- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- ES聚合分析原理与代码实例讲解
光剑书架上的书
大厂Offer收割机面试题简历程序员读书硅基计算碳基计算认知计算生物计算深度学习神经网络大数据AIGCAGILLMJavaPython架构设计Agent程序员实现财富自由
ES聚合分析原理与代码实例讲解1.背景介绍1.1问题的由来在大规模数据分析场景中,特别是在使用Elasticsearch(ES)进行数据存储和检索时,聚合分析成为了一个至关重要的功能。聚合分析允许用户对数据集进行细分和分组,以便深入探索数据的结构和模式。这在诸如实时监控、日志分析、业务洞察等领域具有广泛的应用。1.2研究现状目前,ES聚合分析已经成为现代大数据平台的核心组件之一。它支持多种类型的聚
- WebMagic:强大的Java爬虫框架解析与实战
Aaron_945
Javajava爬虫开发语言
文章目录引言官网链接WebMagic原理概述基础使用1.添加依赖2.编写PageProcessor高级使用1.自定义Pipeline2.分布式抓取优点结论引言在大数据时代,网络爬虫作为数据收集的重要工具,扮演着不可或缺的角色。Java作为一门广泛使用的编程语言,在爬虫开发领域也有其独特的优势。WebMagic是一个开源的Java爬虫框架,它提供了简单灵活的API,支持多线程、分布式抓取,以及丰富的
- 免费的GPT可在线直接使用(一键收藏)
kkai人工智能
gpt
1、LuminAI(https://kk.zlrxjh.top)LuminAI标志着一款融合了星辰大数据模型与文脉深度模型的先进知识增强型语言处理系统,旨在自然语言处理(NLP)的技术开发领域发光发热。此系统展现了卓越的语义把握与内容生成能力,轻松驾驭多样化的自然语言处理任务。VisionAI在NLP界的应用领域广泛,能够胜任从机器翻译、文本概要撰写、情绪分析到问答等众多任务。通过对大量文本数据的
- 如何利用大数据与AI技术革新相亲交友体验
h17711347205
回归算法安全系统架构交友小程序
在数字化时代,大数据和人工智能(AI)技术正逐渐革新相亲交友体验,为寻找爱情的过程带来前所未有的变革(编辑h17711347205)。通过精准分析和智能匹配,这些技术能够极大地提高相亲交友系统的效率和用户体验。大数据的力量大数据技术能够收集和分析用户的行为模式、偏好和互动数据,为相亲交友系统提供丰富的信息资源。通过分析用户的搜索历史、浏览记录和点击行为,系统能够深入了解用户的兴趣和需求,从而提供更
- 未来软件市场是怎么样的?做开发的生存空间如何?
cesske
软件需求
目录前言一、未来软件市场的发展趋势二、软件开发人员的生存空间前言未来软件市场是怎么样的?做开发的生存空间如何?一、未来软件市场的发展趋势技术趋势:人工智能与机器学习:随着技术的不断成熟,人工智能将在更多领域得到应用,如智能客服、自动驾驶、智能制造等,这将极大地推动软件市场的增长。云计算与大数据:云计算服务将继续普及,大数据技术的应用也将更加广泛。企业将更加依赖云计算和大数据来优化运营、提升效率,并
- Hadoop架构
henan程序媛
hadoop大数据分布式
一、案列分析1.1案例概述现在已经进入了大数据(BigData)时代,数以万计用户的互联网服务时时刻刻都在产生大量的交互,要处理的数据量实在是太大了,以传统的数据库技术等其他手段根本无法应对数据处理的实时性、有效性的需求。HDFS顺应时代出现,在解决大数据存储和计算方面有很多的优势。1.2案列前置知识点1.什么是大数据大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的大量数据集合,
- [转载] NoSQL简介
weixin_30325793
大数据数据库运维
摘自“百度百科”。NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。虽然NoSQL流行语
- Kafka详细解析与应用分析
芊言芊语
kafka分布式
Kafka是一个开源的分布式事件流平台(EventStreamingPlatform),由LinkedIn公司最初采用Scala语言开发,并基于ZooKeeper协调管理。如今,Kafka已经被Apache基金会纳入其项目体系,广泛应用于大数据实时处理领域。Kafka凭借其高吞吐量、持久化、分布式和可靠性的特点,成为构建实时流数据管道和流处理应用程序的重要工具。Kafka架构Kafka的架构主要由
- 分享一个基于python的电子书数据采集与可视化分析 hadoop电子书数据分析与推荐系统 spark大数据毕设项目(源码、调试、LW、开题、PPT)
计算机源码社
Python项目大数据大数据pythonhadoop计算机毕业设计选题计算机毕业设计源码数据分析spark毕设
作者:计算机源码社个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!学习资料、程序开发、技术解答、文档报告如需要源码,可以扫取文章下方二维码联系咨询Java项目微信小程序项目Android项目Python项目PHP项目ASP.NET项目Node.js项目选题推荐项目实战|p
- 疫情,疫情
东山草
2020年,疫情爆发,至今已近三年,反反复复,此起彼伏。不但没被消灭,还自我发展,从德尔塔到奥密克戎,与时俱进的变异着。去年11月,疫情之下,大数据800米范围内,都成为时空伴随者。“你的码儿有没有变颜色”“你绿码还是黄码”成为那段时间的流行语,当然少不了的还有全员核酸。段子手整出来一首歌:我走过你走过的路,这算不算相逢?我吹过你吹过的风,这算不算相拥?800米内我们不曾擦肩而过,你却要我14天相
- 在服务器计算节点中使用 jupyter Lab
ranshan567
程序人生
JupyterLab是一个基于网页的交互式开发环境,用于科学计算、数据分析和机器学.jupyterlab是jupyternotebook的下一代产品,集成了更多功能,使用起来更方便.在进行数据分析及可视化时,个人电脑不能满足大数据的分析需求,就需要用到高性能计算机集群资源,然而计算机集群的计算节点往往没有联网功能,所以在计算机集群中使用jupyterLab需要进行一些配置。具体的步骤如下:
- 大数据真实面试题---SQL
The博宇
大数据面试题——SQL大数据mysqlsql数据库bigdata
视频号数据分析组外包招聘笔试题时间限时45分钟完成。题目根据3张表表结构,写出具体求解的SQL代码(搞笑品类定义:视频分类或者视频创建者分类为“搞笑”)1、表创建语句:createtablet_user_video_action_d(dsint,user_idstring,video_idstring,action_typeint,`timestamp`bigint)rowformatdelimi
- Spark 组件 GraphX、Streaming
叶域
大数据sparkspark大数据分布式
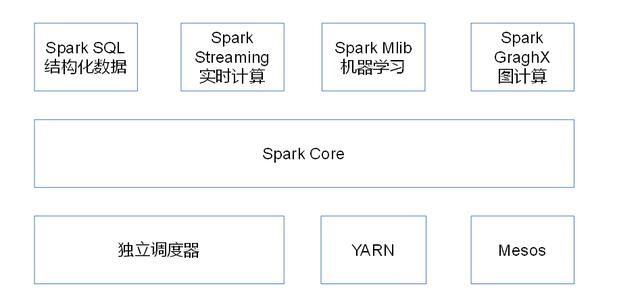
Spark组件GraphX、Streaming一、SparkGraphX1.1GraphX的主要概念1.2GraphX的核心操作1.3示例代码1.4GraphX的应用场景二、SparkStreaming2.1SparkStreaming的主要概念2.2示例代码2.3SparkStreaming的集成2.4SparkStreaming的应用场景SparkGraphX用于处理图和图并行计算。Graph
- Flume:大规模日志收集与数据传输的利器
傲雪凌霜,松柏长青
后端大数据flume大数据
Flume:大规模日志收集与数据传输的利器在大数据时代,随着各类应用的不断增长,产生了海量的日志和数据。这些数据不仅对业务的健康监控至关重要,还可以通过深入分析,帮助企业做出更好的决策。那么,如何高效地收集、传输和存储这些海量数据,成为了一项重要的挑战。今天我们将深入探讨ApacheFlume,它是如何帮助我们应对这些挑战的。一、Flume概述ApacheFlume是一个分布式、可靠、可扩展的日志
- 云服务业界动态简报-20180128
Captain7
一、青云青云QingCloud推出深度学习平台DeepLearningonQingCloud,包含了主流的深度学习框架及数据科学工具包,通过QingCloudAppCenter一键部署交付,可以让算法工程师和数据科学家快速构建深度学习开发环境,将更多的精力放在模型和算法调优。二、腾讯云1.腾讯云正式发布腾讯专有云TCE(TencentCloudEnterprise)矩阵,涵盖企业版、大数据版、AI
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- 架构评审的自动化与人工智能: 如何提高效率
光剑书架上的书
架构自动化人工智能运维
1.背景介绍架构评审是软件开发过程中的一个关键环节,它旨在确保软件架构的质量、可维护性和可扩展性。传统的架构评审通常是由人工进行,需要大量的时间和精力。随着大数据技术和人工智能的发展,自动化和人工智能技术已经开始应用于架构评审,从而提高评审的效率和准确性。在本文中,我们将讨论如何通过自动化和人工智能技术来提高架构评审的效率。我们将从以下几个方面进行讨论:背景介绍核心概念与联系核心算法原理和具体操作
- 【数字化供应链】数字化供应链架构、全景管理、全流程贯通方案
数字化建设方案
数字化转型数据治理主数据数据仓库供应链数字仓储智慧物流智慧仓储物流园区架构微服务数据挖掘大数据人工智能
原文《数字化供应链架构、全景管理、全流程贯通方案》PPT格式。主要从供应链管理全景、智慧供应链建设总体目标、供应链总体业务流程、供应链总体功能架构、供应链总体技术架构、供应链全流程贯通、供应链全领域管理、供应链数据数据分析、供应链决策中台等进行建设。本文仅对主要内容进行介绍。来源网络公开渠道,旨在交流学习,如有侵权联系速删,更多参考公众号:优享智库基于先进IT技术、大数据能力、物联网应用、区块链平
- 80
鑫_259b
科普一个谈恋爱的方法。在以前,谈恋爱千难万难,就难在对对方不知底细,不知道对方希望自己是一个怎样的人,要耗费大量的时间去试探、再磨合,往往会因为一些小事一些细节,满盘皆输。在一个信息化的时代,在一个大数据近乎变成了流行语的时代,我们要跟上时代的步伐,通过大数据,去寻找异性最希望自己展现出来的形象是什么,才可以在爱情的道路上少走弯路。那这个大数据怎么操作呢?上街发问卷?问别人的择偶标准?一来会被打死
- 解锁企业潜能,Vatee万腾平台引领智能新纪元
自媒体经济说
其他
在数字化转型的浪潮中,企业正站在一个前所未有的十字路口,面对着前所未有的机遇与挑战。解锁企业内在潜能,实现跨越式发展,已成为众多企业的共同追求。而Vatee万腾平台,作为智能科技的先锋,正以其强大的智能赋能能力,引领企业步入一个全新的智能纪元。Vatee万腾平台,是一个集成了人工智能、大数据、云计算等前沿技术的综合性智能服务平台。它不仅仅是一个技术工具,更是企业转型升级的加速器,能够深入企业运营的
- 释放“AI+”新质生产力,深算院如何“把大数据变小”?
YashanDB
YashanDB国产数据库数据库数据库大数据
近期,南都·湾财社推出《新质·中国造》栏目,深入千行百业,遍访湾区企业,解锁湾区新质生产力,共探高质量发展之道。本期对话深圳计算科学研究院YashanDB首席技术官陈志标,探讨国产数据库如何实现创新突围,抢抓数字经济时代的新机遇。以下是专访内容:如何应对AI时代所面临的算力挑战?南都·湾财社:数据、算力和算法是发展人工智能的三要素,深算院做了怎样的前瞻性布局?陈志标:今年,政府工作报告中首次提及开
- 数字化智能工厂数字化供应链架构、全景管理、全流程贯通方案
数字化建设方案
智能制造数字工厂制造业数字化转型工业互联网架构
随着信息技术的飞速发展,数字化转型已成为制造企业提升竞争力的关键途径。数字化智能工厂通过集成先进的物联网(IoT)、大数据、云计算、人工智能(AI)等技术,实现了生产过程的智能化、供应链管理的精准化及决策的科学化。本方案旨在构建一套完善的数字化供应链架构,实现全景管理、全流程贯通、智慧化升级,以数据为驱动,强化技术支撑与安全管理体系,推动企业向智能制造迈进。一、数字化供应链架构1.**集成化平台构
- 日记——我的歌单
静若小猴
又到一年一度大数据汇总的时候了,听歌已经成为很多人生活里的一种乐趣。春夏秋冬,我们都有自己喜欢的歌,歌词歌曲唱出沃尔玛你的心声。还记得大学时候最喜欢听的《春天里》,我有一天单曲回放了30遍,总觉得听着仿佛看到自己声音。还有的歌,初听不知曲中意,再听已经是曲终人,听着歌流泪,听着歌入睡……还记得那些年少的故事吗,总觉得自己才是故事外的人,却不是自己已经入歌。一段时间会喜欢一个人的音乐,一段时间会沉静
- Linux dmesg命令:显示开机信息
fafadsj666
linux数据库数据挖掘机器学习大数据
通过学习《Linux启动管理》一章可以知道,在系统启动过程中,内核还会进行一次系统检测(第一次是BIOS进行加测),但是检测的过程不是没有显示在屏幕上,就是会快速的在屏幕上一闪而过那么,如果开机时来不及查看相关信息,我们是否可以在开机后查看呢?答案是肯定的,使用dmesg命令就可以。无论是系统启动过程中,还是系统运行过程中,只要是内核产生的信息,都会被存储在系统缓冲区中,已经为大家精心准备了大数据
- 大数据新视界 --大数据大厂之揭秘大数据时代 Excel 魔法:大厂数据分析师进阶秘籍
青云交
大数据新视界Excel数据分析函数公式数据透视表图表功能规划求解数据分析工具库大数据新视界数据库
亲爱的朋友们,热烈欢迎你们来到青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。本博客的精华专栏:Ja
- 大数据新视界 --大数据大厂之数据挖掘入门:用 R 语言开启数据宝藏的探索之旅
青云交
大数据新视界数据库大数据数据挖掘R语言算法案例未来趋势应用场景学习建议大数据新视界
亲爱的朋友们,热烈欢迎你们来到青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。本博客的精华专栏:Ja
- 高职人工智能训练师边缘计算实训室解决方案
武汉唯众智创
人工智能训练师边缘计算实训室人工智能训练师实训室边缘计算实训室
一、引言随着物联网(IoT)、大数据、人工智能(AI)等技术的飞速发展,计算需求日益复杂和多样化。传统的云计算模式虽在一定程度上满足了这些需求,但在处理海量数据、保障实时性与安全性、提升计算效率等方面仍面临诸多挑战。在此背景下,边缘计算作为一种新兴的计算模式应运而生,通过将计算能力推向数据生成或用户所在的网络边缘,显著降低了数据传输的延迟,提升了处理效率,并增强了数据安全性。针对高等职业院校的人工
- python基于django/flask的NBA球员大数据分析与可视化python+java+node.js
QQ_511008285
pythondjangoflaskjavaspringboot数据分析
前端开发框架:vue.js数据库mysql版本不限后端语言框架支持:1java(SSM/springboot)-idea/eclipse2.Nodejs+Vue.js-vscode3.python(flask/django)--pycharm/vscode4.php(thinkphp/laravel)-hbuilderx数据库工具:Navicat/SQLyog等都可以本文针对NBA球员的大数据进行
- Java基于spring boot的国产电影数据分析与可视化python+java+node.js
QQ_511008285
javaspringboot数据分析pythondjangovue.jsflask
前端开发框架:vue.js数据库mysql版本不限后端语言框架支持:1java(SSM/springboot)-idea/eclipse2.Nodejs+Vue.js-vscode3.python(flask/django)--pycharm/vscode4.php(thinkphp/laravel)-hbuilderx数据库工具:Navicat/SQLyog等都可以 该系统使用进行大数据处理和
- [星球大战]阿纳金的背叛
comsci
本来杰迪圣殿的长老是不同意让阿纳金接受训练的.........
但是由于政治原因,长老会妥协了...这给邪恶的力量带来了机会
所以......现代的地球联邦接受了这个教训...绝对不让某些年轻人进入学院
- 看懂它,你就可以任性的玩耍了!
aijuans
JavaScript
javascript作为前端开发的标配技能,如果不掌握好它的三大特点:1.原型 2.作用域 3. 闭包 ,又怎么可以说你学好了这门语言呢?如果标配的技能都没有撑握好,怎么可以任性的玩耍呢?怎么验证自己学好了以上三个基本点呢,我找到一段不错的代码,稍加改动,如果能够读懂它,那么你就可以任性了。
function jClass(b
- Java常用工具包 Jodd
Kai_Ge
javajodd
Jodd 是一个开源的 Java 工具集, 包含一些实用的工具类和小型框架。简单,却很强大! 写道 Jodd = Tools + IoC + MVC + DB + AOP + TX + JSON + HTML < 1.5 Mb
Jodd 被分成众多模块,按需选择,其中
工具类模块有:
jodd-core &nb
- SpringMvc下载
120153216
springMVC
@RequestMapping(value = WebUrlConstant.DOWNLOAD)
public void download(HttpServletRequest request,HttpServletResponse response,String fileName) {
OutputStream os = null;
InputStream is = null;
- Python 标准异常总结
2002wmj
python
Python标准异常总结
AssertionError 断言语句(assert)失败 AttributeError 尝试访问未知的对象属性 EOFError 用户输入文件末尾标志EOF(Ctrl+d) FloatingPointError 浮点计算错误 GeneratorExit generator.close()方法被调用的时候 ImportError 导入模块失
- SQL函数返回临时表结构的数据用于查询
357029540
SQL Server
这两天在做一个查询的SQL,这个SQL的一个条件是通过游标实现另外两张表查询出一个多条数据,这些数据都是INT类型,然后用IN条件进行查询,并且查询这两张表需要通过外部传入参数才能查询出所需数据,于是想到了用SQL函数返回值,并且也这样做了,由于是返回多条数据,所以把查询出来的INT类型值都拼接为了字符串,这时就遇到问题了,在查询SQL中因为条件是INT值,SQL函数的CAST和CONVERST都
- java 时间格式化 | 比较大小| 时区 个人笔记
7454103
javaeclipsetomcatcMyEclipse
个人总结! 不当之处多多包含!
引用 1.0 如何设置 tomcat 的时区:
位置:(catalina.bat---JAVA_OPTS 下面加上)
set JAVA_OPT
- 时间获取Clander的用法
adminjun
Clander时间
/**
* 得到几天前的时间
* @param d
* @param day
* @return
*/
public static Date getDateBefore(Date d,int day){
Calend
- JVM初探与设置
aijuans
java
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。 JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台
- SQL中ON和WHERE的区别
avords
SQL中ON和WHERE的区别
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。 www.2cto.com 在使用left jion时,on和where条件的区别如下: 1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
- 说说自信
houxinyou
工作生活
自信的来源分为两种,一种是源于实力,一种源于头脑.实力是一个综合的评定,有自身的能力,能利用的资源等.比如我想去月亮上,要身体素质过硬,还要有飞船等等一系列的东西.这些都属于实力的一部分.而头脑不同,只要你头脑够简单就可以了!同样要上月亮上,你想,我一跳,1米,我多跳几下,跳个几年,应该就到了!什么?你说我会往下掉?你笨呀你!找个东西踩一下不就行了吗?
无论工作还
- WEBLOGIC事务超时设置
bijian1013
weblogicjta事务超时
系统中统计数据,由于调用统计过程,执行时间超过了weblogic设置的时间,提示如下错误:
统计数据出错!
原因:The transaction is no longer active - status: 'Rolling Back. [Reason=weblogic.transaction.internal
- 两年已过去,再看该如何快速融入新团队
bingyingao
java互联网融入架构新团队
偶得的空闲,翻到了两年前的帖子
该如何快速融入一个新团队,有所感触,就记下来,为下一个两年后的今天做参考。
时隔两年半之后的今天,再来看当初的这个博客,别有一番滋味。而我已经于今年三月份离开了当初所在的团队,加入另外的一个项目组,2011年的这篇博客之后的时光,我很好的融入了那个团队,而直到现在和同事们关系都特别好。大家在短短一年半的时间离一起经历了一
- 【Spark七十七】Spark分析Nginx和Apache的access.log
bit1129
apache
Spark分析Nginx和Apache的access.log,第一个问题是要对Nginx和Apache的access.log文件进行按行解析,按行解析就的方法是正则表达式:
Nginx的access.log解析正则表达式
val PATTERN = """([^ ]*) ([^ ]*) ([^ ]*) (\\[.*\\]) (\&q
- Erlang patch
bookjovi
erlang
Totally five patchs committed to erlang otp, just small patchs.
IMO, erlang really is a interesting programming language, I really like its concurrency feature.
but the functional programming style
- log4j日志路径中加入日期
bro_feng
javalog4j
要用log4j使用记录日志,日志路径有每日的日期,文件大小5M新增文件。
实现方式
log4j:
<appender name="serviceLog"
class="org.apache.log4j.RollingFileAppender">
<param name="Encoding" v
- 读《研磨设计模式》-代码笔记-桥接模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 个人觉得关于桥接模式的例子,蜡笔和毛笔这个例子是最贴切的:http://www.cnblogs.com/zhenyulu/articles/67016.html
* 笔和颜色是可分离的,蜡笔把两者耦合在一起了:一支蜡笔只有一种
- windows7下SVN和Eclipse插件安装
chenyu19891124
eclipse插件
今天花了一天时间弄SVN和Eclipse插件的安装,今天弄好了。svn插件和Eclipse整合有两种方式,一种是直接下载插件包,二种是通过Eclipse在线更新。由于之前Eclipse版本和svn插件版本有差别,始终是没装上。最后在网上找到了适合的版本。所用的环境系统:windows7JDK:1.7svn插件包版本:1.8.16Eclipse:3.7.2工具下载地址:Eclipse下在地址:htt
- [转帖]工作流引擎设计思路
comsci
设计模式工作应用服务器workflow企业应用
作为国内的同行,我非常希望在流程设计方面和大家交流,刚发现篇好文(那么好的文章,现在才发现,可惜),关于流程设计的一些原理,个人觉得本文站得高,看得远,比俺的文章有深度,转载如下
=================================================================================
自开博以来不断有朋友来探讨工作流引擎该如何
- Linux 查看内存,CPU及硬盘大小的方法
daizj
linuxcpu内存硬盘大小
一、查看CPU信息的命令
[root@R4 ~]# cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
model name : Intel(R) Xeon(R) CPU X5450 @ 3.00GHz
model name :
- linux 踢出在线用户
dongwei_6688
linux
两个步骤:
1.用w命令找到要踢出的用户,比如下面:
[root@localhost ~]# w
18:16:55 up 39 days, 8:27, 3 users, load average: 0.03, 0.03, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
- 放手吧,就像不曾拥有过一样
dcj3sjt126com
内容提要:
静悠悠编著的《放手吧就像不曾拥有过一样》集结“全球华语世界最舒缓心灵”的精华故事,触碰生命最深层次的感动,献给全世界亿万读者。《放手吧就像不曾拥有过一样》的作者衷心地祝愿每一位读者都给自己一个重新出发的理由,将那些令你痛苦的、扛起的、背负的,一并都放下吧!把憔悴的面容换做一种清淡的微笑,把沉重的步伐调节成春天五线谱上的音符,让自己踏着轻快的节奏,在人生的海面上悠然漂荡,享受宁静与
- php二进制安全的含义
dcj3sjt126com
PHP
PHP里,有string的概念。
string里,每个字符的大小为byte(与PHP相比,Java的每个字符为Character,是UTF8字符,C语言的每个字符可以在编译时选择)。
byte里,有ASCII代码的字符,例如ABC,123,abc,也有一些特殊字符,例如回车,退格之类的。
特殊字符很多是不能显示的。或者说,他们的显示方式没有标准,例如编码65到哪儿都是字母A,编码97到哪儿都是字符
- Linux下禁用T440s,X240的一体化触摸板(touchpad)
gashero
linuxThinkPad触摸板
自打1月买了Thinkpad T440s就一直很火大,其中最让人恼火的莫过于触摸板。
Thinkpad的经典就包括用了小红点(TrackPoint)。但是小红点只能定位,还是需要鼠标的左右键的。但是自打T440s等开始启用了一体化触摸板,不再有实体的按键了。问题是要是好用也行。
实际使用中,触摸板一堆问题,比如定位有抖动,以及按键时会有飘逸。这就导致了单击经常就
- graph_dfs
hcx2013
Graph
package edu.xidian.graph;
class MyStack {
private final int SIZE = 20;
private int[] st;
private int top;
public MyStack() {
st = new int[SIZE];
top = -1;
}
public void push(i
- Spring4.1新特性——Spring核心部分及其他
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- 配置HiveServer2的安全策略之自定义用户名密码验证
liyonghui160com
具体从网上看
http://doc.mapr.com/display/MapR/Using+HiveServer2#UsingHiveServer2-ConfiguringCustomAuthentication
LDAP Authentication using OpenLDAP
Setting
- 一位30多的程序员生涯经验总结
pda158
编程工作生活咨询
1.客户在接触到产品之后,才会真正明白自己的需求。
这是我在我的第一份工作上面学来的。只有当我们给客户展示产品的时候,他们才会意识到哪些是必须的。给出一个功能性原型设计远远比一张长长的文字表格要好。 2.只要有充足的时间,所有安全防御系统都将失败。
安全防御现如今是全世界都在关注的大课题、大挑战。我们必须时时刻刻积极完善它,因为黑客只要有一次成功,就可以彻底打败你。 3.
- 分布式web服务架构的演变
自由的奴隶
linuxWeb应用服务器互联网
最开始,由于某些想法,于是在互联网上搭建了一个网站,这个时候甚至有可能主机都是租借的,但由于这篇文章我们只关注架构的演变历程,因此就假设这个时候已经是托管了一台主机,并且有一定的带宽了,这个时候由于网站具备了一定的特色,吸引了部分人访问,逐渐你发现系统的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据库和应用互相影响,应用出问题了,数据库也很容易出现问题,而数据库出问题的时候,应用也容易
- 初探Druid连接池之二——慢SQL日志记录
xingsan_zhang
日志连接池druid慢SQL
由于工作原因,这里先不说连接数据库部分的配置,后面会补上,直接进入慢SQL日志记录。
1.applicationContext.xml中增加如下配置:
<bean abstract="true" id="mysql_database" class="com.alibaba.druid.pool.DruidDataSourc