【知识图谱系列】多关系异质图神经网络CompGCN
作者:CHEONG
公众号:AI机器学习与知识图谱
研究方向:自然语言处理与知识图谱
CompGCN (ICLR 2020)
Composition-based Multi-Relational Graph Convolutional Networks
CompGCN论文汇报ppt可通过关注公众号【AI机器学习与知识图谱】,回复关键词:CompGCN 来获得,供学习者使用!可添加微信号【17865190919】进学习交流群,加好友时备注来自CSDN。原创不易,转载请告知并注明出处!
一、基本概念:
图神经网络: 图神经网络是一种专门用于处理图结构数据的神经网络模型。基于图神经网络的知识图谱学习方法:知识图谱表示学习,信息抽取,实体对齐,链接预测,知识推理。
知识图谱: 知识图谱是以图的形式表现客观世界中的实体及之间关系的知识库,实体可以是真实世界中的物体或抽象的概念,关系则表示了实体间的联系。知识图谱拥有复杂的schema,实体类型和关系种类丰富,同质图模型远不能满足知识图谱的需求。
在现实中的知识图谱会存在复杂的实体和关系类型,传统的GCN算法广泛应用于同质图,而同质图算法远不能满足知识图谱需求,CompGCN便是针对于Multi-relational Graphs提出的异质图表征算法,CompGCN能够同时对node和relation进行表征学习,在节点分类,链接预测和图分类任务上都取得Sota效果。
二、Motivation
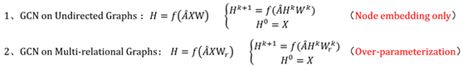
解释一: GNN, GCN等对于建模无向、单关系的图或网络是有效的,如上公式1;
解释二: 现实生活中的知识图谱大多是多关系图,需要对关系进行编码,如上公式2;
解释三: RGCN,如上公式2存在的缺陷,会随着关系的增大,引入过多关系矩阵Wr,参数爆炸模型无法训练。
结合上述描述,CompGCN的研究动机便是为了解决以下两大问题:
1、联合学习一个多关系图中的节点嵌入和关系表示;
2、解决之前多关系图表示工作RGCN等存在的参数过载问题。
三、Method

如上左图是CompGCN为了将图的关系(Relation)加入到表示学习中,将Relation当成Embedding(向量)和Node Embedding联合学习,并且CompGCN丰富了边的类型,即反向关系类型和自循环关系类型,这样可以对多关系图谱进行表征学习并且不会引入过多参数;
如上右图展示了CompGCN在进行表示学习时Aggregation的过程,对应如下公式:
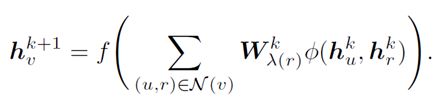
为了充分理解CompGCN Update图和上面Aggregation公式,需要弄清以下三个问题
1、Node Embedding和Relation Embedding表征如何组合?

论文中给出了三种节点和关系表征的组合方式, 分别是Sub,Mult和Corr,也分别对应了TransE,DistMult和ConvE三种方式,在实验效果上看TransE训练速度最快但效果差,ConvE训练速度最慢但效果最佳。
2、三种类型关系如何组合?
CompGCN中做了关系增强,在正向关系类型基础上,增加了反向关系和自循环关系类型
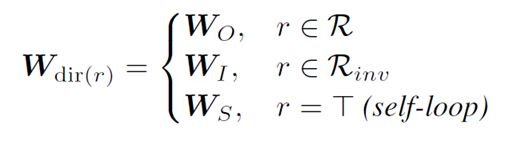
因此就如公式所示,对这三种关系类型分别做Aggregation后需要将三种关系进行西格玛求和,可以看一下论文源码便十分清晰了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JuLWKdqv-1615955780984)(file:///C:/Users/zl_sd/AppData/Local/Temp/msohtmlclip1/01/clip_image011.png)]](http://img.e-com-net.com/image/info8/f96dbde579bb4f5785f41cb01439d5d8.jpg)
3、关系表征如何更新?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5JC1TEZT-1615955780990)(file:///C:/Users/zl_sd/AppData/Local/Temp/msohtmlclip1/01/clip_image013.png)]](http://img.e-com-net.com/image/info8/0827efea4e1946f899d23fc49b94cc01.jpg)
在每一层GCN迭代中,除了对Node Embedding进行Aggregation更新,还需要对Relation Embedding进行更新,如上公示引入Wrel参数进行更新,较为简单。
至此我们对CompGCN提出的Node和Relation联合学习就较为清晰,为了更加深刻理解CompGCN模型的整体框架,让我们看下图:
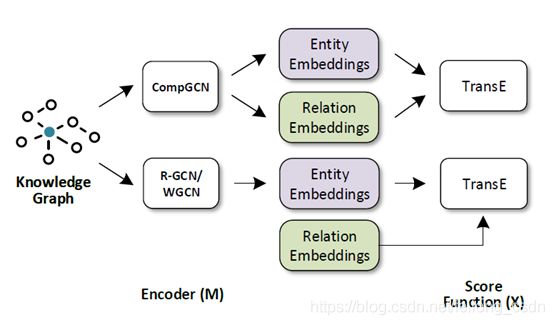
CompGCN模型实现框架采用了R-GCN提出的Encoder-Decoder框架,在Encoder阶段将Entity Embedding和Realtion Embedding进行组合Aggregation,然后在Decoder阶段再采用类似TransE,TransH或者ConvE等方式对(h,r,t)三元组进行解码。因为CompGCN在Encoder阶段就引入了Realtion Embedding,因此从上图可以看出CompGCN的另一大优势便是可以在Encoder和Decoder编码的是同一套Realtion Embedding,使得表征学习更加精准。
四、Conclusion
1、实验数据介绍
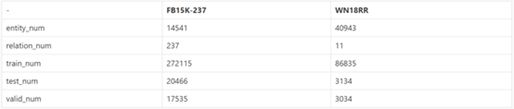
FB15k-237: Freebase中的一部分数据,包含14541个节点、237类边;
WN18RR: WordNet Graph的一部分,包含40943个节点,11类边;FB15k-237\WN18RR相对于FB15k\WN18是将测试集存在训练集的相反关系的一部分数据给去除了,官文有详细说明:
WN18 and FB15k suffer from test leakage through inverse relations: a large number of test triples can be obtained simply by inverting triples in the training set. For example, the test set frequently contains triples such as (s, hyponym, o) while the training set contains its inverse (o, hypernym, s). To create a dataset without this property, FB15k-237 was introduced – a subset of FB15k where inverse relations are removed. And similarly, WN18 was corrected by WN18RR.
2、实验结果
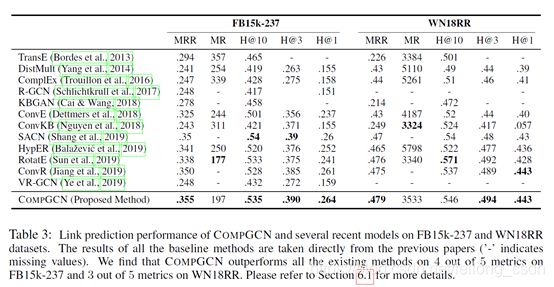
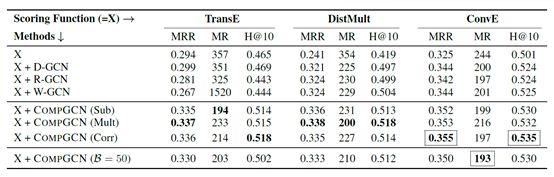
结论: CompGCN在Encoder和Decoder阶段使用同一个编码方式效果会更好,从上表可以看出在Encoder和Decoder阶段同时使用ConvE时,在FB15k-237数据 Link Predictioon任务上取得了最好的效果。