CUDA简介
目录
CUDA Scan(扫描)
computeMode
NVCC
DEVICE/HOST
cuDNN
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。
NVIDIA CUDA深度神经网络库:cuDNN
显存(Global Memory):显存是在GPU板卡上的DRAM。
计算单元(Streaming Multiprocessor):执行计算的。每一个SM都有自己的控制单元(Control Unit)、寄存器(Register)、缓存(Cache)、指令流水线(execution pipelines)。
CUDA线程分成Grid和Block两个层次。
Grid:由一个单独的Kernel启动的所有线程组成一个Grid,Grid中所有线程共享显存。
一个Grid由多个Block组成。
Block:同一个Block中的线程可以同步,也可以通过shared memory通信
一个Block由多个线程组成。
Grid和Block都可以是一维、二维或者三维。
CUDA内置变量:
blockIdx:block的索引。
threadIdx:线程索引。
blockDim:block维度.
gridDim:grid维度。
Warp:A warp is a set of 32 threads within a thread block such that all the threads in a warp execute the same instruction.
CUDA Streaming Multiprocessor的基本执行单元,一个warp包含32个并行线程。每个线程块可以包含多个warp。
.cu/.cuh文件:cu和cuh都是CUDA的后缀格式,cuh相当于CUDA的头文件后缀名。
Cuda矩阵运算库cuBLAS:cuBLAS库用于进行矩阵运算,它包含两套API,一个是常用到的cuBLAS API,需要用户自己分配GPU内存空间,按照规定格式填入数据,;还有一套CUBLASXT API,可以分配数据在CPU端,然后调用函数,它会自动管理内存、执行计算。
并行线程执行(Parallel Thread eXecution,PTX)代码是编译后的GPU代码的一种中间形式,它可以再次编译为原生的GPU微码。
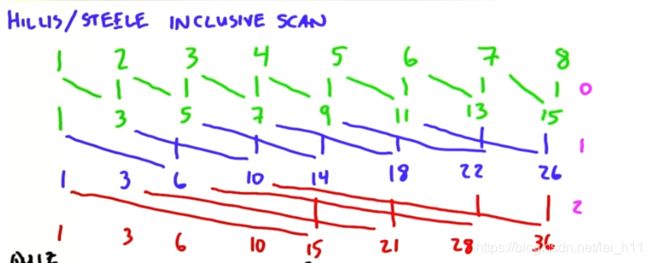
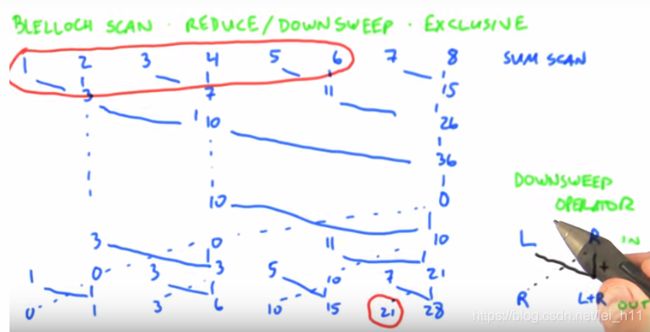
CUDA Scan(扫描)
求数组的前缀和(包括inclusive scan 和exclusive scan两种方式)。
假设输入数组为input,输出数组为output,那么应该有output[i] = output[i-1] + in[i];对于串行算法,时间复杂度为O(n^2),对于并行算法,又分为 Hillis and Steele scan和Blelloch scan
computeMode
computeMode is the compute mode that the device is currently in.
Available modes are as follows:
cudaComputeModeDefault: Default mode - Device is not restricted and multiple threads can use cudaSetDevice() with this device.
cudaComputeModeExclusive: Compute-exclusive mode - Only one thread will be able to use cudaSetDevice() with this device.
cudaComputeModeProhibited: Compute-prohibited mode - No threads can use cudaSetDevice() with this device. Any errors from calling cudaSetDevice() with an exclusive (and occupied) or prohibited device will only show up after a non-device management runtime function is called. At that time, cudaErrorNoDevice will be returned.
NVCC
nvcc是CUDA开发者使用的编译器驱动程序,它可以使CUDA源代码转成一个可执行的CUDA应用程序。
并行线程执行(Parallel Thread eXecution,PTX)代码是编译后的GPU代码的一种中间形式,它可以再次编译为原生的GPU微码。这是英伟达公司为CUDA程序面向未来指令集所建立的一个创新机制,这意味着只要给定的CUDA内核的PTX是可用的,CUDA驱动程序便可将其编译为在GPU上执行的程序的微码(即使在编写代码时GPU对其并不可用)。
-gencode:
arch参数是应用程序所需的最小计算体系结构,也是NVCC的JIT编译器将编译PTX代码的最小设备计算体系结构
code参数是NVCC完全编译应用程序的计算架构,因此不需要JIT编译
DEVICE/HOST
CUDA将memory model unit分为device和host两个系统,充分暴露了其内存结构以供我们操作,给予用户充足的使用灵活性。
cuDNN
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
和CUDA的联系
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。