Tensorflow2.0---DeepLab v3+分割网络原理及代码解析(三)- 特征提取网络实现
Tensorflow2.0—DeepLab v3+分割网络原理及代码解析(三)- 特征提取网络实现
一、backbone
DeepLab v3+分割网络默认使用Xception或mobilenetV2作为其的主干网络,用于特征提取。其中mobilenetV2的结构,大佬已经解释的很清楚(https://blog.csdn.net/weixin_44791964/article/details/122655063),这里由于我的电脑还能跑的动大模型,所以我这里我选择的是Xception作为网络的backbone(有时间再写一篇关于backbone的blog吧~)
x, atrous_rates, skip1 = Xception(img_input, alpha, downsample_factor=downsample_factor)
上段代码是将(512,512,3)的输入图片经过Xception主干网络进行特征提取之后生成的fearture map。输出的三个值的shape如下:
- x:(N,32,32,2048)
- atrous_rates:(6,12,18)
- skip1:(N,128,128,256)
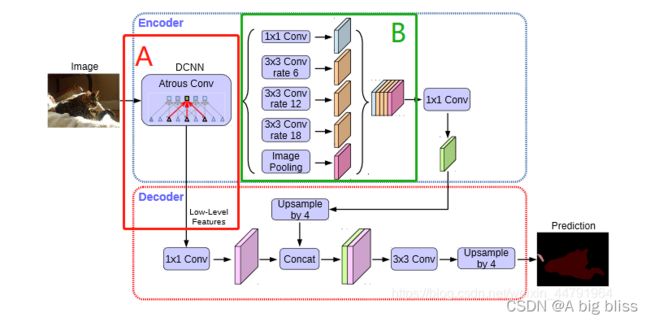
上面A模块就是backbone,他一共有两个特征图输出,上述对应的x(经过下采样2倍的低特征提取)会经过B模块,进行进一步的特征提取,而上述对应的x(经过下采样4倍的高特征提取)会进入decoder模块。
先说x
# 分支0
b0 = Conv2D(256, (1, 1), padding='same', use_bias=False, name='aspp0')(x)
b0 = BatchNormalization(name='aspp0_BN', epsilon=1e-5)(b0)
b0 = Activation('relu', name='aspp0_activation')(b0)
# 分支1 rate = 6 (12)
b1 = SepConv_BN(x, 256, 'aspp1',
rate=atrous_rates[0], depth_activation=True, epsilon=1e-5)
# 分支2 rate = 12 (24)
b2 = SepConv_BN(x, 256, 'aspp2',
rate=atrous_rates[1], depth_activation=True, epsilon=1e-5)
# 分支3 rate = 18 (36)
b3 = SepConv_BN(x, 256, 'aspp3',
rate=atrous_rates[2], depth_activation=True, epsilon=1e-5)
# 分支4 全部求平均后,再利用expand_dims扩充维度,之后利用1x1卷积调整通道
b4 = GlobalAveragePooling2D()(x)
b4 = Lambda(lambda x: K.expand_dims(x, 1))(b4)
b4 = Lambda(lambda x: K.expand_dims(x, 1))(b4)
b4 = Conv2D(256, (1, 1), padding='same', use_bias=False, name='image_pooling')(b4)
b4 = BatchNormalization(name='image_pooling_BN', epsilon=1e-5)(b4)
b4 = Activation('relu')(b4)
# 直接利用resize_images扩充hw
b4 = Lambda(lambda x: tf.compat.v1.image.resize_images(x, size_before[1:3], align_corners=True))(b4)

根据debug之后发现,x经过5个分支之后所得到的fearture map的shape都是(N,32,32,256),然后进行channels维度上面叠加,最后x变成了(N,32,32,1280),根据图中所示,再经过一次(1,1)的卷积,改变一下通道数,得到了(N,32,32,256)。
x = Lambda(lambda xx: tf.compat.v1.image.resize_images(xx, skip_size[1:3], align_corners=True))(x)
最后一步,就是将上述的x进行上采样,得到了(N,128,128,256),待与skip进行concat。
再来看下skip1~
dec_skip1 = Conv2D(48, (1, 1), padding='same',use_bias=False, name='feature_projection0')(skip1)
dec_skip1 = BatchNormalization(name='feature_projection0_BN', epsilon=1e-5)(dec_skip1)
dec_skip1 = Activation(tf.nn.relu)(dec_skip1)
先将skip1的通道数变成48,然后与上述的x(N,128,128,256)进行concat,后接两次卷积得到一个fearture map(N,128,128,256)。
最后一步,就是将x转换为n_class通道数:
size_before3 = tf.keras.backend.int_shape(img_input)
# 512,512,21
x = Conv2D(num_classes, (1, 1), padding='same')(x)
x = Lambda(lambda xx:tf.compat.v1.image.resize_images(xx,size_before3[1:3], align_corners=True))(x)
x = Softmax()(x)
最终最终,我们得到了一个shape大小为(512,512,2)的fearture map,其中2是(1+分割类别数),因为最后一步采用了softmax,所以表达的是每个类别所占的比例大小。