Spark 官网阅读笔记
1.spark读取本地文件系统: 则该文件也必须可以在工作节点上的相同路径上访问。所以需要将文件复制到所有work 节点或使用网络安装的共享文件系统。
2.group by key 没有reduceBykey, aggregateBykey高效,(后者是同时分区排序)
3.accumulator 累加器的使用
4.broadcast variables 广播变量的使用
5:DataFrame就是DataSet的一行Dataset[Row]
6.用于隐式转换,如将RDD转换为DataFrames . 需要 import spark.implicits._
7.全局临时视图与系统保存的数据库绑定global_temp,我们必须使用前面加上限定名称来引用它,例如SELECT * FROM global_temp.view1。(加关键字global_temp)
8.新建session测试spark.newSession().sql("select * from global_temp.people")
9.通过提供一个样例类可以将DataFrames转换为Dataset。映射将通过名称

10:类型推断
peopleDF.createOrReplaceTempView("people")
val tdf = spark.sql("select name,age from people were age>=13 and age <= 19)
tdf.map(t=> "name: " +t(0)).show()
tdf.map(t=> "name: " +t.getAs[String]("name')).show()

11. persist table: 写出时没有指定路径参数(默认存储为管理表,路径为hive-site.xml,指定的位置),表被删除时,数据,路径都会被删掉。指定参数则不会。
For file-based data source, e.g. text, parquet, json, etc. you can specify a custom table path via the path option, e.g. df.write.option("path", "/some/path").saveAsTable("t"). When the table is dropped, the custom table path will not be removed and the table data is still there. If no custom table path is specified, Spark will write data to a default table path under the warehouse directory. When the table is dropped, the default table path will be removed too.
12. the automatic type inference can be configured ,配置是否启用类型推断,确定分区字段。by spark.sql.sources.partitionColumnTypeInference.enabled, which is default to true. When type inference is disabled, string type will be used for the partitioning columns.
13.设置全局的参数实现类型合并: spark.sql.parquet.mergeSchema
14:读取HIVE:前提需要pom文件中有spark-hive 依赖。
val spark = SparkSession
。builder()
。appName (“Spark Hive示例” )
。config (“spark.sql.warehouse.dir” , warehouseLocation )
。enableHiveSupport ()
。getOrCreate ()
import spark.implicits._
import spark.sql
15:使用广播表:
import org.apache.spark.sql.functions.broadcast
broadcast(spark.table("src")).join(spark.table("records"), "key").show()
16:pyArrow:
要在执行这些调用时使用箭头,用户需要首先将Spark配置'spark.sql.execution.arrow.enabled'设置为'true'。这是默认禁用的。
pyspark 使用自定义python相关。
配置spark-env.sh 内容:添加如下
export PYSPARK_PYTHON= /home/lio/anaconda3/env/DL/bin/python3.5
即可
ipython notebook with spark
http://blog.cloudera.com/blog/2014/08/how-to-use-ipython-notebook-with-apache-spark/
import numpy as np
import pandas as pd
# Enable Arrow-based columnar data transfers
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
# Generate a Pandas DataFrame
pdf = pd.DataFrame(np.random.rand(100, 3))
# Create a Spark DataFrame from a Pandas DataFrame using Arrow
df = spark.createDataFrame(pdf)
# Convert the Spark DataFrame back to a Pandas DataFrame using Arrow
result_pdf = df.select("*").toPandas()

pip install PyArrow

- spark-streaming
17: 要仅停止StreamingContext,请将可选参数stop()调用stopSparkContext为false:
* @param stopSparkContext If true, stops the associated SparkContext. The underlying SparkContext will be stopped regardless of whether this StreamingContext has been started. */
def stop(
stopSparkContext: Boolean = conf.getBoolean("spark.streaming.stopSparkContextByDefault", true)
): Unit = synchronized {
stop(stopSparkContext, false)
}
18:DStream由连续的RDD系列表示,这是Spark对不可变的分布式数据集的抽象.DStream中的每个RDD都包含来自特定时间间隔的数据.
19:不在driver端创建数据库连接, 不使用foreachRDD操作创建连接,最好使用foreachPartition 和connectionPool
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
这是不正确的,因为这要求将连接对象序列化并从Driver端发送到worker端。这种连接对象很难在机器间转移。此错误可能表现为序列化错误(连接对象不可序列化),初始化错误(连接对象需要在worker初始化)等。正确的解决方案是在worker上创建连接对象。
但是,这可能会导致另一个常见错误 - 为每条记录创建一个新的连接。例如,
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
通常,创建连接对象会带来时间和资源开销。因此,创建和销毁每个记录的连接对象可能会导致不必要的高开销,并且可能会显着降低系统的整体吞吐量。更好的解决方案是使用 rdd.foreachPartition- 创建单个连接对象并使用该连接发送RDD分区中的所有记录。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
这会缓解许多记录中的连接创建开销。
最后,通过跨多个RDD /批次重用连接对象,可以进一步优化这一点。可以维护一个静态的连接对象池,因为多个批处理的RDD被推送到外部系统,所以可以重复使用,从而进一步降低了开销。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
请注意,池中的连接应按需延迟创建,如果暂时不使用,则超时。这实现了向外部系统发送数据的最高效率。
其他要记住的要点:
输出操作会延迟执行DStream,就像RDD由RDD操作懒洋洋地执行一样。具体来说,DStream输出操作中的RDD操作会强制处理接收到的数据。因此,如果您的应用程序没有任何输出操作,或者dstream.foreachRDD()没有任何RDD操作的输出操作,则不会执行任何操作。系统只会收到数据并丢弃它。
默认情况下,输出操作一次执行一次。并且它们按照它们在应用程序中定义的顺序执行。
20:
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SparkSession
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate() 从整个在使用的streamingContext的sparkContext中获取构建sparkSession的配置文件。
import spark.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Create a temporary view
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
21:可以异步的使用sql的查询不同进程中的streamingContext实例。请确保streamingContext设置记住足够多的数据,否则,streamingContext没有感知到任何 查询会删除之前的数据。{您还可以在来自不同线程的流式数据上定义的表上运行SQL查询(即与正在运行的StreamingContext异步)。只要确保您将StreamingContext设置为记住足够数量的流数据,以便查询可以运行。否则,不知道任何异步SQL查询的StreamingContext将在查询完成之前删除旧流数据。例如,如果您想查询最后一批,但查询可能需要5分钟才能运行,请调用streamingContext.remember(Minutes(5))(以Scala或其他语言的等效语言)}如果您想查询最后一批,但查询可能需要5分钟才能运行,请调用streamingContext.remember(Minutes(5))
22:容错:
对于通过网络接收数据的输入流(例如Kafka,Flume,套接字等),默认持久性级别设置为将数据复制到两个节点以实现容错。
DStream的默认持久性级别使数据在内存中序列化
23:为了减少数据恢复时的lineage过于长所以需要设立checkpoint切断这个链条。
24:配置checkpoint, 失败自启动。 预写日志:spark.streaming.receiver.writeAheadLog.enable来true
24:设置背压,:设置最大接收速率 - 如果群集资源不够大,流式传输应用程序无法像接收数据一样快速处理数据,则可以通过以记录/秒为单位设置最大速率限制来限制接收器速率。查看接收器的配置参数 spark.streaming.receiver.maxRate和spark.streaming.kafka.maxRatePerPartition Direct Kafka方法。在Spark 1.5中,我们引入了一项名为backpressure的功能,无需设置此速率限制,因为Spark Streaming会自动计算出速率限制并在处理条件发生变化时动态调整速率限制。这个背压可以通过设置来启用配置参数 spark.streaming.backpressure.enabled来true。
25:sturctedStreaming:new data in the data stream === new rows append to a unabounded table.
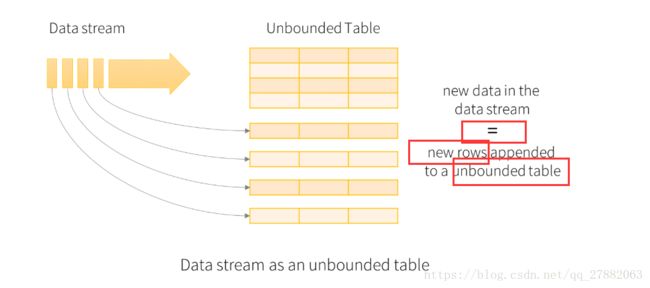
26:写出模式:
完整:整个更新后的结果表将被写入外部存储器。由存储连接器决定如何处理整个表格的写入
追加:只有在结果表中追加的新行才会写入外部存储器。这仅适用于预期不会更改结果表中现有行的查sinks
更新:- 只有自上次触发以来在结果表中更新的行才会写入外部存储器(自Spark 2.1.1起可用)。请注意,这与完整模式不同之处在于,此模式仅输出自上次触发后更改的行。如果查询不包含聚合,则它将模式。
27:容错语义:
提供端到端的一次语义是结构化数据流设计背后的关键目标之一。为此,我们设计了结构化流式源,接收器和执行引擎,以可靠地跟踪处理的确切进程,以便通过重新启动和/或重新处理来处理任何类型的故障。假定每个流源都有偏移量(类似于Kafka偏移量或Kinesis序列号)来跟踪流中的读取位置。该引擎使用checkpoint和WAL来记录每个触发器中正在处理的数据的偏移范围。流式接收器被设计为处理重新处理的幂等。通过使用可重放源和幂等,结构化数据流可以确保端到端完全一次的语义 任何失败
28:类型推断和分区
对于即席查询,您可以通过设置spark.sql.streaming.schemaInference为true启用。
可以/data/year=2016/在/data/year=2015/存在时添加,但更改分区列(即通过创建目录/data/date=2016-04-17/)是无效的。
29:水位线:
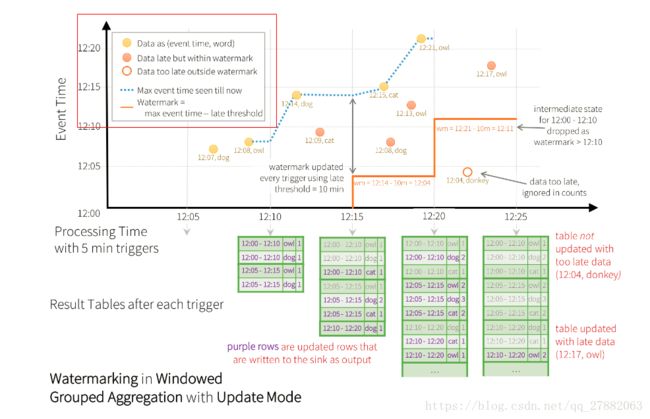
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()
在这个例子中,我们正在定义查询的水印“timestamp”列的值,并且还定义了“10分钟”作为允许数据有多迟的阈值。
30:join操作:
流数据和静态数据集之间的join
val staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "right_join") // right outer join with a static DF
流数据和流数据之间的join:
为了在流-流join的时候可以进行状态清理
水位线限制:事件处理逻辑可延时发生的最大时间
事件时间延迟:事件处理逻辑中的事件限制
import org.apache.spark.sql.functions.expr
val impressions = spark.readStream. ...
val clicks = spark.readStream. ...
// Apply watermarks on event-time columns
val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)
2小时”的水印延迟保证引擎不会丢失延迟少于2小时的任何数据。但延迟超过2小时的数据可能会或可能不会得到处理。
31:虽然水印+事件时间约束对于内连接是可选的,但对于左外连接和右外连接,它们必须指定。这是因为为了在外连接中生成NULL结果,引擎必须知道输入行将来何时不会与任何事物匹配。因此,必须指定水印+事件时间约束以生成正确的结果。因此,具有外连接的查询与前面的广告示例非常相似,不同之处在于会有一个附加参数指定它为外连接。
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter"
)
32:外部结果的生成
关于如何生成外部结果,需要注意几个重要特征。
外部NULL结果将生成延迟,这取决于指定的水印延迟和时间范围条件。这是因为引擎必须等待很长时间才能确保没有匹配,并且将来不会再有匹配。
在当前的微批处理引擎中,水印在微批处理结束时被提前,而下一个微批处理使用更新后的水印来清理状态并输出外部结果。由于我们仅在有新数据要处理时触发微量批处理,因此如果流中没有接收到新数据,则可能会延迟生成外部结果。 简而言之,如果连接的两个输入流中的任何一个在一段时间内都没有收到数据,则外部(两种情况下,左侧或右侧)输出可能会延迟。
支持流式查询中的连接矩阵