基于卷积神经网络的点云配准方法--舒程珣
[1]舒程珣, 何云涛, 孙庆科. 基于卷积神经网络的点云配准方法[J]. 激光与光电子学进展, 2017, 54(3):9.
本文主要就是通过两幅点云图,来估计配准参数(也即位姿变换参数),大概流程如下:
拥有两幅点云—>计算点云的深度图,得到两幅深度图–>通过卷积神经网络估计配准参数(CNN中包括提取特征的卷积部分和回归配准参数的全连接部分。
1、引言
点云配准时通过空间变换使得两片点云再同一坐标系中对齐的过程。
传统点云配准算法一般分为粗配准和精准配准。粗配准用于缩小点云之间的旋转和错位误差,为精准配准提供良好的初始值;精准配准使得两片基本对齐的点云经行更加精准的配准,使得配准误差达到最小。
精准配准的一种经典算法式迭代最近点算法(ICP),简单易行,但是算法效率不高。
本文提出一种基于CNN的点云配准方法:首先计算点云的深度图像,利用CNN提取深度图像对的特征差,将深度差送入FC层计算得到最终的点云配准参数,并且迭代上述过程直到配准误差小于阈值。
本文方法的优点是能够完成点云配准的任务,具有计算量小、配准效率高、对噪声和异常点不敏感。
2、点云配准模型
给定两片点云 P 1 P_1 P1和 P 2 P_2 P2,计算其深度图像 X 1 X_1 X1和 X 2 X_2 X2,将深度图像作为输入。模型的输出是6个参数:3个平移参数 t x 、 t y 、 t x t_x、t_y、t_x tx、ty、tx和3个旋转参数 t α 、 t β 、 t θ t_α、t_β、t_θ tα、tβ、tθ。
全连接层实际上就是一个回归模型,本文将特征差作为回归模型的输入,可以有效迅速输出配准参数why?。
2.1、深度图像计算
给定点云 P P P,点 ( x , y ) (x,y) (x,y)的深度为D,则在深度图中点 ( x , y ) (x,y) (x,y)的值c为:
c = [ 255 − 255 ∗ 2 ∗ N F + N − D ∗ ( F − N ) ] ∗ 4 c=[255-255*\frac {2*N}{F+N-D*(F-N)}]*4 c=[255−255∗F+N−D∗(F−N)2∗N]∗4
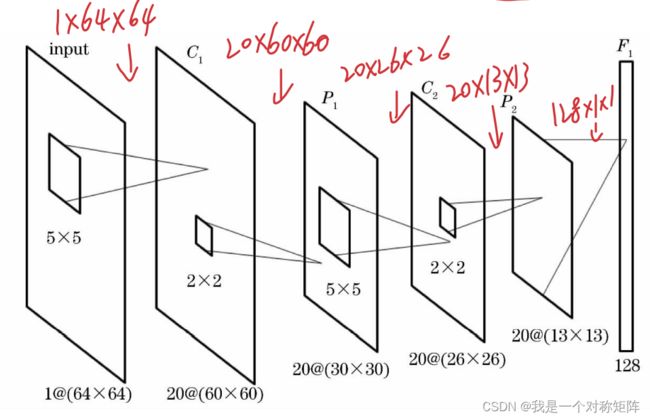
F 和 N F和N F和N被设置为合适的值,让深度图像中深度对比充分,便于计算。通过这一步使得3D点云投影到2D数据,便于CNN的处理
2.2、网路结构
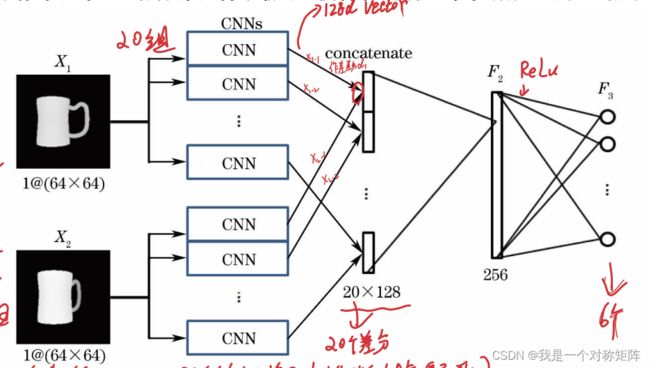
首先,网络是双输入结构,输出是6个参数。
每个输入都会经历20个并行CNN的计算,会提取到20组特征。这样 X 1 和 X 2 X_1和X_2 X1和X2都会提取到20组特征。
然后计算差分向量:即 X 1 X_1 X1提取的第一个CNN特征和 X 2 X_2 X2提取的第一个CNN特征做差,得到第一个差分向量。因为CNN的输出是128d向量,所以两个特征做差结果也是128d向量。
每个图像经过CNN得到20组特征(1*128),故差分向量最后也有20个,将其拼接起来,得到一个长度为20*128的向量。
然后通过一个回归模型(全连接层) F 2 F_2 F2得到256d向量,再经过 F 3 F_3 F3最终得到6个配准参数。
从差异推断配准参数,从图像来是无法描述差异的,将图像分解成20个特征,通过不同图像在20个特征上的差异,来回归得到配准参数。优点类似人脸识别,将人脸图像分解成192个特征,然后从不同人脸在192个特征上的差异来推断是否为相同人脸。
单个CNN的结构如下:
2.3、损失函数

定义很简单,但是没看懂公式想要表达啥,个人感觉加个括号似乎就合理了:
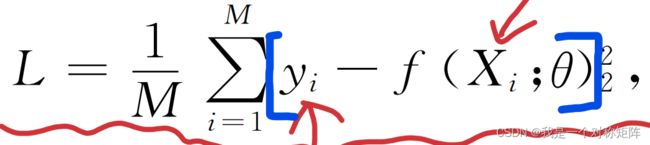
3、总结
论文中给出的效果看起来不错,当然他还涉及到迭代配准,通过多次迭代配准达到一个很不错的效果。
给我最大的收获应该就是特征差分向量,将图像分解为多个特征来数字化地表示,人很难去数字化描述一幅图像,但是通过CNN提取特征地能力,是可以完成这一任务的。