(综述,讲得很好)基于3DMM的三维人脸重建技术总结
深度学习全监督重建方法:由于真实的三维人脸和二维人脸图像对非常缺乏,采集成本高,很难得到真实二维三维图像对,通常将多张照片进行model fitting求解生成了对应的三维人脸模型,将其作为真值(Ground Truth),从而得到了二维三维图像对,这也导致模型泛化到真实数据集的能力较差。
自监督的方法则是一个解决该问题的重要思路。这一类方法不依赖于真实的成对数据集,它将二维图像重建到三维,再反投影回二维图
2. 什么是3DMM模型 讲的也很好
原文链接:https://blog.csdn.net/hacker_long/article/details/107479264
基于图像的人脸三维重建在人脸分析与娱乐领域里有巨大的应用场景,同时它也可以用于提升人脸关键点检测,人脸识别,人脸编辑等很多任务。本文重点介绍其中基于3DMM模型的核心技术及其研究进展。
作者&编辑 | 言有三
1. 什么是人脸三维重建
人脸三维重建就是建立人脸的三维模型,它相对于二维人脸图像多了一个维度,在电影,游戏等领域应用广泛。目前获取人脸三维模型的方法主要包括三种,软件建模,仪器采集与基于图像的建模。
(1) 软件建模作为最早的三维建模手段,现在仍然是最广泛地在电影,动漫行业中应用。顶顶大名的3DMax就是典型代表,作品如下图。

(2) 由于手工建模耗费大量的人力,三维成像仪器也得到了长期的研究和发展。基于结构光和激光仪器的三维成像仪是其中的典型代表,我们熟知的iphoneX中的人脸识别就是基于结构光进行三维人脸重建,正因如此才有iphonex中的三维人脸表情包。这些基于仪器采集的三维模型,精度可达毫米级,是物体的真实三维数据,也正好用来为基于图像的建模方法提供评价数据库。不过由于仪器的成本太高,一般的用户是用不上了。

(3) 基于图像的建模技术(image based modeling),顾名思义,是指通过若干幅二维图像,来恢复图像或场景的三维结构,这些年得到了广泛的研究。

我们这里说的人脸三维重建,就特指基于图像的人脸三维重建方法。人脸三维重建的研究已经有几十年的历史,但是基于图像的快速高精度三维人脸重建还没有工业落地,需要研究人员继续努力。
2. 什么是3DMM模型
基于人脸图像的三维重建方法非常多,常见的包括立体匹配,Structure From Motion(简称SfM),Shape from Shading(简称sfs),三维可变形人脸模型(3DMM),本文就重点讲述3D Morphable models(简称3DMM),其相关的传统方法和深度学习方法都有较多的研究。

2.1 基本思想
3DMM,即三维可变形人脸模型,是一个通用的三维人脸模型,用固定的点数来表示人脸。它的核心思想就是人脸可以在三维空间中进行一一匹配,并且可以由其他许多幅人脸正交基加权线性相加而来。我们所处的三维空间,每一点(x,y,z),实际上都是由三维空间三个方向的基量,(1,0,0),(0,1,0),(0,0,1)加权相加所得,只是权重分别为x,y,z。
转换到三维空间,道理也一样。每一个三维的人脸,可以由一个数据库中的所有人脸组成的基向量空间中进行表示,而求解任意三维人脸的模型,实际上等价于求解各个基向量的系数的问题。
人脸的基本属性包括形状和纹理,每一张人脸可以表示为形状向量和纹理向量的线性叠加。
形状向量Shape Vector:S=(X1,Y1,Z1,X2,Y2,Z2,...,Yn,Zn),示意图如下:

纹理向量Texture Vector:T=(R1,G1,B1,R2,G2,B2,...,Rn,Bn),示意图如下:

任意的人脸模型可以由数据集中的m个人脸模型进行加权组合如下:

其中Si,Ti就是数据库中的第i张人脸的形状向量和纹理向量。但是我们实际在构建模型的时候不能使用这里的Si,Ti作为基向量,因为它们之间不是正交相关的,所以接下来需要使用PCA进行降维分解。
(1) 首先计算形状和纹理向量的平均值。
(2) 中心化人脸数据。
(3) 分别计算协方差矩阵。
(4) 求得形状和纹理协方差矩阵的特征值α,β和特征向量si,ti。
上式可以转换为下式

其中第一项是形状和纹理的平均值,而si,ti则都是Si,Ti减去各自平均值后的协方差矩阵的特征向量,它们对应的特征值按照大小进行降序排列。
等式右边仍然是m项,但是累加项降了一维,减少了一项。si,ti都是线性无关的,取其前几个分量可以对原始样本做很好的近似,因此可以大大减少需要估计的参数数目,并不失精度。
基于3DMM的方法,都是在求解这几个系数,随后的很多模型会在这个基础上添加表情,光照等系数,但是原理与之类似。
2.2 3DMM模型求解方法
基于3DMM求解三维人脸需要解决的问题就是形状,纹理等系数的估计,具体就是如何将2D人脸拟合到3D模型上,被称为Model Fitting,这是一个病态问题。经典的方法是1999年的文章"A Morphable Model For The Synthesis Of 3D Faces",其传统的求解思路被称为analysis-by-Synthesis,如下;

(a) 初始化一个3维的模型,需要初始化内部参数α,β,以及外部渲染参数,包括相机的位置,图像平面的旋转角度,直射光和环境光的各个分量,图像对比度等共20多维,有了这些参数之后就可以唯一确定一个3D模型到2D图像的投影。
(b) 在初始参数的控制下,经过3D至2D的投影,即可由一个3D模型得到2维图像,然后计算与输入图像的误差。再以误差反向传播调整相关系数,调整3D模型,不断进行迭代。每次参与计算的是一个三角晶格,如果人脸被遮挡,则该部分不参与损失计算。
(c) 具体迭代时采用由粗到精的方式,初始的时候使用低分辨率的图像,只优化第一个主成分的系数,后面再逐步增加主成分。在后续一些迭代步骤中固定外部参数,对人脸的各个部位分别优化。
对于只需要获取人脸形状模型的应用来说,很多方法都会使用2D人脸关键点来估计出形状系数,具有更小的计算量,迭代也更加简单,另外还会增加一个正则项,所以一个典型的优化目标是如下:

对于Model fitting问题来说,除了模型本身的有效性,还有很多难点。
(1) 该问题是一个病态问题,本身并没有全局解,容易陷入不好的局部解。
(2) 人脸的背景干扰以及遮挡会影响精度,而且误差函数本身不连续。
(3) 对初始条件敏感,比如基于关键点进行优化时,如果关键点精度较差,重建的模型精度也会受到很大影响。
2.3 3DMM模型的发展
要使用3DMM模型来完成人脸重建,首先就需要一个数据库来建立人脸基向量空间,Blanz等人在1999年的文章[1]中提出了采集方法,但是没有开源数据集,Pascal Paysan等人在2009年使用激光扫描仪精确采集了200个人脸数据得到了Basel Face Model数据集[2](简称BFM模型),基本信息如下:
(1)采用ABW-3D结构光系统进行采集,采集时间约1s,相比于激光平均15s的采集方案更加具有优势。整个数据集包含200张三维的人脸,其中100张男性,100张女性,大部分为高加索人脸。年龄分布8~62岁,平均年龄24.97岁,体重40~123千克,平均66.48千克。每一个人都被采集3次中性表情,并选择其中最自然的一次。
(2)在对采集后的点进行处理的过程中,模型的每一个点的位置都进行了精确匹配,也就是说每一个点都有实际的物理意义,比如属于右嘴角等。经过处理后,每一个模型由53490个点描述。
该数据库的平均人脸形状和平均人脸纹理如下:

Basel Face Model数据集只有200个人,而近期研究者基于此模型采集了9663个人得到LSFM模型[3],能够进一步提升表达能力。
2009年发布的Basel Face Model版本中没有表情系数,而2017年发布的版本BFM 2017[4]中提供了表情系数,同样还是一个线性模型。

当然了,在国内也有一个著名的数据集,就是FaceWarehouse[5],不过不开源,一般研究者拿不到数据。

当然也有一些商业号称会开源更好的模型,这个大家可以拭目以待。人脸的三维模型数据之所以不公开,是因为使用高精度的三维模型可以很容易仿真真实人脸,容易发生安全事故。
当前基于3DMM的表情模型主要有两个思路,分别是加性模型和乘性模型。加性模型就是线性模型了,将表情作为形状的一个偏移量,Es,Ee分别表示形状和表情基,Ws,We分别表示对应的系数。

但是因为表情也会改变人脸的形状,因此它和形状并非完全正交的关系,所以有的研究者提出了乘性模型,如下。

其中de是一个表情迁移操作集合,第j个操作即为Tj,δ都是校准向量。
另一方面,纹理模型也被称为表观模型,它相对于形状模型来说更加复杂,受到反射率和光照的影响,不过大部分的3DMM模型不区分两者,所以我们将其视为一个因素,即反射率。
光照模型通常采用的是球面模型,光照模型比较复杂,我们这里就不列出具体的表达式,大家可以自行阅读相关论文。
在2009年提出的BFM模型中,纹理模型是一个线性模型,即由多个纹理表情基进行线性组合。后续的研究者们在整个基础上增加了纹理细节,用于仿真脸部的皱纹等。
尽管在大多数情况下,我们使用的都是线性3DMM模型,但是非线性3DMM模型同样也被研究[6],由于不是主流,就不展开讲了。
[1] Blanz V, Vetter T. A morphable model for the synthesis of 3D faces[C]. international conference on computer graphics and interactive techniques, 1999: 187-194.
[2] Booth J, Roussos A, Ponniah A, et al. Large Scale 3D Morphable Models[J]. International Journal of Computer Vision, 2018, 126(2): 233-254.
[3] Paysan P, Knothe R, Amberg B, et al. A 3D Face Model for Pose and Illumination Invariant Face Recognition[C]. advanced video and signal based surveillance, 2009: 296-301.
[4] Gerig T , Morel-Forster A , Blumer C , et al. Morphable Face Models - An Open Framework[J]. 2017.
[5] Cao C, Weng Y, Zhou S, et al. FaceWarehouse: A 3D Facial Expression Database for Visual Computing[J]. IEEE Transactions on Visualization and Computer Graphics, 2014, 20(3): 413-425.
[6] Tran L, Liu X. Nonlinear 3D Face Morphable Model[C]. computer vision and pattern recognition, 2018: 7346-7355.
3. 深度学习3DMM重建
传统的3DMM及其求解核心思路我们上面已经讲述了,接下来要重点说的是基于深度学习的3DMM重建及其研究进展。
3.1 全监督方法
前面给大家介绍了3DMM模型,传统的方法需要去优化求解相关系数,基于深度学习的方法可以使用模型直接回归相关系数,以Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network中提出的3DMM CNN[7]方法为代表。

3DMM CNN是一个非常简单的回归模型,它使用了ResNet101网络直接回归出3DMM的形状系数和纹理系数,形状系数和纹理系数各有99维,除此之外还有几个核心问题。
(1) 首先是数据集的获取。由于真实的三维人脸和二维人脸图像对非常缺乏,采集成本高,作者们用CASIA WebFace数据集中的多张照片进行model fitting求解生成了对应的三维人脸模型,将其作为真值(Ground Truth),从而得到了二维三维图像对。
(2) 然后是优化目标的设计。因为重建的结果是一个三维模型,所以损失函数是在三维的空间中计算,如果使用标准的欧拉损失函数来最小化距离,会使得到的人脸模型太泛化,趋于平均脸。对此作者们提出了一个非对称欧拉损失,使模型学习到更多的细节特征,使三维人脸模型具有更多的区别性,公式如下:

γ是标签,γp是预测值,通过两个权重λ1和λ2对损失进行控制,作者设定λ2权重更大,所以是期望γp能够更大一些,从而提供更多的细节。
除了预测形状系数外,3DMM的研究者们还提出了ExpNet[8]预测表情系数,FacePoseNet[9]预测姿态系数,验证了基于数据和CNN模型学习出相关系数的可行性。
真实数据集的获取是比较困难的,而且成本高昂,导致数据集较小,所以基于真实数据集训练出来的模型鲁棒性有待提升。很多的方法使用了仿真的数据集,可以产生更多的数据进行学习,但是仿真的数据集毕竟与真实的数据集分布有差异,以及头发等部位缺失,导致模型泛化到真实数据集的能力较差。
3.2 自监督方法
三维人脸重建中真实的数据集获取成本非常高,研究者往往基于少量数据或者仿真数据进行研究,所训练出来的模型泛化能力会受到限制,自监督的方法则是一个解决该问题的重要思路。这一类方法不依赖于真实的成对数据集,它将二维图像重建到三维,再反投影回二维图,这一类方法以MoFa[10]为代表,整个流程如下图所示:
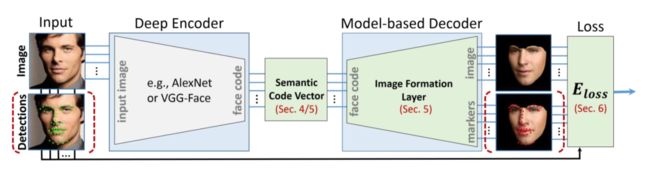
在上图中,输入首先经过一个Deep Encoder提取到语义相关的系数,系数包含了人脸姿态,形状,表情,皮肤,场景光照等信息。然后将该系数输入基于模型的decoder,实现三维模型到二维图像的投影,模型可以使用3DMM模型。最后的损失是基于重建的图像和输入图像的像素损失。当然,还可以添加关键点损失,系数正则化损失作为约束。
3.3 人脸的三维特征编码
通常的3DMM模型预测3DMM的系数,这没有充分发挥出CNN模型对于像素的回归能力,如果我们基于3DMM模型将三维人脸进行更好的特征编码,预期可以获得更好的结果。
这里我们介绍一下两个典型代表[11][12],其一是3DDFA,它使用Projected Normalized Coordinate Code(简称PNCC)作为预测特征。

一个三维点包括X,Y,Z和R,G,B值,将其归一化到0~1之后便称之为Normalized Coordinate Code。如果使用3DMM模型将图像往X-Y平面进行投影,并使用Z-Buffer算法进行渲染,NCC作为Z-buffer算法的color-map,便可以得到PNCC图。
论文《Face Alignment Across Large Poses: A 3D Solution》基于此提出了3DDFA框架,输入为100×100的RGB图和PNCC(Projected Normalized Coordinate Code)特征图,两者进行通道拼接。算法的输出为更新后的PNCC系数,包括6维姿态,199维形状和29维表情系数。
整个网络如下:包含4个卷积层,3个pooling层和2个全连接层,前两个卷积层局部共享,后两个卷积层不采用局部共享机制。这是一个级连迭代的框架,输入为第k次更新的PNCC特征,更新它的误差,损失使用L1距离。

由于不同维度的系数有不同的重要性,作者对损失函数做了精心的设计,通过引入权重,让网络优先拟合重要的形状参数,包括尺度、旋转和平移。当人脸形状接近真值时,再拟合其他形状参数,实验证明这样的设计可以提升定位模型的精度。

由于参数化形状模型会限制人脸形状变形的能力,作者在使用3DDFA拟合之后,抽取HOG特征作为输入,使用线性回归来进一步提升2D特征点的定位精度。
其二是PRNet[12],论文Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network中提出了PRNet(Position map Regression Network),它利用UV位置图(UV position map)来描述3D形状。

在BFM模型中,3D顶点数为53490个,作者选择了一个大小为256×256×3的图片来进行编码,其中像素数目等于256×256=65536,大于且接近53490。这个图被称为UV位置图(UV position map),它有三个通道,分别是X,Y,Z,记录了三维位置信息。值得注意的是,每个3D的顶点映射到这张UV位置映射图上都是没有重叠的。
有了上面的表示方法,就可以用CNN网络直接预测UV位置图,采用一个编解码结构即可。

另外,作者们为了更好的预测坐标,或者说为了使预测出来的结果更有意义,计算损失函数时对不同区域的顶点误差进行加权。不同区域包括特征点,鼻子眼睛嘴巴区域,人脸其他部分,脖子共四个区域。它们的权重比例为16:4:3:0,可见特征点最重要,脖子不参与计算。

[7] Tran A T, Hassner T, Masi I, et al. Regressing robust and discriminative 3D morphable models with a very deep neural network[C]//Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017: 1493-1502.
[8] Chang F J, Tran A T, Hassner T, et al. ExpNet: Landmark-free, deep, 3D facial expressions[C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). IEEE, 2018: 122-129.
[9] Chang F J, Tuan Tran A, Hassner T, et al. Faceposenet: Making a case for landmark-free face alignment[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1599-1608.
[10] Tewari A, Zollhöfer M, Kim H, et al. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction[C]//The IEEE International Conference on Computer Vision (ICCV). 2017, 2(3): 5.
[11] Zhu X, Lei Z, Liu X, et al. Face alignment across large poses: A 3d solution[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 146-155.
[12] Feng Y, Wu F, Shao X, et al. Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network[J]. arXiv preprint arXiv:1803.07835, 2018.
4. 难点和展望
从1999年被提出,至今3DMM模型已经有超过20年的历史,技术已经发展到从早期基于传统的优化方法到如今基于深度学习模型的系数回归,不过当前的3DMM模型还面临着许多的挑战。
(1) 当前的模型基本上都受限于人脸,没有眼睛,嘴唇以及头发信息,然而这些信息对于很多的应用却非常有效。
(2) 3DMM模型参数空间是一个比较低维的参数空间,并且纹理模型过于简单。基于3DMM模型的方法面临的最大问题就是结果过于平均,难以重建人脸皱纹等细节特征,并且无法恢复遮挡。对此有的方法通过增加局部模型[13]进行了改进,而最新的生成对抗网络技术[14]也开始被用于纹理建模。

(3) 遮挡脸的信息恢复。二维的人脸信息一旦被遮挡,也难以被精确地重建,除了利用人脸的对称先验信息进行补全外,有的方法借鉴了检索匹配[15]的思路,即建立一个无遮挡的数据集,将重建的模型进行姿态匹配和人脸识别相似度匹配,然后经过2D对齐,使用基于梯度的方法来进行纹理迁移,也有的方法使用GAN来进行遮挡信息恢复[16]。

(3) 当前3DMM模型中主要使用PCA来提取主成分信息,但是这不符合我们通常对人脸的描述,因此这并非是一个最合适的特征空间。
(4) 当前存在着各种各样的3DMM模型的变种,但是没有一个模型能够在各种场景下取得最优的效果。
另一方面,3DMM模型也与许多新的技术开始结合,比如与生成对抗网络模型一起进行人脸的数据增强[17],姿态编辑[17],人脸的特征恢复[18],对于提升人脸识别模型在具有挑战性的大姿态以及遮挡场景下的性能中具有非常重要的意义。


[13] Richardson E, Sela M, Or-El R, et al. Learning detailed face reconstruction from a single image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1259-1268.
[14] Sela M, Richardson E, Kimmel R, et al. Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation[C]. international conference on computer vision, 2017: 1585-1594.
[15] Tran A T, Hassner T, Masi I, et al. Extreme 3D Face Reconstruction: Seeing Through Occlusions[C]//CVPR. 2018: 3935-3944.
[15] Egger B, Smith W A, Tewari A, et al. 3D Morphable Face Models - Past, Present and Future[J]. arXiv: Computer Vision and Pattern Recognition, 2019.
[16] Zhao J, Xiong L, Jayashree P K, et al. Dual-Agent GANs for Photorealistic and Identity Preserving Profile Face Synthesis[C]. neural information processing systems, 2017: 66-76.
[17] Yin X, Yu X, Sohn K, et al. Towards Large-Pose Face Frontalization in the Wild[C]. international conference on computer vision, 2017: 4010-4019.
[18] Yuan X, Park I. Face De-Occlusion Using 3D Morphable Model and Generative Adversarial Network[C]. international conference on computer vision, 2019: 10062-10071.
5. 如何学习以上算法
在上面我们介绍了基于3DMM模型的核心技术,实际上3DMM模型如今还有许多新的进展,后续深入学习可以参考有三AI秋季划的人脸算法组,可分别学习相关内容。
详情可以阅读下文介绍:
【通知】如何让你的2020年秋招CV项目经历更加硬核,可深入学习有三秋季划4大领域32个方向

人脸相关的算法,在有三AI知识星球的人脸板块中,有诸多介绍,有需要的同学可以加入。


总结
本次我们给大家介绍了基于3DMM模型的三维人脸重建相关核心技术,人脸图像属于最早被研究的一类图像,也是计算机视觉领域中应用最广泛的一类图像,其中需要使用到几乎所有计算机视觉领域的算法,可以说掌握好人脸领域的各种算法,基本就玩转了计算机视觉领域。
如何学习人脸图像算法

如果你想系统性地学习各类人脸算法并完成相关实战,并需要一个可以长期交流学习,永久有效的平台,可以考虑参加有三AI秋季划-人脸图像算法组,完整的介绍和总体的学习路线如下:
【总结】有三AI秋季划人脸算法组3月直播讲了哪些内容,计算机视觉你不可能绕开人脸图像

转载文章请后台联系
侵权必究


往期精选
【技术综述】人脸妆造迁移核心技术总结
【技术综述】人脸风格化核心技术与数据集总结
【总结】最全1.5万字长文解读7大方向人脸数据集v2.0版,搞计算机视觉怎能不懂人脸
【杂谈】计算机视觉在人脸图像领域的十几个大的应用方向,你懂了几分?
【杂谈】GAN对人脸图像算法产生了哪些影响?
【每周CV论文推荐】 深度学习人脸检测入门必读文章
【每周CV论文推荐】 初学深度学习人脸关键点检测必读文章
【每周CV论文推荐】 初学深度学习人脸识别和验证必读文章
【每周CV论文推荐】 初学深度学习人脸属性分析必读的文章
【每周CV论文推荐】 初学活体检测与伪造人脸检测必读的文章
【每周CV论文推荐】 初学深度学习单张图像三维人脸重建需要读的文章
【每周CV论文推荐】 人脸识别剩下的难题:从遮挡,年龄,姿态,妆造到亲属关系,人脸攻击
【每周CV论文推荐】换脸算法都有哪些经典的思路?
基于图像的人脸三维重建在人脸分析与娱乐领域里有巨大的应用场景,同时它也可以用于提升人脸关键点检测,人脸识别,人脸编辑等很多任务。本文重点介绍其中基于3DMM模型的核心技术及其研究进展。
作者&编辑 | 言有三
1. 什么是人脸三维重建
人脸三维重建就是建立人脸的三维模型,它相对于二维人脸图像多了一个维度,在电影,游戏等领域应用广泛。目前获取人脸三维模型的方法主要包括三种,软件建模,仪器采集与基于图像的建模。
(1) 软件建模作为最早的三维建模手段,现在仍然是最广泛地在电影,动漫行业中应用。顶顶大名的3DMax就是典型代表,作品如下图。
(2) 由于手工建模耗费大量的人力,三维成像仪器也得到了长期的研究和发展。基于结构光和激光仪器的三维成像仪是其中的典型代表,我们熟知的iphoneX中的人脸识别就是基于结构光进行三维人脸重建,正因如此才有iphonex中的三维人脸表情包。这些基于仪器采集的三维模型,精度可达毫米级,是物体的真实三维数据,也正好用来为基于图像的建模方法提供评价数据库。不过由于仪器的成本太高,一般的用户是用不上了。
(3) 基于图像的建模技术(image based modeling),顾名思义,是指通过若干幅二维图像,来恢复图像或场景的三维结构,这些年得到了广泛的研究。
我们这里说的人脸三维重建,就特指基于图像的人脸三维重建方法。人脸三维重建的研究已经有几十年的历史,但是基于图像的快速高精度三维人脸重建还没有工业落地,需要研究人员继续努力。
2. 什么是3DMM模型
基于人脸图像的三维重建方法非常多,常见的包括立体匹配,Structure From Motion(简称SfM),Shape from Shading(简称sfs),三维可变形人脸模型(3DMM),本文就重点讲述3D Morphable models(简称3DMM),其相关的传统方法和深度学习方法都有较多的研究。
2.1 基本思想
3DMM,即三维可变形人脸模型,是一个通用的三维人脸模型,用固定的点数来表示人脸。它的核心思想就是人脸可以在三维空间中进行一一匹配,并且可以由其他许多幅人脸正交基加权线性相加而来。我们所处的三维空间,每一点(x,y,z),实际上都是由三维空间三个方向的基量,(1,0,0),(0,1,0),(0,0,1)加权相加所得,只是权重分别为x,y,z。
转换到三维空间,道理也一样。每一个三维的人脸,可以由一个数据库中的所有人脸组成的基向量空间中进行表示,而求解任意三维人脸的模型,实际上等价于求解各个基向量的系数的问题。
人脸的基本属性包括形状和纹理,每一张人脸可以表示为形状向量和纹理向量的线性叠加。
形状向量Shape Vector:S=(X1,Y1,Z1,X2,Y2,Z2,...,Yn,Zn),示意图如下:
纹理向量Texture Vector:T=(R1,G1,B1,R2,G2,B2,...,Rn,Bn),示意图如下:
任意的人脸模型可以由数据集中的m个人脸模型进行加权组合如下:
其中Si,Ti就是数据库中的第i张人脸的形状向量和纹理向量。但是我们实际在构建模型的时候不能使用这里的Si,Ti作为基向量,因为它们之间不是正交相关的,所以接下来需要使用PCA进行降维分解。
(1) 首先计算形状和纹理向量的平均值。
(2) 中心化人脸数据。
(3) 分别计算协方差矩阵。
(4) 求得形状和纹理协方差矩阵的特征值α,β和特征向量si,ti。
上式可以转换为下式
其中第一项是形状和纹理的平均值,而si,ti则都是Si,Ti减去各自平均值后的协方差矩阵的特征向量,它们对应的特征值按照大小进行降序排列。
等式右边仍然是m项,但是累加项降了一维,减少了一项。si,ti都是线性无关的,取其前几个分量可以对原始样本做很好的近似,因此可以大大减少需要估计的参数数目,并不失精度。
基于3DMM的方法,都是在求解这几个系数,随后的很多模型会在这个基础上添加表情,光照等系数,但是原理与之类似。
2.2 3DMM模型求解方法
基于3DMM求解三维人脸需要解决的问题就是形状,纹理等系数的估计,具体就是如何将2D人脸拟合到3D模型上,被称为Model Fitting,这是一个病态问题。经典的方法是1999年的文章"A Morphable Model For The Synthesis Of 3D Faces",其传统的求解思路被称为analysis-by-Synthesis,如下;
(a) 初始化一个3维的模型,需要初始化内部参数α,β,以及外部渲染参数,包括相机的位置,图像平面的旋转角度,直射光和环境光的各个分量,图像对比度等共20多维,有了这些参数之后就可以唯一确定一个3D模型到2D图像的投影。
(b) 在初始参数的控制下,经过3D至2D的投影,即可由一个3D模型得到2维图像,然后计算与输入图像的误差。再以误差反向传播调整相关系数,调整3D模型,不断进行迭代。每次参与计算的是一个三角晶格,如果人脸被遮挡,则该部分不参与损失计算。
(c) 具体迭代时采用由粗到精的方式,初始的时候使用低分辨率的图像,只优化第一个主成分的系数,后面再逐步增加主成分。在后续一些迭代步骤中固定外部参数,对人脸的各个部位分别优化。
对于只需要获取人脸形状模型的应用来说,很多方法都会使用2D人脸关键点来估计出形状系数,具有更小的计算量,迭代也更加简单,另外还会增加一个正则项,所以一个典型的优化目标是如下:
对于Model fitting问题来说,除了模型本身的有效性,还有很多难点。
(1) 该问题是一个病态问题,本身并没有全局解,容易陷入不好的局部解。
(2) 人脸的背景干扰以及遮挡会影响精度,而且误差函数本身不连续。
(3) 对初始条件敏感,比如基于关键点进行优化时,如果关键点精度较差,重建的模型精度也会受到很大影响。
2.3 3DMM模型的发展
要使用3DMM模型来完成人脸重建,首先就需要一个数据库来建立人脸基向量空间,Blanz等人在1999年的文章[1]中提出了采集方法,但是没有开源数据集,Pascal Paysan等人在2009年使用激光扫描仪精确采集了200个人脸数据得到了Basel Face Model数据集[2](简称BFM模型),基本信息如下:
(1)采用ABW-3D结构光系统进行采集,采集时间约1s,相比于激光平均15s的采集方案更加具有优势。整个数据集包含200张三维的人脸,其中100张男性,100张女性,大部分为高加索人脸。年龄分布8~62岁,平均年龄24.97岁,体重40~123千克,平均66.48千克。每一个人都被采集3次中性表情,并选择其中最自然的一次。
(2)在对采集后的点进行处理的过程中,模型的每一个点的位置都进行了精确匹配,也就是说每一个点都有实际的物理意义,比如属于右嘴角等。经过处理后,每一个模型由53490个点描述。
该数据库的平均人脸形状和平均人脸纹理如下:
Basel Face Model数据集只有200个人,而近期研究者基于此模型采集了9663个人得到LSFM模型[3],能够进一步提升表达能力。
2009年发布的Basel Face Model版本中没有表情系数,而2017年发布的版本BFM 2017[4]中提供了表情系数,同样还是一个线性模型。
当然了,在国内也有一个著名的数据集,就是FaceWarehouse[5],不过不开源,一般研究者拿不到数据。
当然也有一些商业号称会开源更好的模型,这个大家可以拭目以待。人脸的三维模型数据之所以不公开,是因为使用高精度的三维模型可以很容易仿真真实人脸,容易发生安全事故。
当前基于3DMM的表情模型主要有两个思路,分别是加性模型和乘性模型。加性模型就是线性模型了,将表情作为形状的一个偏移量,Es,Ee分别表示形状和表情基,Ws,We分别表示对应的系数。
但是因为表情也会改变人脸的形状,因此它和形状并非完全正交的关系,所以有的研究者提出了乘性模型,如下。
其中de是一个表情迁移操作集合,第j个操作即为Tj,δ都是校准向量。
另一方面,纹理模型也被称为表观模型,它相对于形状模型来说更加复杂,受到反射率和光照的影响,不过大部分的3DMM模型不区分两者,所以我们将其视为一个因素,即反射率。
光照模型通常采用的是球面模型,光照模型比较复杂,我们这里就不列出具体的表达式,大家可以自行阅读相关论文。
在2009年提出的BFM模型中,纹理模型是一个线性模型,即由多个纹理表情基进行线性组合。后续的研究者们在整个基础上增加了纹理细节,用于仿真脸部的皱纹等。
尽管在大多数情况下,我们使用的都是线性3DMM模型,但是非线性3DMM模型同样也被研究[6],由于不是主流,就不展开讲了。
[1] Blanz V, Vetter T. A morphable model for the synthesis of 3D faces[C]. international conference on computer graphics and interactive techniques, 1999: 187-194.
[2] Booth J, Roussos A, Ponniah A, et al. Large Scale 3D Morphable Models[J]. International Journal of Computer Vision, 2018, 126(2): 233-254.
[3] Paysan P, Knothe R, Amberg B, et al. A 3D Face Model for Pose and Illumination Invariant Face Recognition[C]. advanced video and signal based surveillance, 2009: 296-301.
[4] Gerig T , Morel-Forster A , Blumer C , et al. Morphable Face Models - An Open Framework[J]. 2017.
[5] Cao C, Weng Y, Zhou S, et al. FaceWarehouse: A 3D Facial Expression Database for Visual Computing[J]. IEEE Transactions on Visualization and Computer Graphics, 2014, 20(3): 413-425.
[6] Tran L, Liu X. Nonlinear 3D Face Morphable Model[C]. computer vision and pattern recognition, 2018: 7346-7355.
3. 深度学习3DMM重建
传统的3DMM及其求解核心思路我们上面已经讲述了,接下来要重点说的是基于深度学习的3DMM重建及其研究进展。
3.1 全监督方法
前面给大家介绍了3DMM模型,传统的方法需要去优化求解相关系数,基于深度学习的方法可以使用模型直接回归相关系数,以Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network中提出的3DMM CNN[7]方法为代表。
3DMM CNN是一个非常简单的回归模型,它使用了ResNet101网络直接回归出3DMM的形状系数和纹理系数,形状系数和纹理系数各有99维,除此之外还有几个核心问题。
(1) 首先是数据集的获取。由于真实的三维人脸和二维人脸图像对非常缺乏,采集成本高,作者们用CASIA WebFace数据集中的多张照片进行model fitting求解生成了对应的三维人脸模型,将其作为真值(Ground Truth),从而得到了二维三维图像对。
(2) 然后是优化目标的设计。因为重建的结果是一个三维模型,所以损失函数是在三维的空间中计算,如果使用标准的欧拉损失函数来最小化距离,会使得到的人脸模型太泛化,趋于平均脸。对此作者们提出了一个非对称欧拉损失,使模型学习到更多的细节特征,使三维人脸模型具有更多的区别性,公式如下:
γ是标签,γp是预测值,通过两个权重λ1和λ2对损失进行控制,作者设定λ2权重更大,所以是期望γp能够更大一些,从而提供更多的细节。
除了预测形状系数外,3DMM的研究者们还提出了ExpNet[8]预测表情系数,FacePoseNet[9]预测姿态系数,验证了基于数据和CNN模型学习出相关系数的可行性。
真实数据集的获取是比较困难的,而且成本高昂,导致数据集较小,所以基于真实数据集训练出来的模型鲁棒性有待提升。很多的方法使用了仿真的数据集,可以产生更多的数据进行学习,但是仿真的数据集毕竟与真实的数据集分布有差异,以及头发等部位缺失,导致模型泛化到真实数据集的能力较差。
3.2 自监督方法
三维人脸重建中真实的数据集获取成本非常高,研究者往往基于少量数据或者仿真数据进行研究,所训练出来的模型泛化能力会受到限制,自监督的方法则是一个解决该问题的重要思路。这一类方法不依赖于真实的成对数据集,它将二维图像重建到三维,再反投影回二维图,这一类方法以MoFa[10]为代表,整个流程如下图所示:
在上图中,输入首先经过一个Deep Encoder提取到语义相关的系数,系数包含了人脸姿态,形状,表情,皮肤,场景光照等信息。然后将该系数输入基于模型的decoder,实现三维模型到二维图像的投影,模型可以使用3DMM模型。最后的损失是基于重建的图像和输入图像的像素损失。当然,还可以添加关键点损失,系数正则化损失作为约束。
3.3 人脸的三维特征编码
通常的3DMM模型预测3DMM的系数,这没有充分发挥出CNN模型对于像素的回归能力,如果我们基于3DMM模型将三维人脸进行更好的特征编码,预期可以获得更好的结果。
这里我们介绍一下两个典型代表[11][12],其一是3DDFA,它使用Projected Normalized Coordinate Code(简称PNCC)作为预测特征。
一个三维点包括X,Y,Z和R,G,B值,将其归一化到0~1之后便称之为Normalized Coordinate Code。如果使用3DMM模型将图像往X-Y平面进行投影,并使用Z-Buffer算法进行渲染,NCC作为Z-buffer算法的color-map,便可以得到PNCC图。
论文《Face Alignment Across Large Poses: A 3D Solution》基于此提出了3DDFA框架,输入为100×100的RGB图和PNCC(Projected Normalized Coordinate Code)特征图,两者进行通道拼接。算法的输出为更新后的PNCC系数,包括6维姿态,199维形状和29维表情系数。
整个网络如下:包含4个卷积层,3个pooling层和2个全连接层,前两个卷积层局部共享,后两个卷积层不采用局部共享机制。这是一个级连迭代的框架,输入为第k次更新的PNCC特征,更新它的误差,损失使用L1距离。
由于不同维度的系数有不同的重要性,作者对损失函数做了精心的设计,通过引入权重,让网络优先拟合重要的形状参数,包括尺度、旋转和平移。当人脸形状接近真值时,再拟合其他形状参数,实验证明这样的设计可以提升定位模型的精度。
由于参数化形状模型会限制人脸形状变形的能力,作者在使用3DDFA拟合之后,抽取HOG特征作为输入,使用线性回归来进一步提升2D特征点的定位精度。
其二是PRNet[12],论文Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network中提出了PRNet(Position map Regression Network),它利用UV位置图(UV position map)来描述3D形状。
在BFM模型中,3D顶点数为53490个,作者选择了一个大小为256×256×3的图片来进行编码,其中像素数目等于256×256=65536,大于且接近53490。这个图被称为UV位置图(UV position map),它有三个通道,分别是X,Y,Z,记录了三维位置信息。值得注意的是,每个3D的顶点映射到这张UV位置映射图上都是没有重叠的。
有了上面的表示方法,就可以用CNN网络直接预测UV位置图,采用一个编解码结构即可。
另外,作者们为了更好的预测坐标,或者说为了使预测出来的结果更有意义,计算损失函数时对不同区域的顶点误差进行加权。不同区域包括特征点,鼻子眼睛嘴巴区域,人脸其他部分,脖子共四个区域。它们的权重比例为16:4:3:0,可见特征点最重要,脖子不参与计算。
[7] Tran A T, Hassner T, Masi I, et al. Regressing robust and discriminative 3D morphable models with a very deep neural network[C]//Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017: 1493-1502.
[8] Chang F J, Tran A T, Hassner T, et al. ExpNet: Landmark-free, deep, 3D facial expressions[C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). IEEE, 2018: 122-129.
[9] Chang F J, Tuan Tran A, Hassner T, et al. Faceposenet: Making a case for landmark-free face alignment[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1599-1608.
[10] Tewari A, Zollhöfer M, Kim H, et al. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction[C]//The IEEE International Conference on Computer Vision (ICCV). 2017, 2(3): 5.
[11] Zhu X, Lei Z, Liu X, et al. Face alignment across large poses: A 3d solution[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 146-155.
[12] Feng Y, Wu F, Shao X, et al. Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network[J]. arXiv preprint arXiv:1803.07835, 2018.
4. 难点和展望
从1999年被提出,至今3DMM模型已经有超过20年的历史,技术已经发展到从早期基于传统的优化方法到如今基于深度学习模型的系数回归,不过当前的3DMM模型还面临着许多的挑战。
(1) 当前的模型基本上都受限于人脸,没有眼睛,嘴唇以及头发信息,然而这些信息对于很多的应用却非常有效。
(2) 3DMM模型参数空间是一个比较低维的参数空间,并且纹理模型过于简单。基于3DMM模型的方法面临的最大问题就是结果过于平均,难以重建人脸皱纹等细节特征,并且无法恢复遮挡。对此有的方法通过增加局部模型[13]进行了改进,而最新的生成对抗网络技术[14]也开始被用于纹理建模。
(3) 遮挡脸的信息恢复。二维的人脸信息一旦被遮挡,也难以被精确地重建,除了利用人脸的对称先验信息进行补全外,有的方法借鉴了检索匹配[15]的思路,即建立一个无遮挡的数据集,将重建的模型进行姿态匹配和人脸识别相似度匹配,然后经过2D对齐,使用基于梯度的方法来进行纹理迁移,也有的方法使用GAN来进行遮挡信息恢复[16]。
(3) 当前3DMM模型中主要使用PCA来提取主成分信息,但是这不符合我们通常对人脸的描述,因此这并非是一个最合适的特征空间。
(4) 当前存在着各种各样的3DMM模型的变种,但是没有一个模型能够在各种场景下取得最优的效果。
另一方面,3DMM模型也与许多新的技术开始结合,比如与生成对抗网络模型一起进行人脸的数据增强[17],姿态编辑[17],人脸的特征恢复[18],对于提升人脸识别模型在具有挑战性的大姿态以及遮挡场景下的性能中具有非常重要的意义。
[13] Richardson E, Sela M, Or-El R, et al. Learning detailed face reconstruction from a single image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1259-1268.
[14] Sela M, Richardson E, Kimmel R, et al. Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation[C]. international conference on computer vision, 2017: 1585-1594.
[15] Tran A T, Hassner T, Masi I, et al. Extreme 3D Face Reconstruction: Seeing Through Occlusions[C]//CVPR. 2018: 3935-3944.
[15] Egger B, Smith W A, Tewari A, et al. 3D Morphable Face Models - Past, Present and Future[J]. arXiv: Computer Vision and Pattern Recognition, 2019.
[16] Zhao J, Xiong L, Jayashree P K, et al. Dual-Agent GANs for Photorealistic and Identity Preserving Profile Face Synthesis[C]. neural information processing systems, 2017: 66-76.
[17] Yin X, Yu X, Sohn K, et al. Towards Large-Pose Face Frontalization in the Wild[C]. international conference on computer vision, 2017: 4010-4019.
[18] Yuan X, Park I. Face De-Occlusion Using 3D Morphable Model and Generative Adversarial Network[C]. international conference on computer vision, 2019: 10062-10071.
5. 如何学习以上算法
在上面我们介绍了基于3DMM模型的核心技术,实际上3DMM模型如今还有许多新的进展,后续深入学习可以参考有三AI秋季划的人脸算法组,可分别学习相关内容。
详情可以阅读下文介绍:
【通知】如何让你的2020年秋招CV项目经历更加硬核,可深入学习有三秋季划4大领域32个方向
人脸相关的算法,在有三AI知识星球的人脸板块中,有诸多介绍,有需要的同学可以加入。
总结
本次我们给大家介绍了基于3DMM模型的三维人脸重建相关核心技术,人脸图像属于最早被研究的一类图像,也是计算机视觉领域中应用最广泛的一类图像,其中需要使用到几乎所有计算机视觉领域的算法,可以说掌握好人脸领域的各种算法,基本就玩转了计算机视觉领域。
如何学习人脸图像算法
如果你想系统性地学习各类人脸算法并完成相关实战,并需要一个可以长期交流学习,永久有效的平台,可以考虑参加有三AI秋季划-人脸图像算法组,完整的介绍和总体的学习路线如下:
【总结】有三AI秋季划人脸算法组3月直播讲了哪些内容,计算机视觉你不可能绕开人脸图像
转载文章请后台联系
侵权必究
往期精选
【技术综述】人脸妆造迁移核心技术总结
【技术综述】人脸风格化核心技术与数据集总结
【总结】最全1.5万字长文解读7大方向人脸数据集v2.0版,搞计算机视觉怎能不懂人脸
【杂谈】计算机视觉在人脸图像领域的十几个大的应用方向,你懂了几分?
【杂谈】GAN对人脸图像算法产生了哪些影响?
【每周CV论文推荐】 深度学习人脸检测入门必读文章
【每周CV论文推荐】 初学深度学习人脸关键点检测必读文章
【每周CV论文推荐】 初学深度学习人脸识别和验证必读文章
【每周CV论文推荐】 初学深度学习人脸属性分析必读的文章
【每周CV论文推荐】 初学活体检测与伪造人脸检测必读的文章
【每周CV论文推荐】 初学深度学习单张图像三维人脸重建需要读的文章
【每周CV论文推荐】 人脸识别剩下的难题:从遮挡,年龄,姿态,妆造到亲属关系,人脸攻击
【每周CV论文推荐】换脸算法都有哪些经典的思路?