手机参数分析和以及对手机价格预测
数据集下载地址: https://www.kaggle.com/vikramb/mobile-price-eda-prediction
1. 提出问题
手机存在许多参数,包括电池容量,是否有蓝牙,微处理器执行命令的速度等等。本次实验意在探讨手机的价格与这些参数的关系,并尝试根据这些手机参数,预测手机的价格范围,并展示出预测的准确度。
2. 准备工作
导入需要用到的库,包括pandas,matplotlib以及机器学习的sklearn等等。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import model_selection
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neural_network import MLPClassifier3. 数据预处理
导入输入数据集,包括训练集和测试集。
df_train = pd.read_csv('C:/Users/28555/Desktop/train.csv')
df_test = pd.read_csv('C:/Users/28555/Desktop/test.csv')//文件存在电脑的位置然后进行数据清洗,将训练集中的价格范围(price_range)这一列分离出去,方便之后的机器学习;同时将测试集中的ID一列剥离。
X = df_train.drop(['price_range'],axis = 1)
y = df_train['price_range']
test = df_test.drop(['id'],axis = 1)4. 可视化分析
由于与手机价格相关的参数较多,一个一个图地输出非常麻烦,因此可直接用热力图,分析出各参数之间的关系。
corr = df_train.corr()
sns.heatmap(data = corr)
plt.xticks(fontsize = 5)
plt.yticks(fontsize = 5)
plt.title('各要素之间的关系')
plt.show()5. 构建模型
构建包括多层感知机,决策树以及逻辑回归的模型,然后用sklearn库里的交叉验证函数对其准确率进行预测。
predictors=['battery_power', 'blue', 'clock_speed', 'dual_sim', 'fc', 'four_g',
'int_memory', 'm_dep', 'mobile_wt', 'n_cores', 'pc', 'px_height',
'px_width', 'ram', 'sc_h', 'sc_w', 'talk_time', 'three_g',
'touch_screen', 'wifi']
LogRegAlg=LogisticRegression(random_state=1)#逻辑回归
re=LogRegAlg.fit(df_train[predictors],df_train['price_range'])
scores=model_selection.cross_val_score(LogRegAlg,df_train[predictors],df_train['price_range'],cv=5)
print("逻辑回归准确率为:")
print(scores.mean())
tree=DecisionTreeClassifier(random_state=1)#决策树
az=tree.fit(df_train[predictors],df_train['price_range'])
scores=model_selection.cross_val_score(tree,df_train[predictors],df_train['price_range'],cv=5)
print("决策树准确率为:")
print(scores.mean())
mlp=MLPClassifier()#多层感知机
ad=mlp.fit(df_train[predictors],df_train['price_range'])
scores=model_selection.cross_val_score(mlp,df_train[predictors],df_train['price_range'],cv=5)
print("多层感知机准确率为:")
print(scores.mean())
df_test['price_range']=az.predict(df_test[predictors])
print(df_test)
6. 模型输出
首先是输出热力图,可以反映出各参数之间的关系。
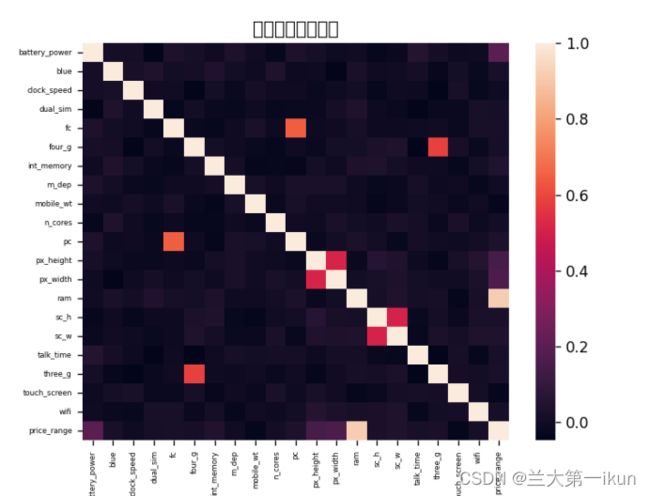
颜色越浅表示相关程度越高,中间的白线为中轴线。需要观察价格区间与其他参数之间的区别。可以看出,与价格区间相关程度较高的是电池容量(battery_power),像素分辨率高低(px_height),像素分辨率宽度(px_width)以及存储器大小(ram)。其中与ram的相关度最高。
然后是对三种模型的准确率进行预测,如图:

可看出,决策树的准确率最高。因此,通过测试集的参数,利用决策树模型进行预测。输出为:

7. 改进
若是改用其他方法,将数据进行归一化处理,再区分出测试模块和训练模块,进行训练与测试,如下图。
std_train = StandardScaler().fit_transform(X)
std_test = StandardScaler().fit_transform(test)
std_Y = y
X_train,X_test,Y_train,Y_test = train_test_split(std_train,std_Y,test_size = 0.2,random_state = 2)#逻辑回归
lr = LogisticRegression().fit(X_train,Y_train)
lr_pred = lr.predict(X_test)
lr_score = accuracy_score(Y_test,lr_pred)
print('改进后的逻辑回归准确率')
print(lr_score)
X_train,X_test,Y_train,Y_test = train_test_split(std_train,std_Y,test_size = 0.2,random_state = 2)#决策树
lr = DecisionTreeClassifier().fit(X_train,Y_train)
lr_pred = lr.predict(X_test)
lr_score = accuracy_score(Y_test,lr_pred)
print('改进后的决策树准确率')
print(lr_score)
X_train,X_test,Y_train,Y_test = train_test_split(std_train,std_Y,test_size = 0.2,random_state = 2)#多层感知机
lr = MLPClassifier().fit(X_train,Y_train)
lr_pred = lr.predict(X_test)
lr_score = accuracy_score(Y_test,lr_pred)
print('改进后的多层感知机准确率')
print(lr_score)其输出为:
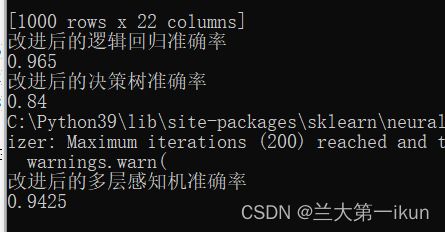
可以看出,逻辑回归和多层感知机的准确率明显提升,而决策树的准确率只是略微提升。
8. 完整代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import model_selection
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neural_network import MLPClassifier
df_train = pd.read_csv('C:/Users/28555/Desktop/train.csv')
df_test = pd.read_csv('C:/Users/28555/Desktop/test.csv')
# 清洗数据
X = df_train.drop(['price_range'],axis = 1)
y = df_train['price_range']
test = df_test.drop(['id'],axis = 1)
corr = df_train.corr()
sns.heatmap(data = corr)
plt.xticks(fontsize = 5)
plt.yticks(fontsize = 5)
plt.title('各要素之间的关系')
plt.show()
predictors=['battery_power', 'blue', 'clock_speed', 'dual_sim', 'fc', 'four_g',
'int_memory', 'm_dep', 'mobile_wt', 'n_cores', 'pc', 'px_height',
'px_width', 'ram', 'sc_h', 'sc_w', 'talk_time', 'three_g',
'touch_screen', 'wifi']
LogRegAlg=LogisticRegression(random_state=1)#逻辑回归
re=LogRegAlg.fit(df_train[predictors],df_train['price_range'])
scores=model_selection.cross_val_score(LogRegAlg,df_train[predictors],df_train['price_range'],cv=5)
print("逻辑回归准确率为:")
print(scores.mean())
tree=DecisionTreeClassifier(random_state=1)#决策树
az=tree.fit(df_train[predictors],df_train['price_range'])
scores=model_selection.cross_val_score(tree,df_train[predictors],df_train['price_range'],cv=5)
print("决策树准确率为:")
print(scores.mean())
mlp=MLPClassifier()#多层感知机
ad=mlp.fit(df_train[predictors],df_train['price_range'])
scores=model_selection.cross_val_score(mlp,df_train[predictors],df_train['price_range'],cv=5)
print("多层感知机准确率为:")
print(scores.mean())
df_test['price_range']=az.predict(df_test[predictors])
print(df_test)
std_train = StandardScaler().fit_transform(X)
std_test = StandardScaler().fit_transform(test)
std_Y = y
X_train,X_test,Y_train,Y_test = train_test_split(std_train,std_Y,test_size = 0.2,random_state = 2)#逻辑回归
lr = LogisticRegression().fit(X_train,Y_train)
lr_pred = lr.predict(X_test)
lr_score = accuracy_score(Y_test,lr_pred)
print('改进后的逻辑回归准确率')
print(lr_score)
X_train,X_test,Y_train,Y_test = train_test_split(std_train,std_Y,test_size = 0.2,random_state = 2)#决策树
lr = DecisionTreeClassifier().fit(X_train,Y_train)
lr_pred = lr.predict(X_test)
lr_score = accuracy_score(Y_test,lr_pred)
print('改进后的决策树准确率')
print(lr_score)
X_train,X_test,Y_train,Y_test = train_test_split(std_train,std_Y,test_size = 0.2,random_state = 2)#多层感知机
lr = MLPClassifier().fit(X_train,Y_train)
lr_pred = lr.predict(X_test)
lr_score = accuracy_score(Y_test,lr_pred)
print('改进后的多层感知机准确率')
print(lr_score)