第三门课:结构化机器学习项目(第二周)——机器学习策略(2)
机器学习策略[2]
- 1. 进行误差分析
- 2. 清除标注错误的数据
- 3. 快速搭建你的第一个系统,并进行迭代
- 4. 使用来自不同分布的数据,进行训练和测试
- 5. 数据分布不匹配时,偏差与方差的分析
- 6. 定位数据不匹配问题
- 7. 迁移学习 Transfer learning
- 8. 多任务学习 Multi-task learning
- 9. 什么是端到端的深度学习
- 10. 是否要使用端到端的深度学习其优点
1. 进行误差分析
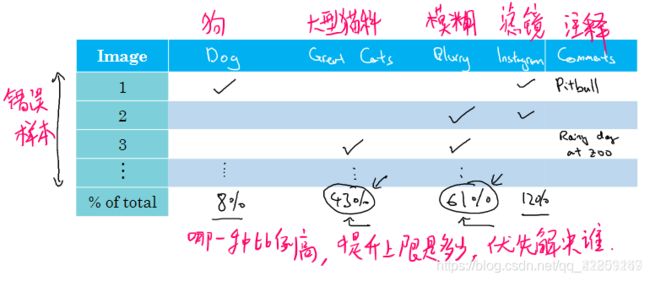
举例:图片猫分类器,算法将一些狗分类为猫
- 收集 n 个预测错误的开发集样本,手动检查
(错误分类的图片里面有多少比例是狗,假如错误率10%,其中狗占5%,那么你完全解决了狗的问题,能降低错误率到 9.5%,结合你花费的时间,评估下值不值当;如果错误分类中,狗占50%,那么解决狗的问题,就能降低错误率到 5%,还是很值得一试的) - 通常做法,统计各种误差的比例,检查哪种误差占比较高,优先解决
2. 清除标注错误的数据

你发现训练数据里有标签标错了,怎么办?
深度学习算法对于训练集中的随机错误是相当健壮的(robust),所以可以不用管
你有时间,修正下也没问题。

如果你要更正标签,请注意:
- 同时在 开发集和测试集 上操作(同一分布)
- 检查了判断错误的样本,也需要考虑到判断正确的样本(可能是标签就错了,恰好预测的一致),但通常此步不会做,太耗时了(比如98%的判对了,检查98%的数据?太多了)
- 只修正 开发集 / 测试集 的标签,而不修正 训练集 的标签是合理的,训练集 通常比前2者大得多,算法是相当健壮的
老师建议:
- 需要人工分析错误
- 亲自去查看错误样本,统计数量,找到优先处理的任务
3. 快速搭建你的第一个系统,并进行迭代
几乎所有的机器学习程序可能会有50个不同的方向可以前进,并且每个方向都是相对合理的,可以改善你的系统?如何集中精力
老师建议:
快速设立 开发集和测试集,还有指标(定目标,定错了,也可以改)
搭好系统原型,训练一下,看看效果,在 开发集 / 测试集上,评估指标表现如何
用之前说的偏差方差分析,错误分析,确定下一步优先做什么(哪些工作最有希望提升)
4. 使用来自不同分布的数据,进行训练和测试
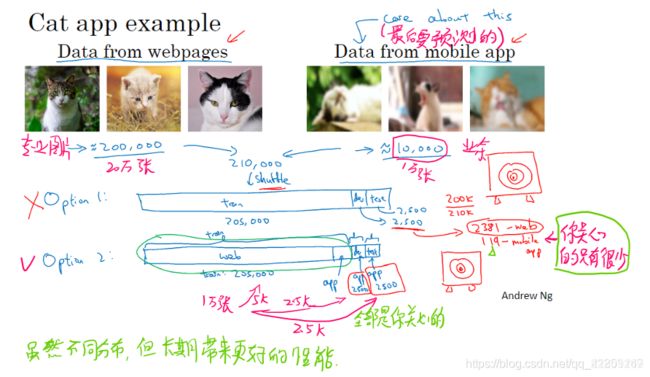
5. 数据分布不匹配时,偏差与方差的分析
如果 训练数据 和 开发数据 来自不同的分布,特别是,也许算法在训练集上做得不错,可能因为训练集 很容易识别(高分辨率,清晰的图像),但开发集 难以识别得多。

所以也许 开发集 增加的 9%误差,没有方差问题,只反映了 开发集 包含更难准确分类的图片。
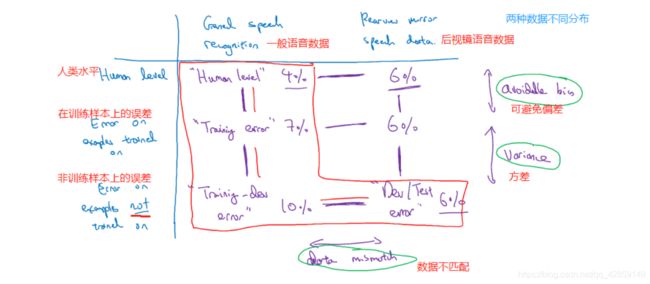
当你看 训练误差,再看 开发误差,有两件事变了:
- 算法只见过训练集数据,没见过 开发集数据
- 开发集 数据来自不同的分布
你同时改变了两件事情,很难确认这增加的 9%误差,有多少是因为算法没看到开发集中的数据导致的,这是问题方差的部分,有多少是因为开发集数据就是不一样
为了分辨清楚两个因素的影响,定义一组新的数据,称之为训练-开发集,它是从 训练集 的分布里随机分出来的,但不用来训练
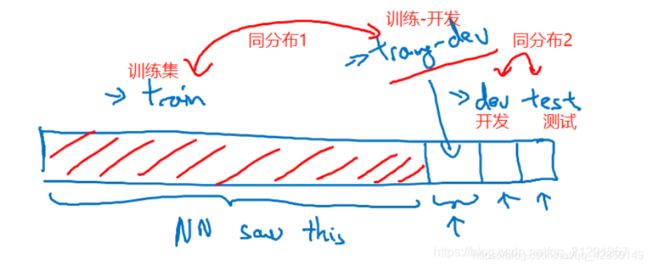

case A:
-
训练误差 & 训练-开发误差,差距 8 %,但是两者数据是同分布的,所以问题是泛化性能差,高方差问题
case B: -
训练误差 & 训练-开发误差,差距 0.5 %,方差问题很小,但是在 开发集 上误差为 10%,训练-开发集 & 开发集 上的数据,模型都没有在上面训练过,由于他们是不同分布,模型擅长前者,而你关心的开发集,模型表现不好,这称之为数据不匹配


本节总结:
使用来自 和开发集、测试集 不同分布的 训练数据,这可以提供更多训练数据,有助于提高算法性能,但是,潜在问题就不只是 偏差 和 方差 问题,引入了 数据不匹配 问题
没有特别系统的方法去解决数据不匹配问题,但可以做一些尝试,见下节
6. 定位数据不匹配问题
发现有严重的数据不匹配,亲自做误差分析,了解 训练集 和 开发集 / 测试集 的具体差异
为了避免对 测试集 过拟合,要做误差分析,应该人工去看 开发集 而不是 测试集
举例:
开发一个语音激活的后视镜应用,你可能要听一下 开发集 的样本,弄清楚 开发集 和 训练集 有什么不同:
- 比如,发现很多开发集样本汽车噪音很多
- 比如,后视镜经常识别错误街道号码
你意识到,开发集有可能跟训练集不同或者更难识别:
- 那么你可以尝试把训练数据变得更像开发集一点,
- 也可以收集更多类似你的开发集和测试集的数据。
所以,如果你发现车辆背景噪音是主要误差来源,那么你可以模拟车辆噪声数据;
或者你发现很难识别街道号码,你可以有意识地收集更多人们说数字的音频数据,加到你的训练集里
如果你的目标是让训练数据更接近开发集,怎么做呢?
人工合成数据(artificial data synthesis)(干净的语音+汽车背景噪声)
人工数据合成有一个潜在问题:
比如说,你在安静的背景里录得 10000小时 音频数据,你只录了 1 小时 车辆背景噪音,将这 1小时 汽车噪音循环放 10000次,并叠加到上面的语音
- 人听起来,这个音频没什么问题
- 但是有一个风险,有可能你的学习算法对这1小时汽车噪音过拟合,你只录了1小时汽车噪音,只模拟了全部数据空间的一小部分(噪声过于单一),所以找 10000 小时不同的噪声叠加在音频上是合理的
7. 迁移学习 Transfer learning
有时候神经网络可以从一个任务中学习知识,并将这些知识应用到另一个独立的任务中。
例如,已经训练好一个神经网络识别猫,然后使用那些知识或部分知识去帮助您更好地阅读x射线扫描图,这就是所谓的迁移学习
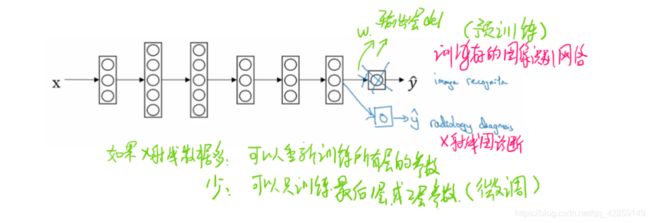
把图像识别中学到的知识迁移到放射科诊断上来,为什么有效果?
- 有很多低层次特征,比如边缘检测、曲线检测、阳性对象检测(positive objects),模型从非常大的图像识别数据库中学到了很多结构信息,图像形状的信息,学到线条、点、曲线这些知识,这些知识有可能帮助你的放射科诊断模型学习更快一些,或者需要更少的学习数据
迁移学习什么时候是有意义的呢?
- 在迁移来源问题中有很多数据,但迁移目标问题没有那么多数据。(例如:你有100万张图像识别数据,而只有100张X射线图像)
- 数据量如果反过来了,迁移学习可能就没有意义了(没有太大的帮助)
- 迁移学习确实可以显著提高你的学习任务的性能
8. 多任务学习 Multi-task learning
无人驾驶车的例子,图片中你要检测很多对象(人,车,交通灯,停车标志等等),那么输出标签是多个标签。即建立单个神经网络,模型告诉你,每张图里面有没有这四个物体。
那么损失函数为:
1 m ∑ i = 1 m ∑ j = 1 4 L ( y ^ j ( i ) , y j ( i ) ) \frac{1}{m} \sum_{i=1}^{m} \sum_{j=1}^{4} L\left(\hat{y}_{j}^{(i)}, y_{j}^{(i)}\right) m1i=1∑mj=1∑4L(y^j(i),yj(i))
也可以训练四个不同的神经网络,而不是训练一个网络做四件事情。但神经网络系统得一些早期特征试图告诉我们,训练一个神经网络做四件事情 比 训练四个完全独立的神经网络分别做四件事,性能要更好
另外,多任务学习也可以处理图像只有部分物体被标记的情况。
比如有的图片有人,但是没有加人的标签,还有一些是问号,但是没关系,算法依然可以在上面进行训练(求和的时候会忽略问号)
多任务学习什么时候有意义?
- 训练任务可以共用低层次特征
- 单项任务可以从多任务学习得到很大性能提升,前提:其他任务数据总量加起来必须比单个任务的数据量大的多
- 训练一个足够大的神经网络,多任务学习肯定不会或者很少会降低性能,比单独训练神经网络来单独完成各个任务性能要更好
实践中,多任务学习 的使用频率要低于 迁移学习计算机视觉
一个例外是物体检测,人们经常训练一个神经网络同时检测很多不同物体,这比训练单独的神经网络来检测视觉物体要更好
9. 什么是端到端的深度学习
以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理。那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。它需要很多的数据来训练,才可能有好的效果。
端到端深度学习系统是可行的,它表现可以很好(例如,机器翻译),也可以简化系统架构,让你不需要搭建那么多手工设计的单独组件,但它并不是每次都能成功(从X射线照片判断年龄)
10. 是否要使用端到端的深度学习其优点
其优点:
- 让数据自己说话,没有人为的加入各种规则
- 更少的手工设计,简化工作流程
其缺点:
- 有可能排除了有用的手工设计组件,精心设计的人工组件可能非常有用,但它们也有可能真的降低算法的性能(数据量很大的时候,人工组件可能降低算法性能)
是否使用?
- 你有足够多的数据吗,去学习一个复杂的映射函数关系
- 机器性能
老师认为:纯粹的端到端深度学习方法,前景不如更复杂的多步方法(比如人脸识别,人脸每次的位置是变化的,先识别出有人脸,然后把人脸区域截取出来,再对其进行预测,分步进行)。因为目前能收集到的数据,还有我们现在训练神经网络的能力是有局限的