图像处理课程大设计--汽车牌照自动识别
记录一下2020末流2A-未来的广交大的大三下学期MATLAB图像处理的课程设计
为了进行牌照识别,需要以下几个基本的步骤:
a.牌照定位,定位图片中的牌照位置;
b.牌照字符分割,把牌照中的字符分割出来;
c.牌照字符识别,把分割好的字符进行识别,最终组成牌照号码。
1.牌照定位
(1)读入图片
先判断是彩色照片还是灰度图,如果是彩色照片就把读入的图片转化为灰度图。
(2)图像预处理

(3)边缘提取
把图像转为二值图像,利用[3,3]矩形模板对处理后的灰度图进行开运算。
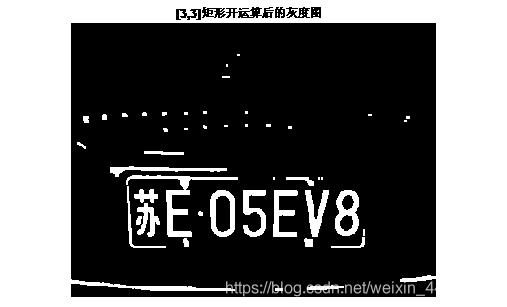
(4)去除干扰
利用imclearborder函数清理、平滑边界,并利用bwareaopen函数先删除连通域较小的干扰,再利用bwareaopen函数删除连通域较大的干扰。

再次对图像进行[3,3]矩形模板的腐蚀

- 车牌定位
车牌白字黑底,白为1,黑为0,故车牌区域的行列逻辑值较高,可以根据这个特性来定位车牌字符区域,这里以30个像素点作为判断阈值,判断阈值要根据图片特性如大小等来确定一个比较合适的阈值,这里处理的车牌区域较大故选取30作为判断阈值。
我们先获取到处理后的图片的行列值,从图片左右两边依次进行每一列的逻辑值叠加,如果从左边开始求的每一列的逻辑叠加值小于=30,则可以认为这一列是黑色背景是可以去除的,直到扫描列的逻辑叠加值大于30就停止扫描,此时记录下是第几列,确定定位车牌的左边界。从右边进行列的扫描同上,此时记录下是第几列,确定定位车牌的右边界。
这样大致确定了车牌的左右边界。
再以同样的思路判断上下行的逻辑值来确定车牌的上下边界。

根据上图可以看出,还是车牌有一些干扰没有去除干净,所以我们再利用bwareaopen
函数去除一些连通域较大的干扰,再进行[3,3]矩形模板的腐蚀。这里不可以先腐蚀再去除连通域较大的干扰,否则会去除掉车牌的字符信息,如下图:

上图就是一个错误的处理先后顺序导致车牌的“苏”字被腐蚀当作干扰去除了。
下面就是一个先腐蚀,后去除干扰的正确顺序处理的车牌图:

处理后的车牌定位依旧不是比较准确,而且还有部分噪声没有去除,故需要第二次车牌边界的定位。

可以看到第二次车牌定位的区域比较准确了。据此,可以进行下一步处理。
2.牌照字符分割
完成牌照区域的定位后,再将牌照区域分割成单个字符,然后进行识别。
车牌的字符是黑底白字,黑为0,白为1。字符分割一般采用垂直投影法,因为黑底背景的投影是没有的即每列的逻辑值的统计求和是0,有字符的地方的投影即每列的逻辑值的统计求和逻辑值是远大于0的,如下图所示:

由上图可以看见,车牌的字符的垂直投影可以清晰地看出是有7个比较明显的不为0的区域,这样我们就可以根据这7个区域来确定每个字符的左右边界来进行分割字符。
根据字符的垂直投影切割字符如下图:

如果到了字符分割的地步,定位的车牌还是有比较多的噪点或者干扰,字符的垂直投影就会有超出7个不为零的区域,如下图:


错误的字符分割:
上图的解决方法就是对每个不为0的区域的长度的进行计算,只有区域的长度大于等于某一个合适的阈值就判断是字符,但如果干扰的区域长度和字符区域的长度大一些即很相近就会失去效果。当然还可以对字符的区域的峰值加以判断,但干扰的区域峰值还是和字符相似一样会失去效果。
3.车牌字符识别
在这里,字符识别采用的是模板匹配算法即把切割好的二值化字符通过插值的方法缩放到字符数据库中模板的大小,一般是40X20像素,然后把所有的二值化得字符模板进行匹配即求和两个字符矩阵的对应值相减后的矩阵的绝对值,即算出两个二值图像的相应位置黑白点的重合率,重合率高的就是最优匹配了。其缺点就是模板库对匹配的影响较大,不同的模板库匹配的准确率不同,例如模板库的字符粗细、倾斜的角度都会影响匹配的准确率。(模板匹配算法错误率是比较大的,跟识别前车牌处理的好不好有很大关系。)
车牌第一个字符是中文字符,故先只匹配字符模板的中文字符,减少匹配错误的几率。
车牌剩下的字符是英文字母和数字,但是采用模板匹配算法容易造成字母和数字的匹配混淆错误,例如数字1和大小的字母I混淆,数字0和字母O、D混淆,字母F和P混淆,字母E和F混淆。
综上原因,在读取字符库匹配字符时的顺序也很重要可以减少匹配错误,例如匹配模板时算出了有两个最优匹配但程序只能匹配一个字母,假如最优匹配是E和F,而且识别众多车牌中F出现的概率比E高得多。我们可以先匹配字母E,在匹配字符F,这样程序存储得就是最后一个最优匹配字符。

以上就是比较简单的车牌识别,毕竟这只是个选修课还是网上授课,我也不是主攻这方面的,也参考了很多大佬的思路想法和代码。