一个和第二个输入对象读取字段的定义。